Downloaded 10 times






![[ Operations ] Continuous
Integration and Deployment
2012 9](https://image.slidesharecdn.com/kishorejalledanagiosintheagiledevopscontinuousdeploymentworld-121003152854-phpapp02/85/Nagios-Conference-2012-Kishore-Jalleda-Nagios-in-the-Agile-DevOps-Continuous-Deployment-World-9-320.jpg)

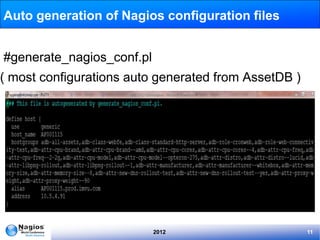

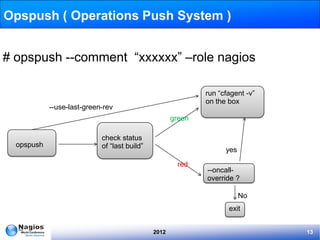
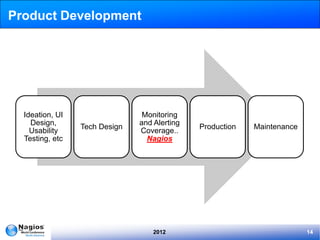




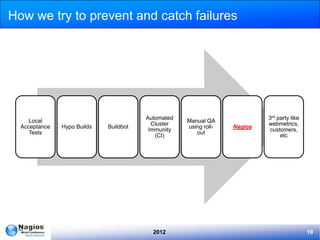
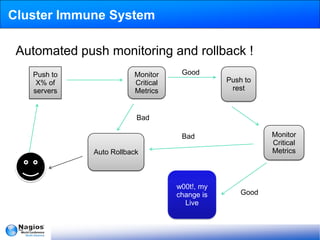
















The document discusses the implementation and management of Nagios within IMVU, highlighting its role in continuous deployment and DevOps culture. It outlines the features of IMVU's asset database, automation strategies for monitoring, and incident management practices including blameless postmortems. Recommendations for improving monitoring effectiveness, such as investing in configuration automation and predictive monitoring, are also provided.


































































