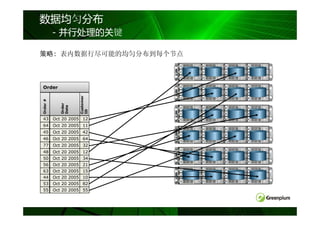
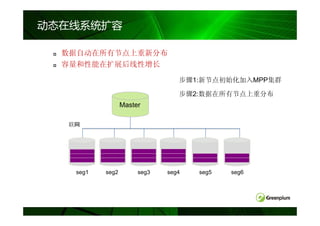
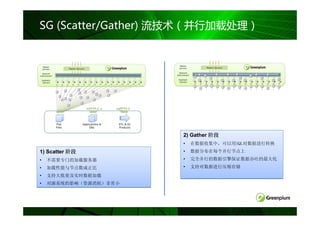
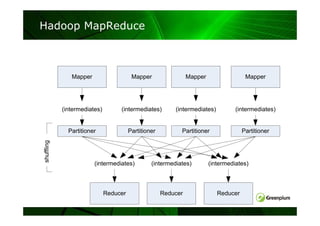
数据均匀分布
- 并行处理的关键
策略:
策略: 表内数据行尽可能的均匀分布到每个节点
Order
Customer
Order #
Order
Date
ID
43 Oct 20 2005 12
64 Oct 20 2005 11
45 Oct 20 2005 42
46 Oct 20 2005 64
77 Oct 20 2005 32
48 Oct 20 2005 12
50 Oct 20 2005 34
56 Oct 20 2005 21
63 Oct 20 2005 15
44 Oct 20 2005 10
53 Oct 20 2005 82
55 Oct 20 2005 55
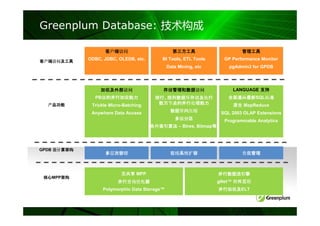
8.
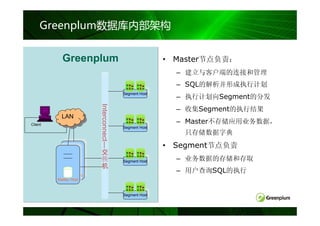
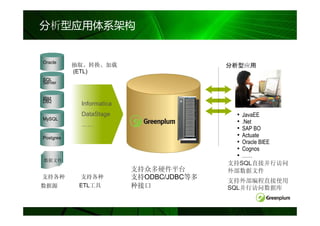
数据分布方法
• 哈希分布
– CREATE TABLE … DISTRIBUTED BY (column
[,…])
– 哈希值相同的记录在同一个Segment节点
• 随机分布
– CREATE TABLE … DISTRIBUTED RANDOMLY
– Rows with columns of the same value not
necessarily on the same segment
9.
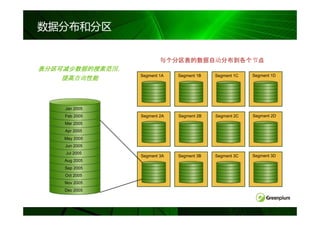
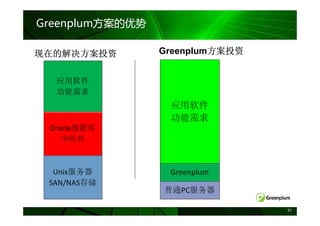
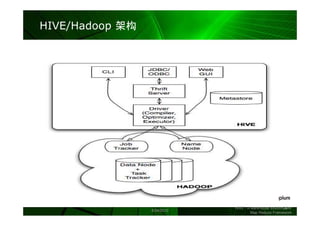
数据分布和分区
每个分区表的数据自动分布到各个节点
个分区表的数据自动分布到各个节
表分区可减少数据的搜索范围
表分区可减少数据的搜索范围,
Segment 1A Segment 1B Segment 1C Segment 1D
提高查询
查询性能
提高查询性能
Jan 2005
Feb 2005 Segment 2A Segment 2B Segment 2C Segment 2D
Mar 2005
Apr 2005
May 2005
Jun 2005
Jul 2005
Segment 3A Segment 3B Segment 3C Segment 3D
Aug 2005
Sep 2005
Oct 2005
Nov 2005
Dec 2005
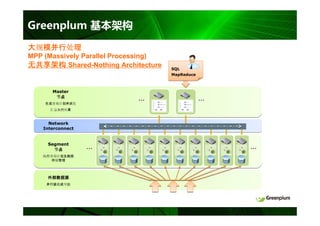
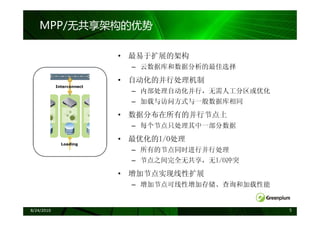
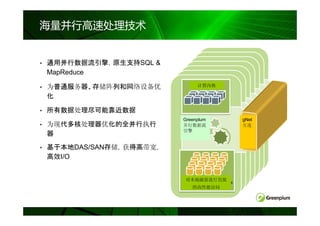
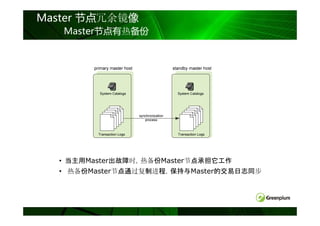
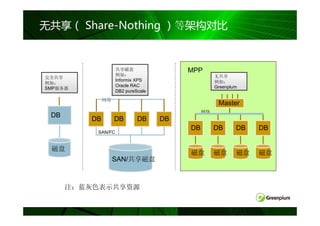
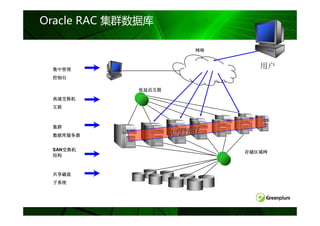
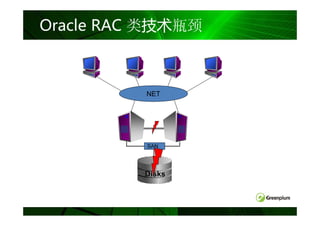
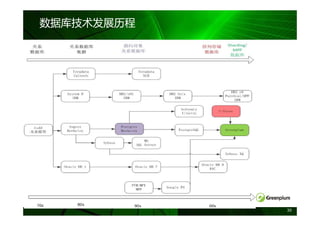
无共享( Share-Nothing )等架构对比
共享磁盘 MPP
例如: 无共享
完全共享
Informix XPS 例如:
例如:
Oracle RAC Greenplum
SMP服务器
DB2 pureScale
网络
Master
网络
DB
DB DB DB DB
DB DB DB DB
SAN/FC
磁盘
磁盘 磁盘 磁盘 磁盘
SAN/共享磁盘
注:蓝灰色表示共享资源
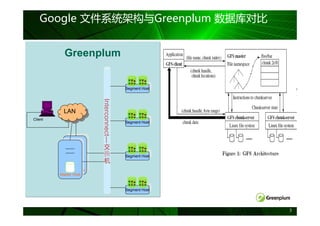
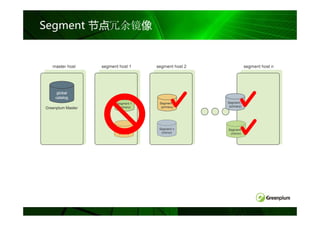
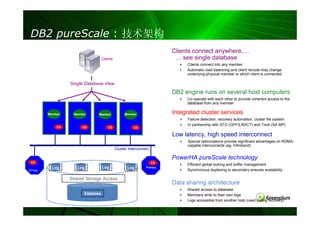
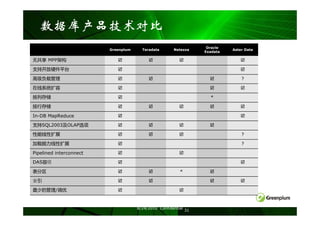
DB2 pureScale :技术架构
Clients connect anywhere,…
Clients … see single database
Clients connect into any member
Automatic load balancing and client reroute may change
underlying physical member to which client is connected
Single Database View
DB2 engine runs on several host computers
Co-operate with each other to provide coherent access to the
database from any member
Member Member Member Member Integrated cluster services
Failure detection, recovery automation, cluster file system
In partnership with STG (GPFS,RSCT) and Tivoli (SA MP)
CS CS CS CS
Low latency, high speed interconnect
Special optimizations provide significant advantages on RDMA-
capable interconnects (eg. Infiniband)
Cluster Interconnect
PowerHA pureScale technology
CS CS
Efficient global locking and buffer management
Log Log Log Log Primary
2nd-ary Synchronous duplexing to secondary ensures availability
Shared Storage Access
Data sharing architecture
Shared access to database
Database Members write to their own logs
Logs accessible from another host (used during recovery)



![数据分布方法
• 哈希分布
– CREATE TABLE … DISTRIBUTED BY (column
[,…])
– 哈希值相同的记录在同一个Segment节点
• 随机分布
– CREATE TABLE … DISTRIBUTED RANDOMLY
– Rows with columns of the same value not
necessarily on the same segment](https://image.slidesharecdn.com/greenplum-120316234413-phpapp01/85/Greenplum-8-320.jpg)


































![[.Net开发交流会][2010.06.19]大众点评网的技术变迁之路(王宏)](https://cdn.slidesharecdn.com/ss_thumbnails/net2010-06-19-101007223315-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































