Download as PDF, PPTX

![Maris Elsins
Lead DatabaseConsultant
At Pythian since 2011
Located in Riga, Latvia
Oracle [Apps] DBA since 2005
Speaker at conferences since 2007
@MarisElsins elsins@pythian.com
http://bit.ly/getMOSPatch](https://image.slidesharecdn.com/ougf16-mariselsins-db12c-allyouneedtoknowabouttheresourcemanager-160519160219/75/DB12c-All-You-Need-to-Know-About-the-Resource-Manager-2-2048.jpg)

























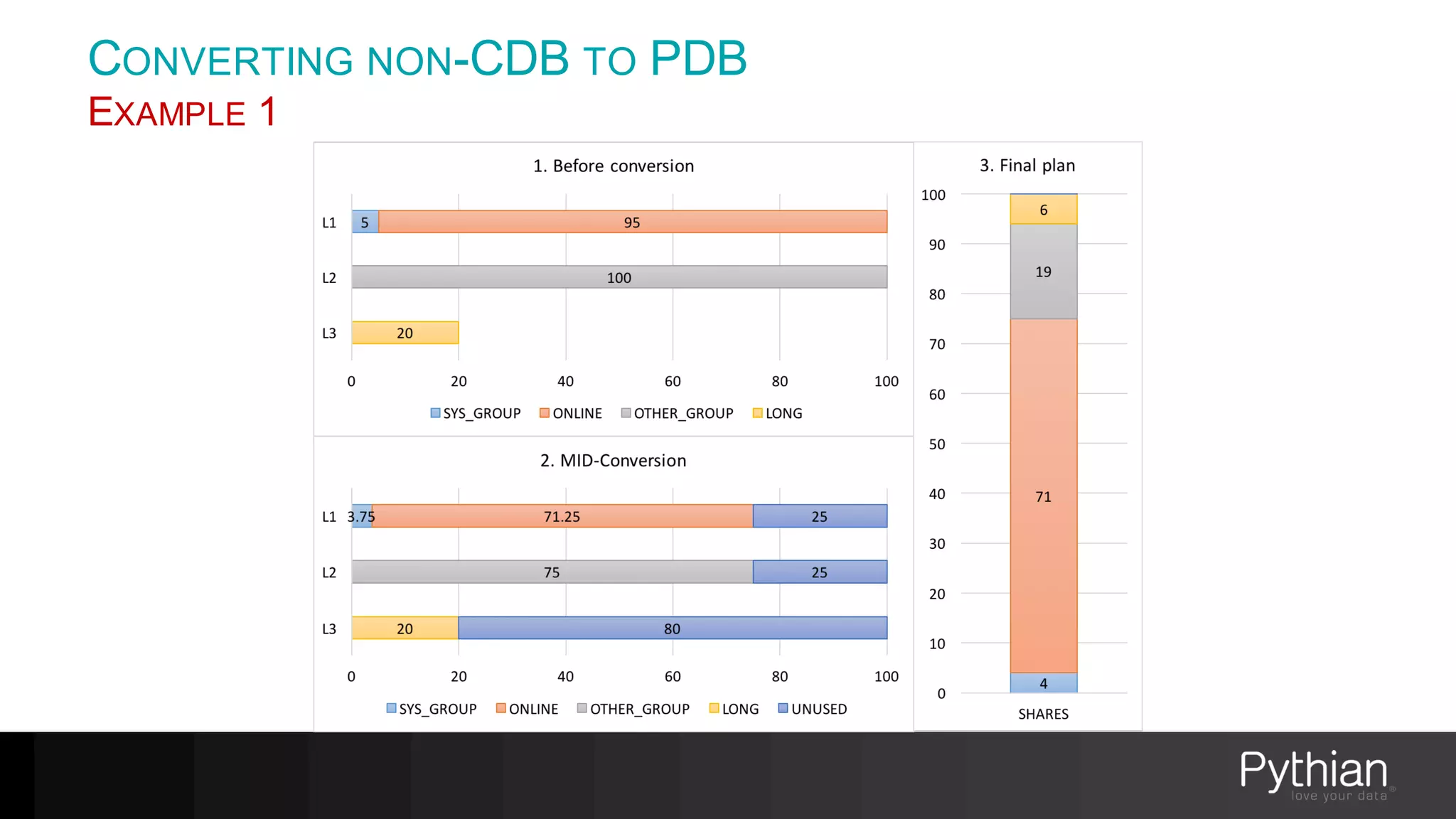
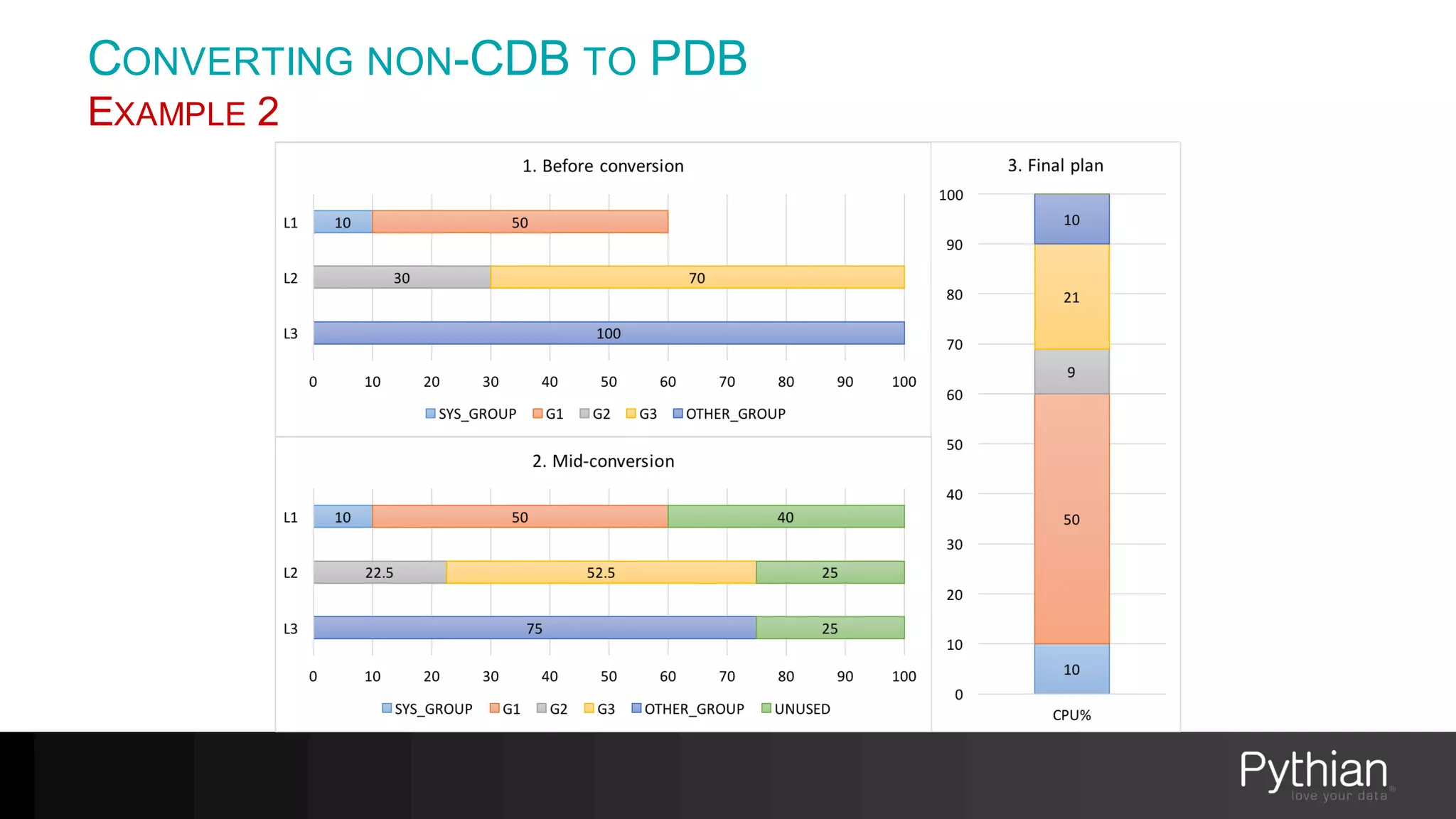
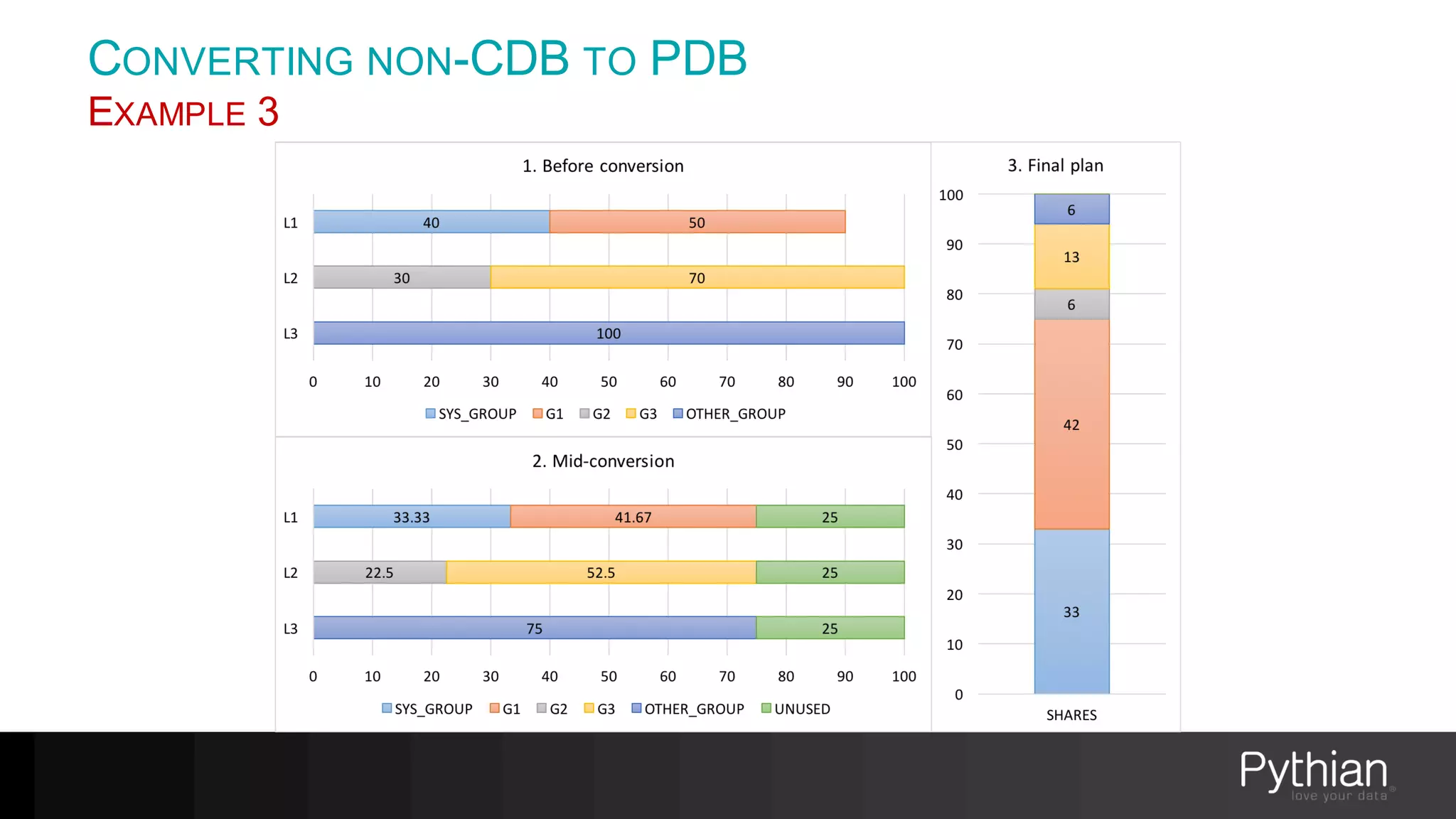





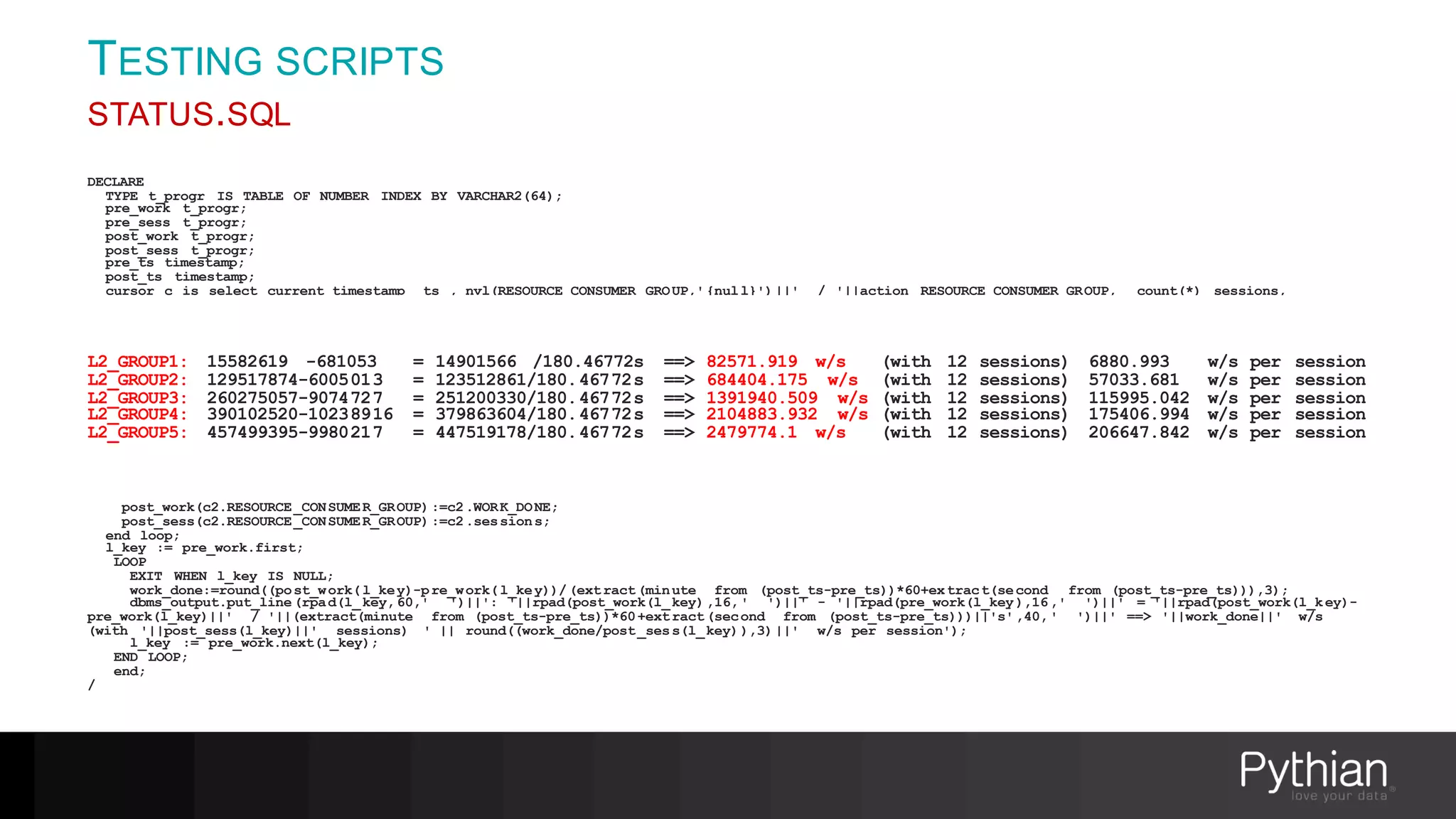






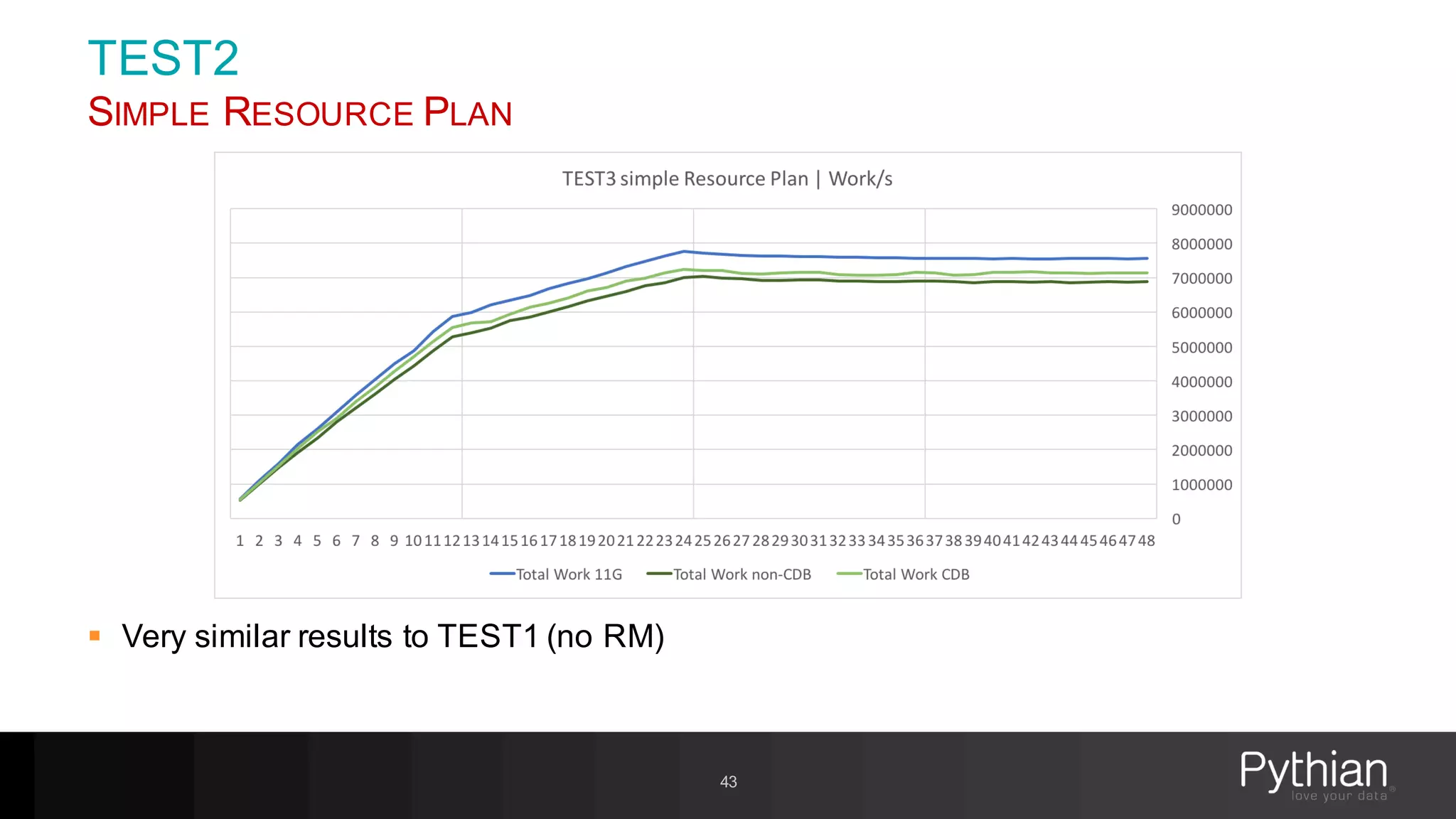
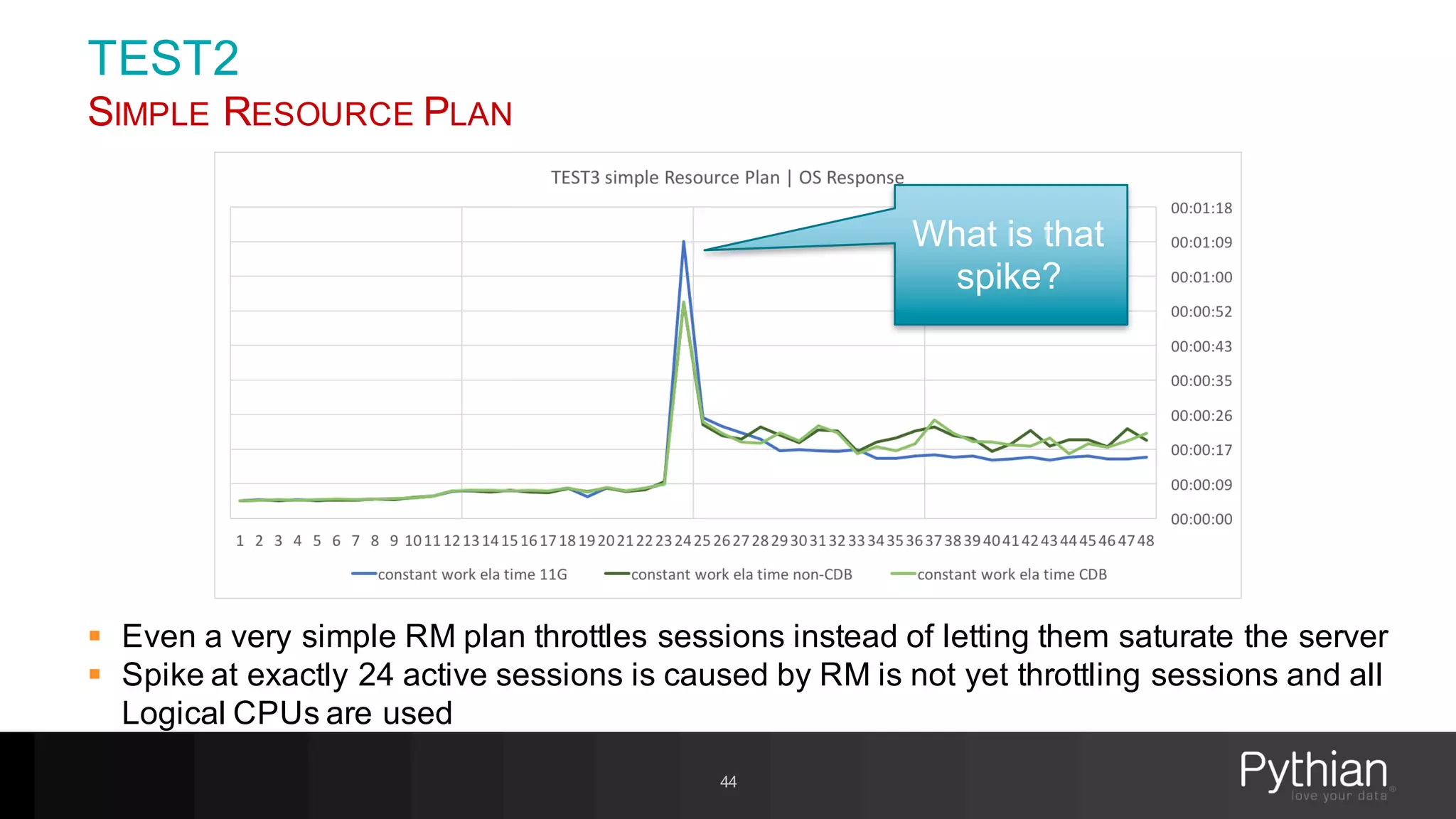

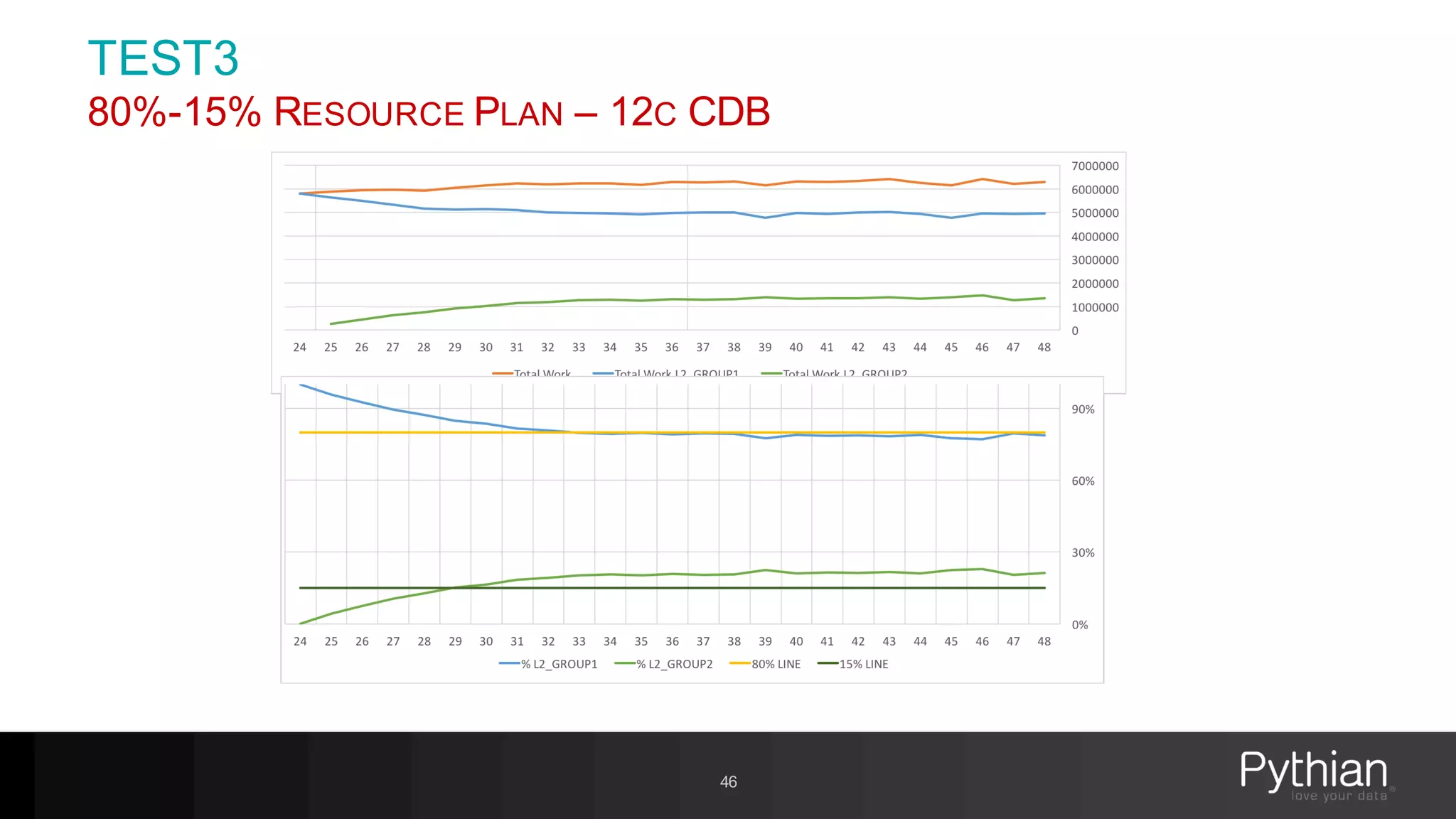



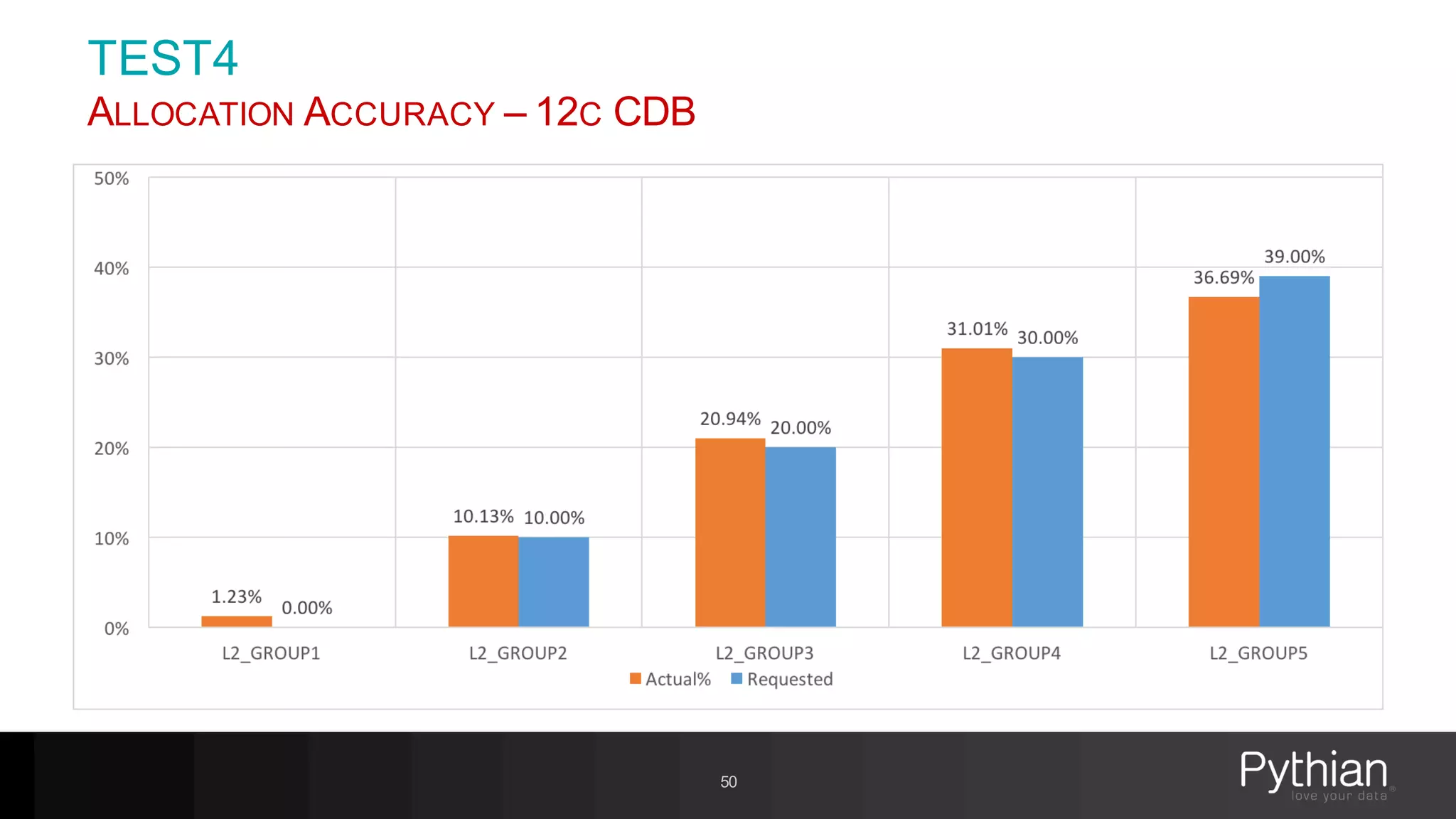

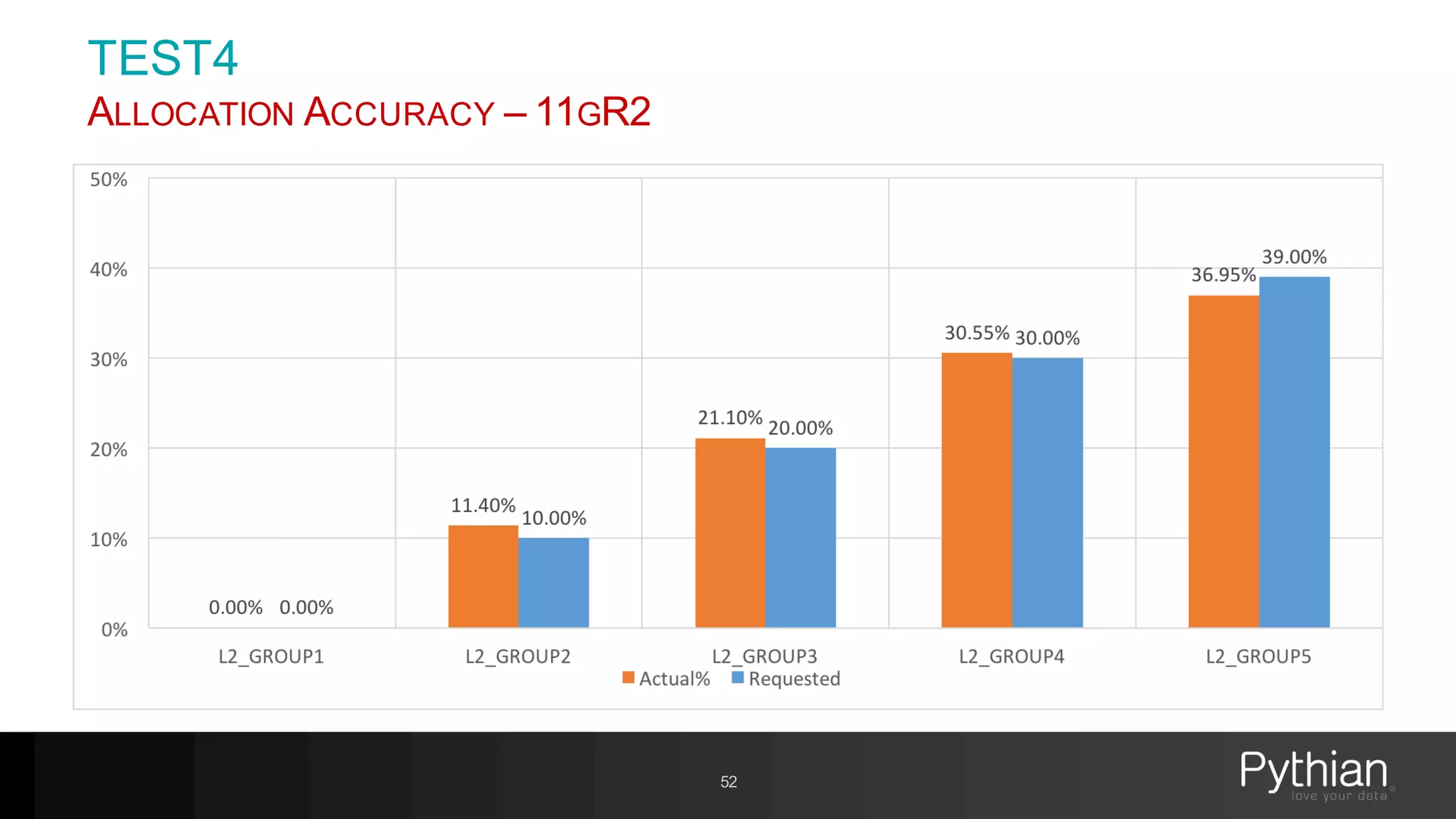

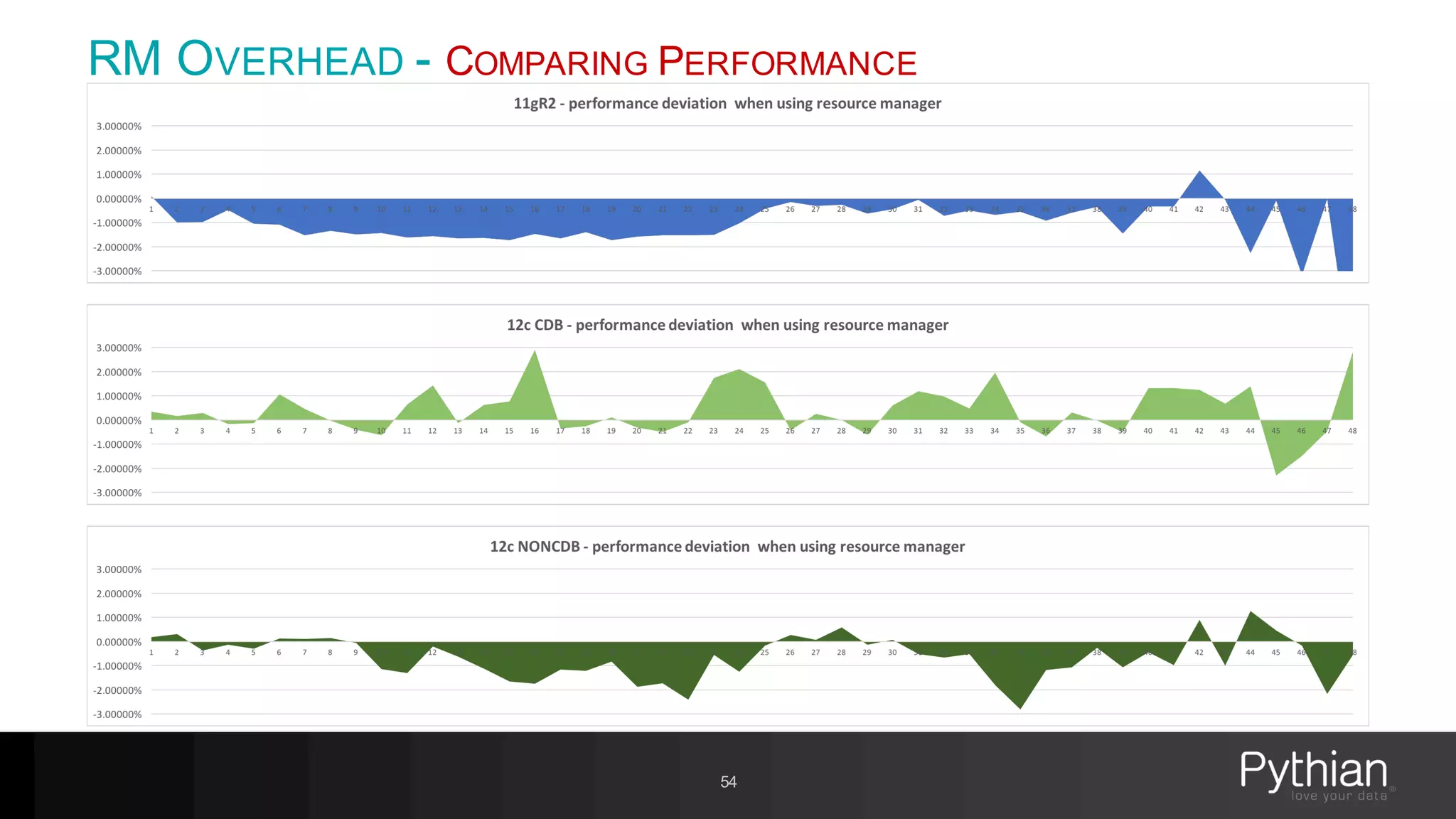




The document provides a comprehensive overview of Oracle's Resource Manager, detailing its features, functionalities, and improvements in the 12c version. It addresses issues like CPU resource allocation and management of workloads using consumer groups, along with troubleshooting scenarios and optimal configurations. Additionally, the presentation discusses the transition from non-CDB to CDB resource plans and the expected overhead associated with the Resource Manager.





















![【旧版】Oracle Gen 2 Exadata Cloud@Customer:サービス概要のご紹介 [2021年12月版]](https://cdn.slidesharecdn.com/ss_thumbnails/exadatacloudatcustomer20211208-211210071313-thumbnail.jpg?width=640&height=640&fit=bounds)




![【旧版】Oracle Database Cloud Service:サービス概要のご紹介 [2021年7月版]](https://cdn.slidesharecdn.com/ss_thumbnails/ocidatabaseoverview210709-210709093949-thumbnail.jpg?width=640&height=640&fit=bounds)

























































