Download as PDF, PPTX


















![SimplifyCFG: Switch to lookup table
switch (x) {
case 0:
return 10;
case 1:
return 42;
case 2:
return 123;
case 3:
return 7;
default:
return 13;
}
42
int table[] = {10, 42, 123, 7};
if (x < 4) {
return table[x];
} else {
return 13;
}](https://image.slidesharecdn.com/awhirlwindtourofthellvmoptimizer-230510155843-c30751d5/75/A-whirlwind-tour-of-the-LLVM-optimizer-42-2048.jpg)
















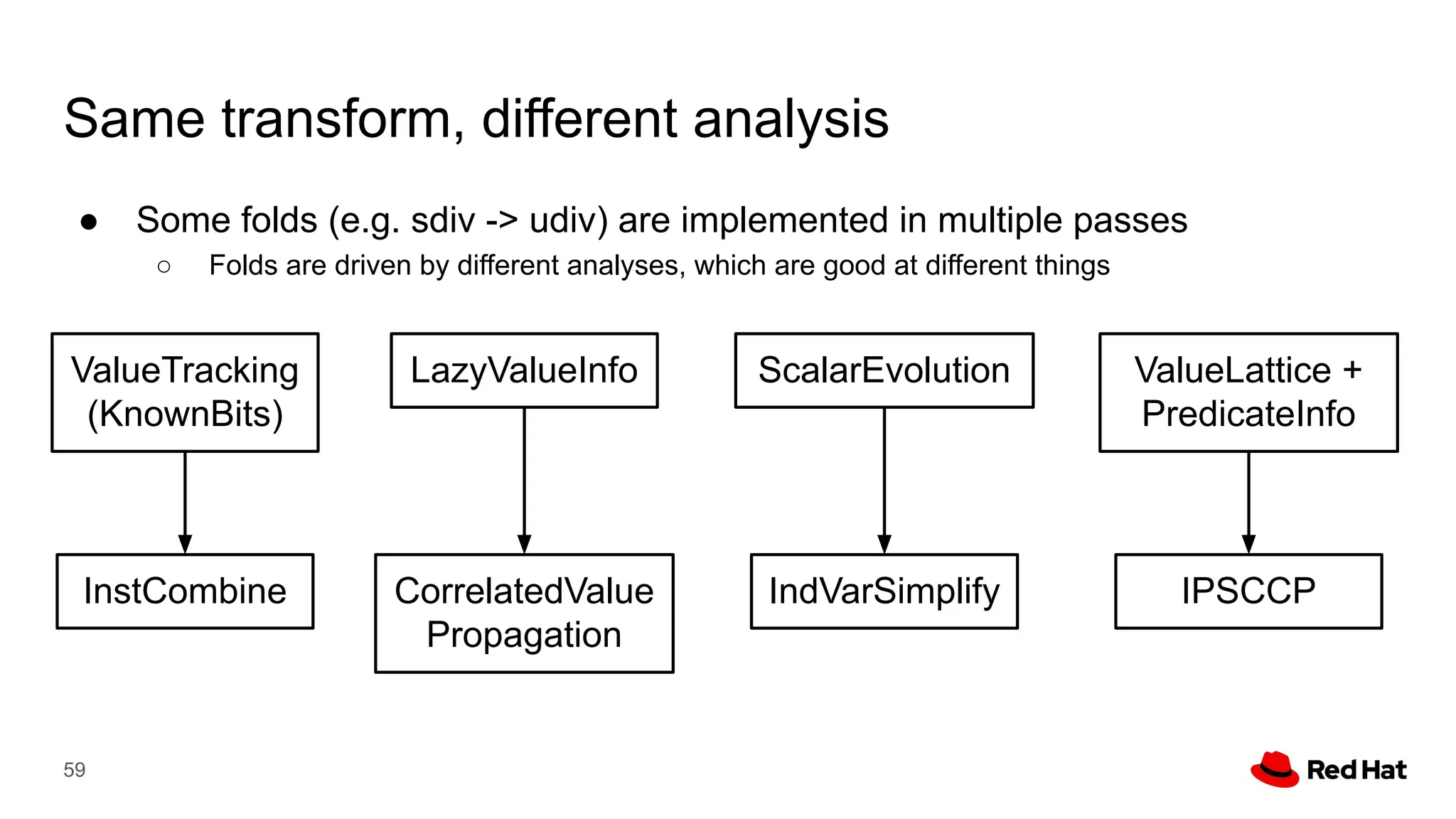



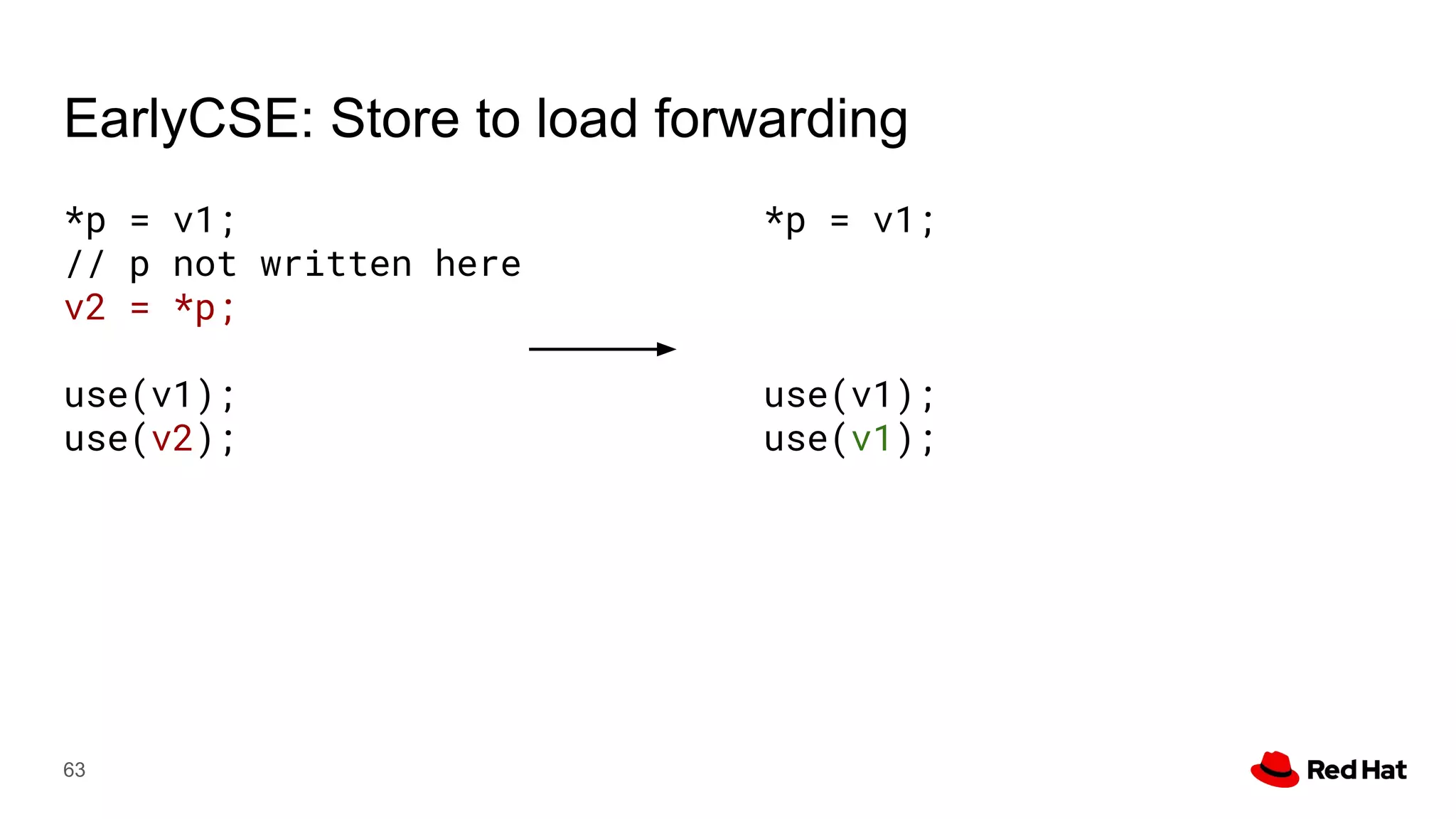

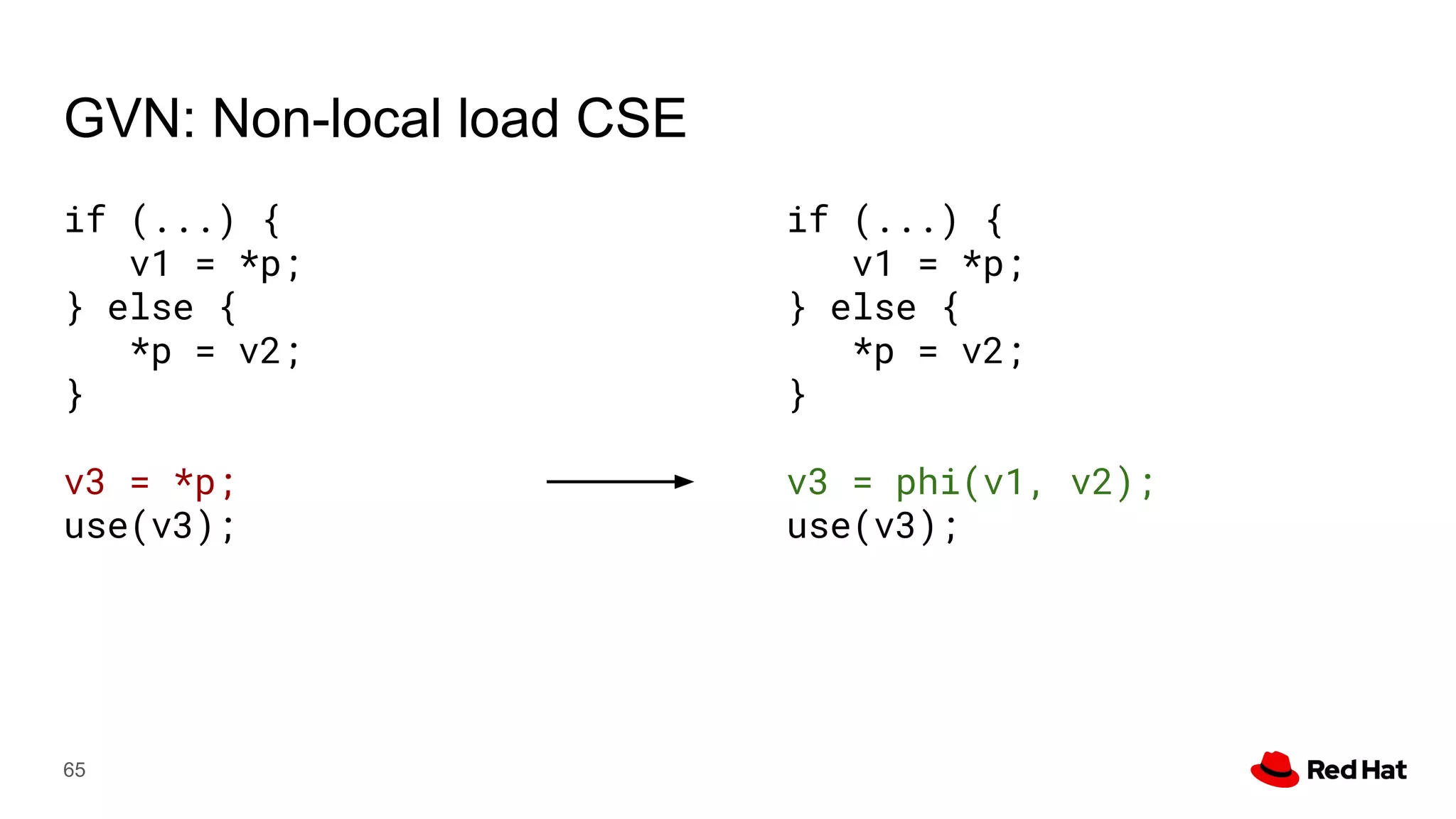







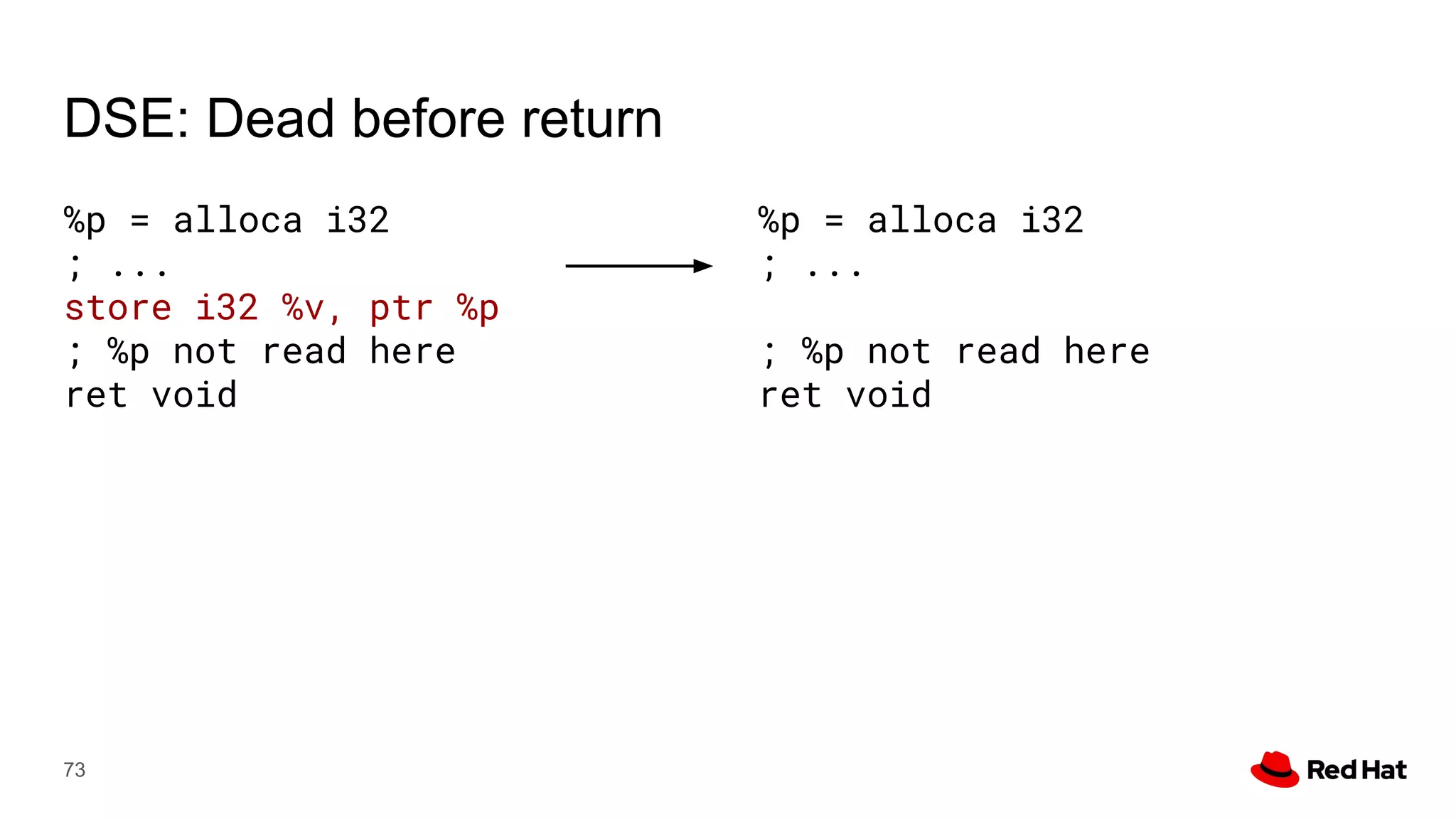


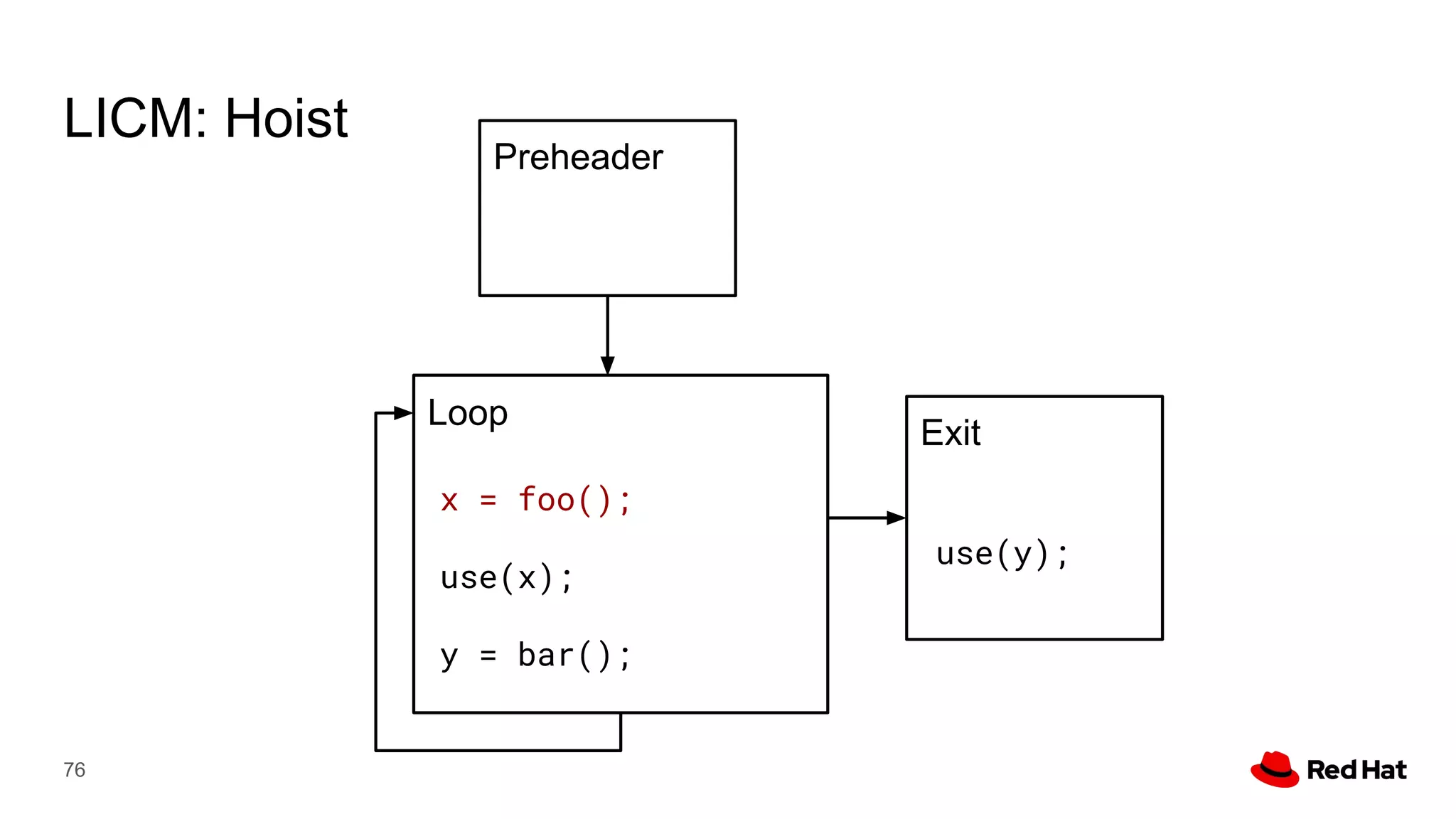
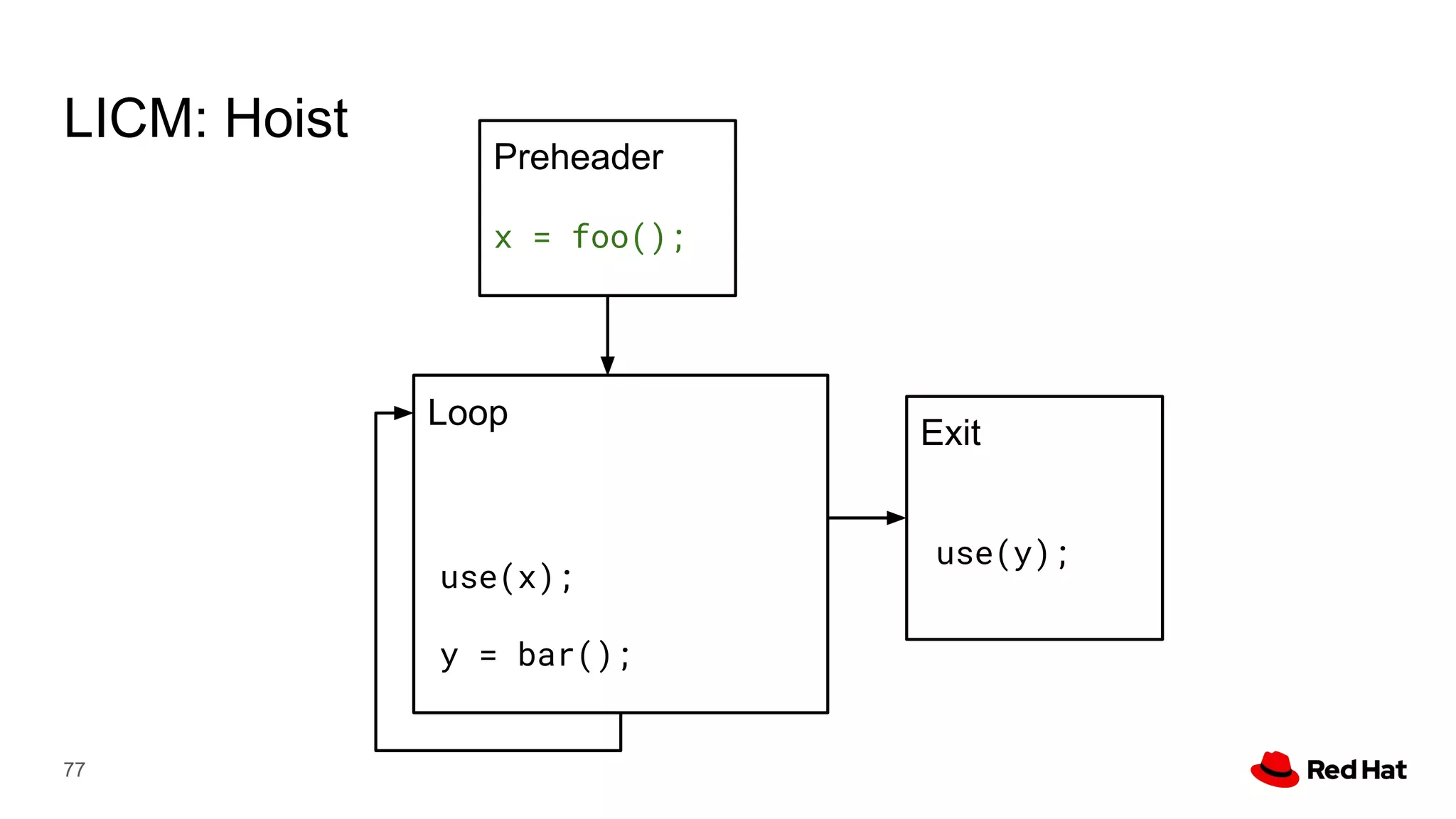
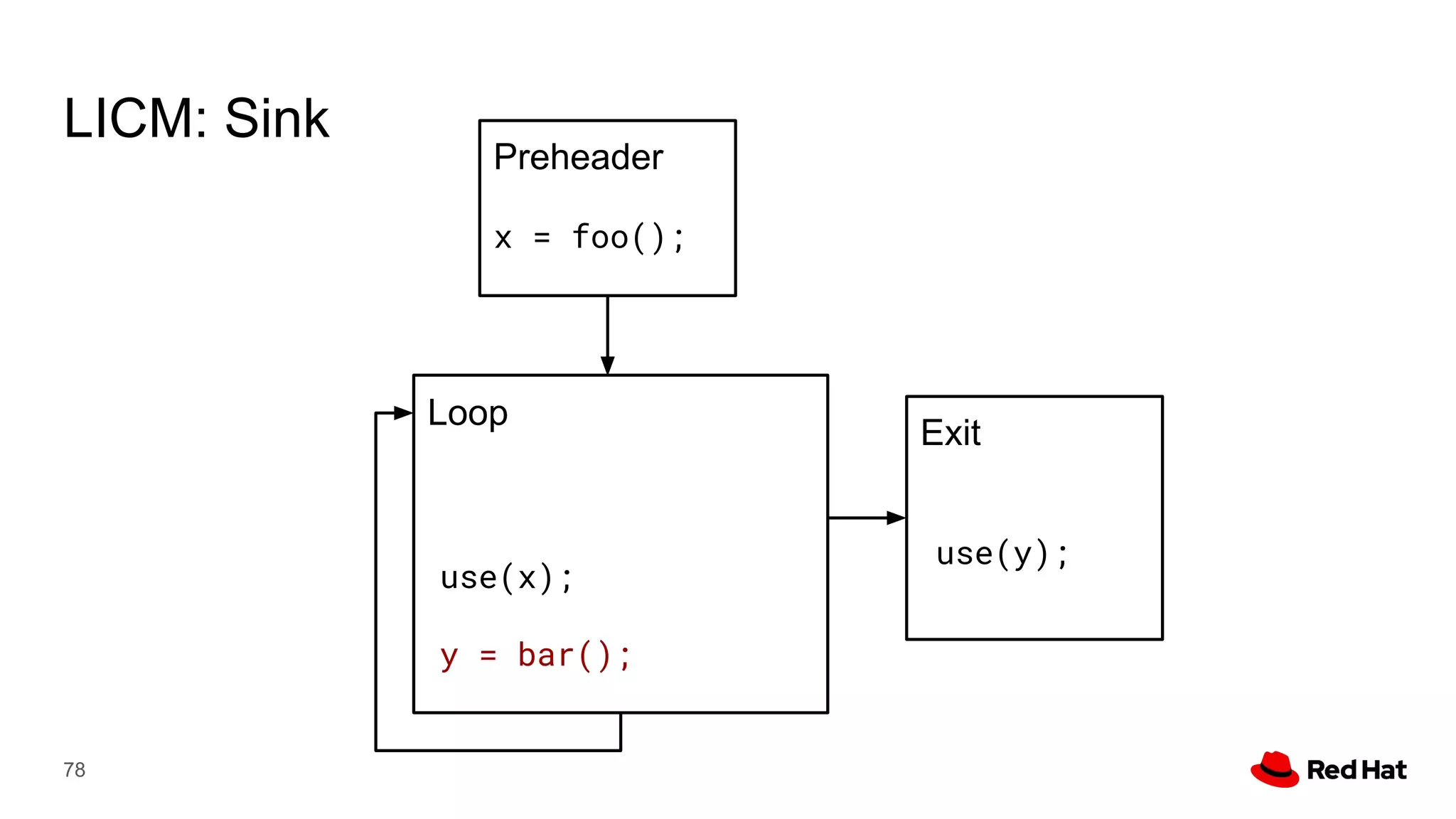
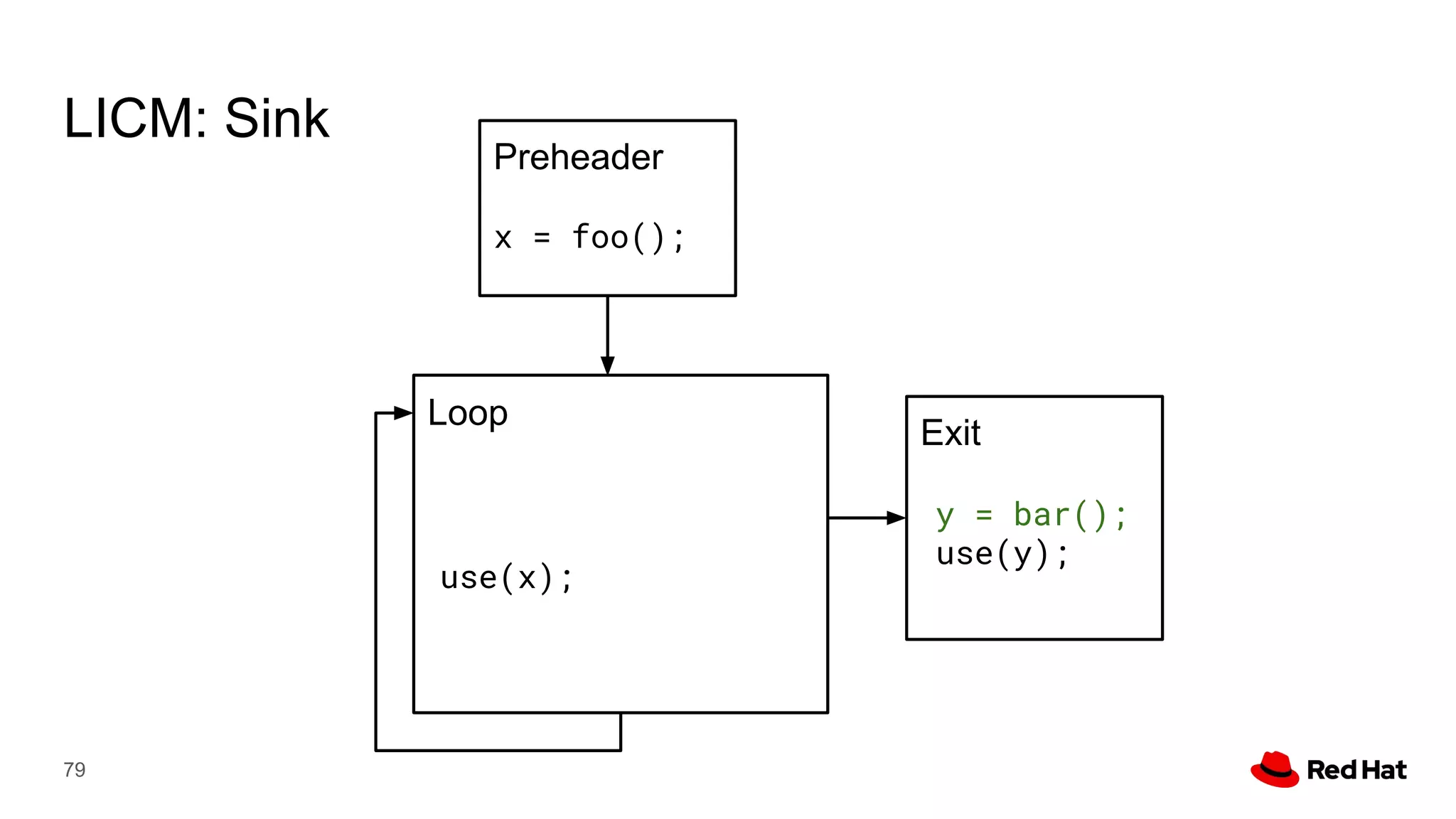
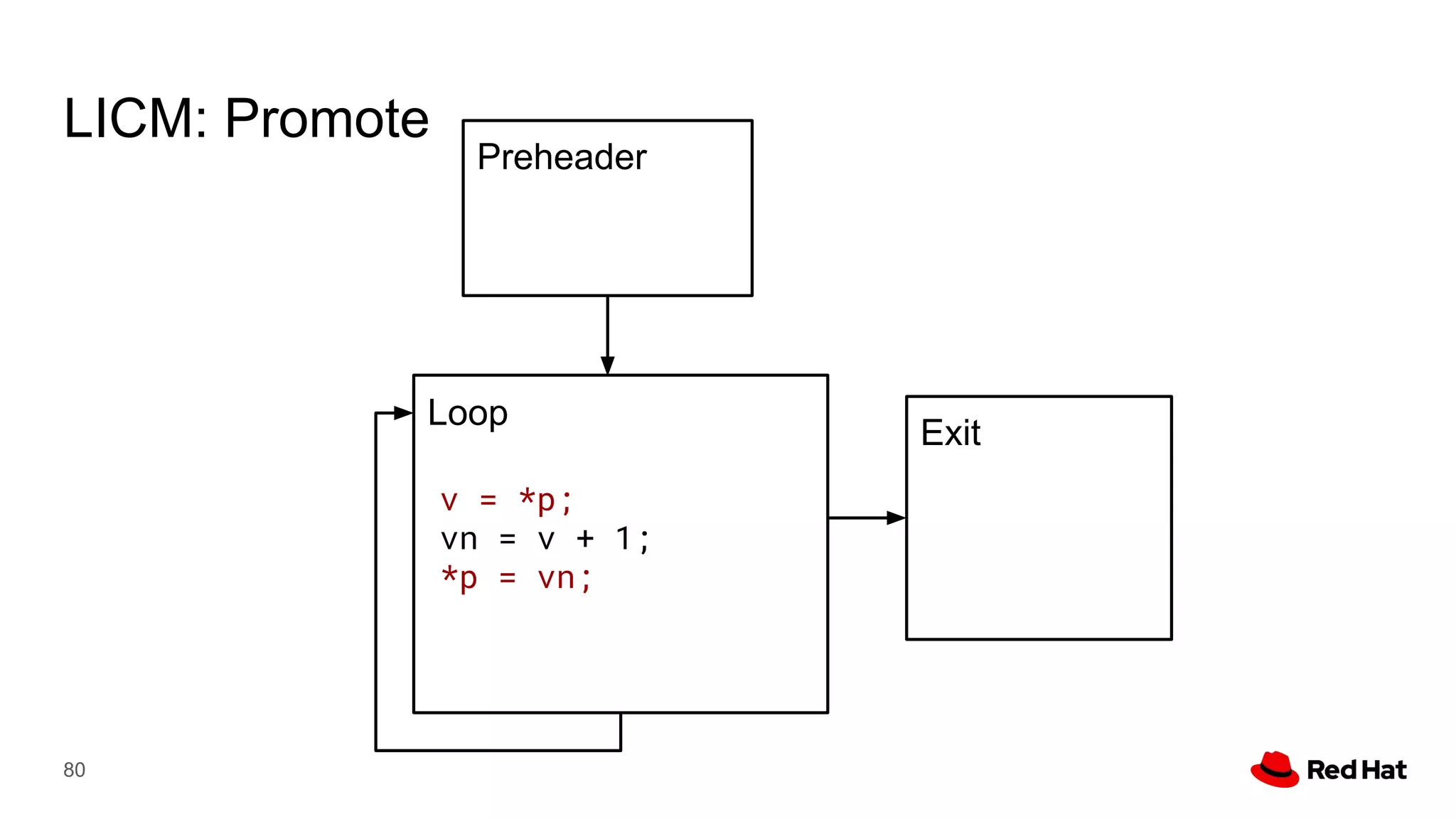





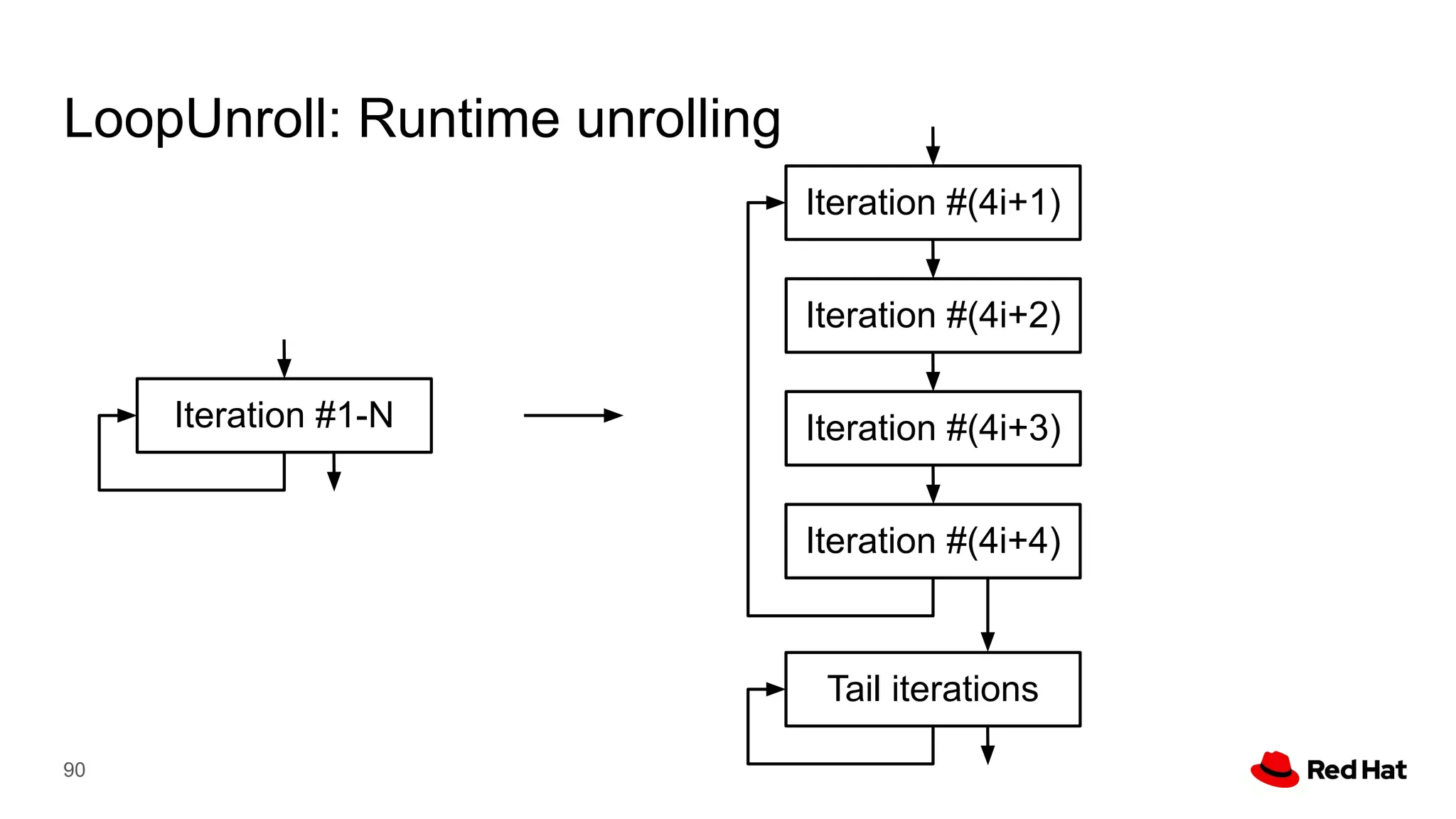
















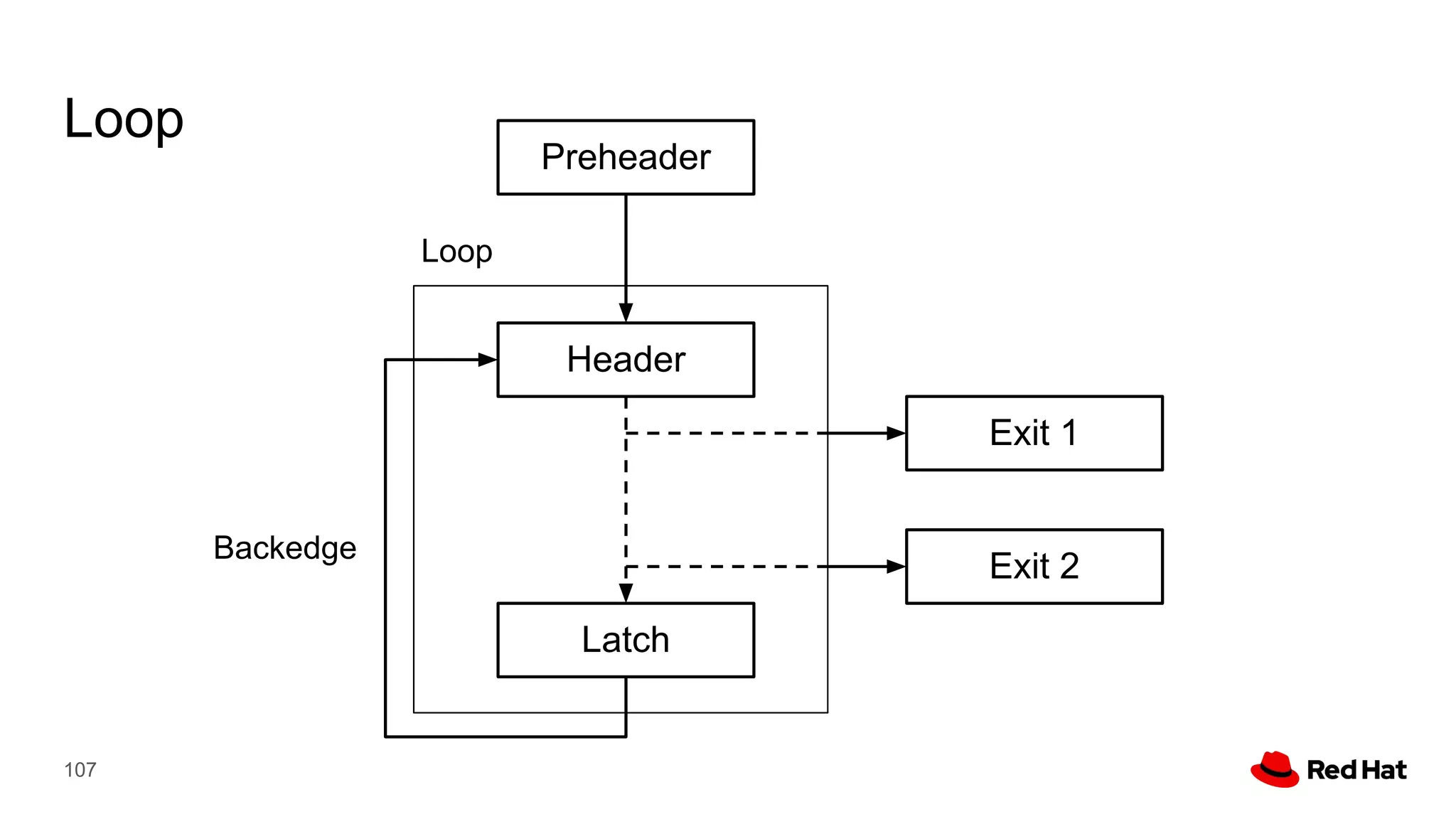
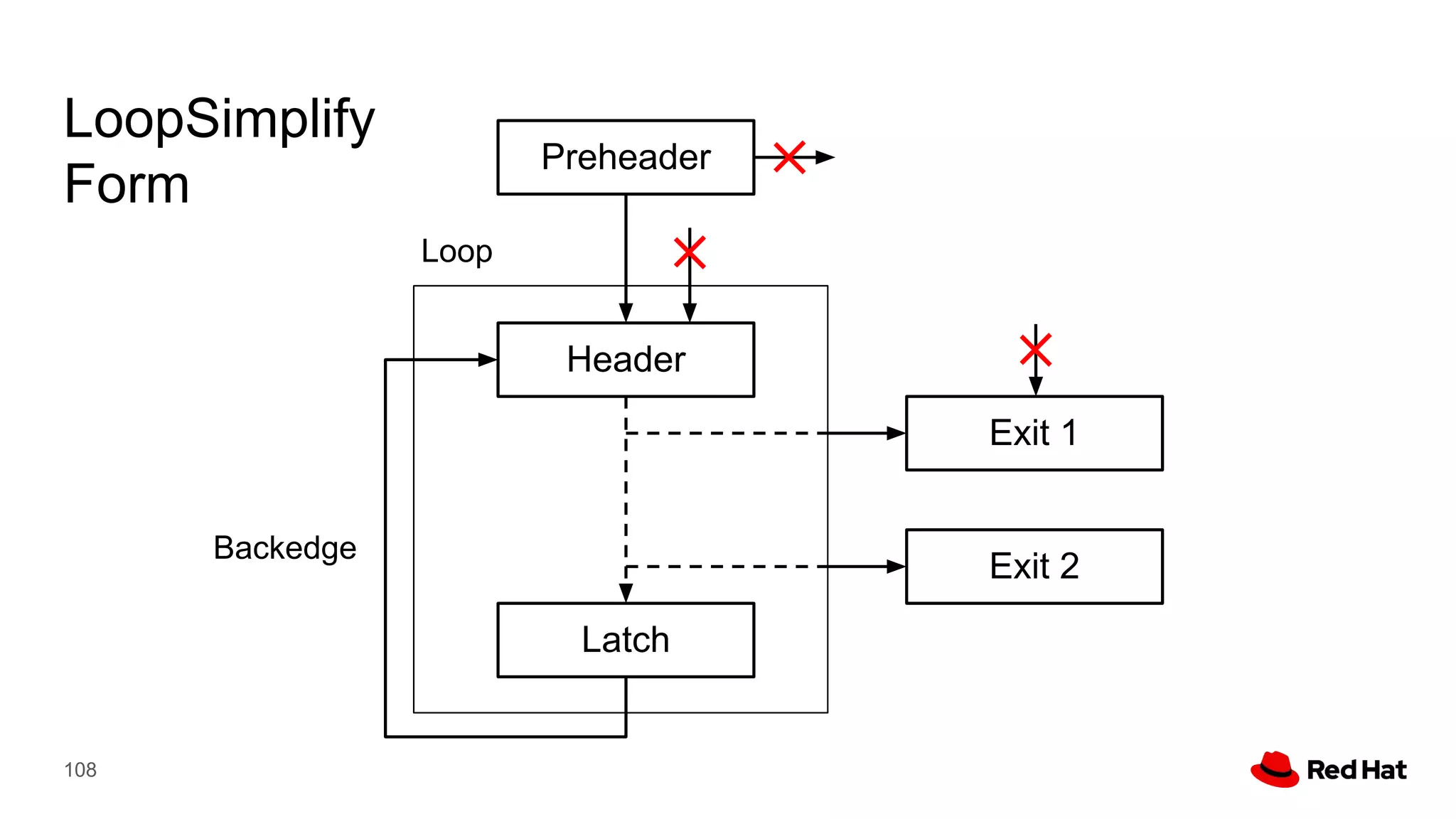
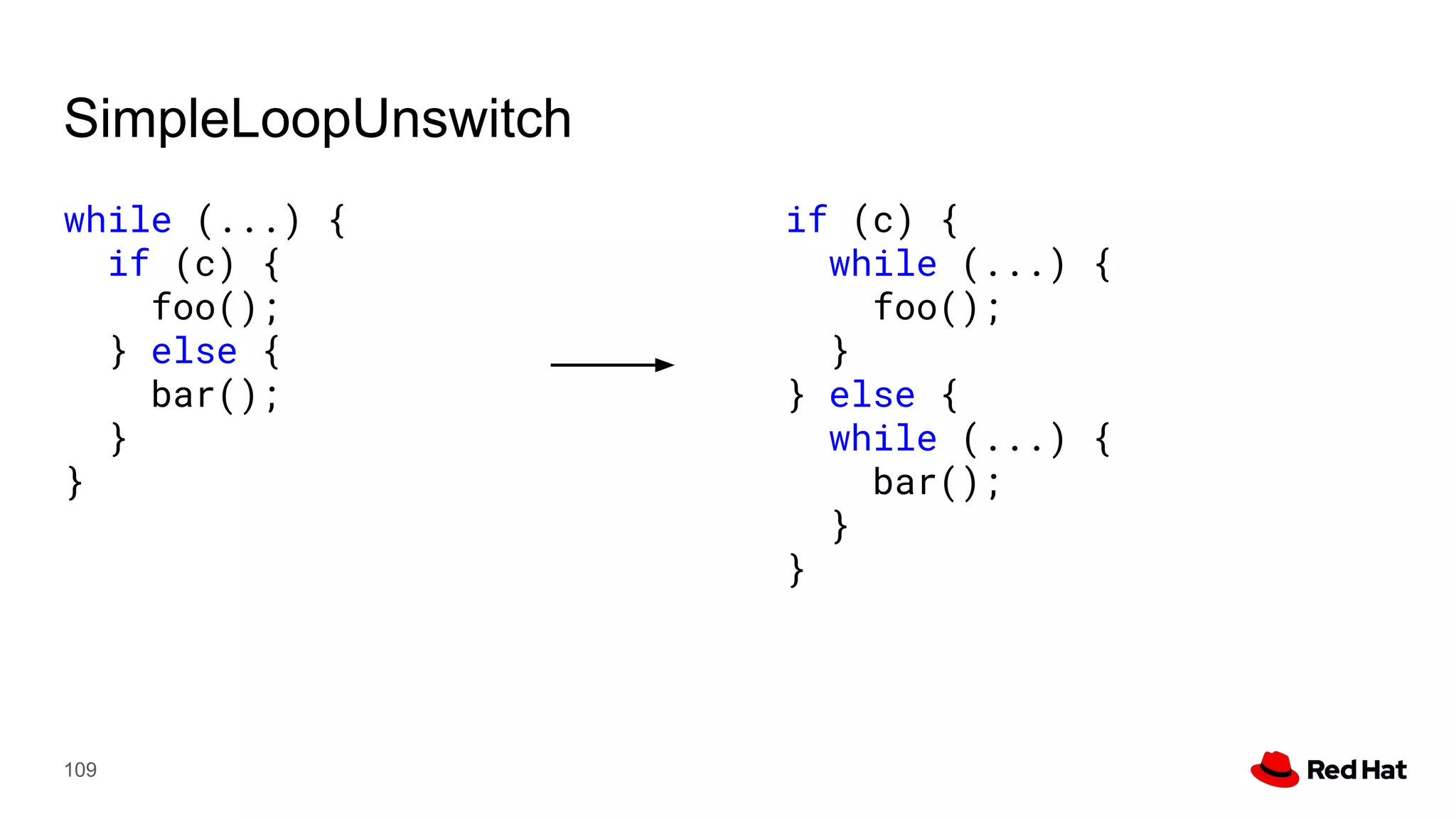

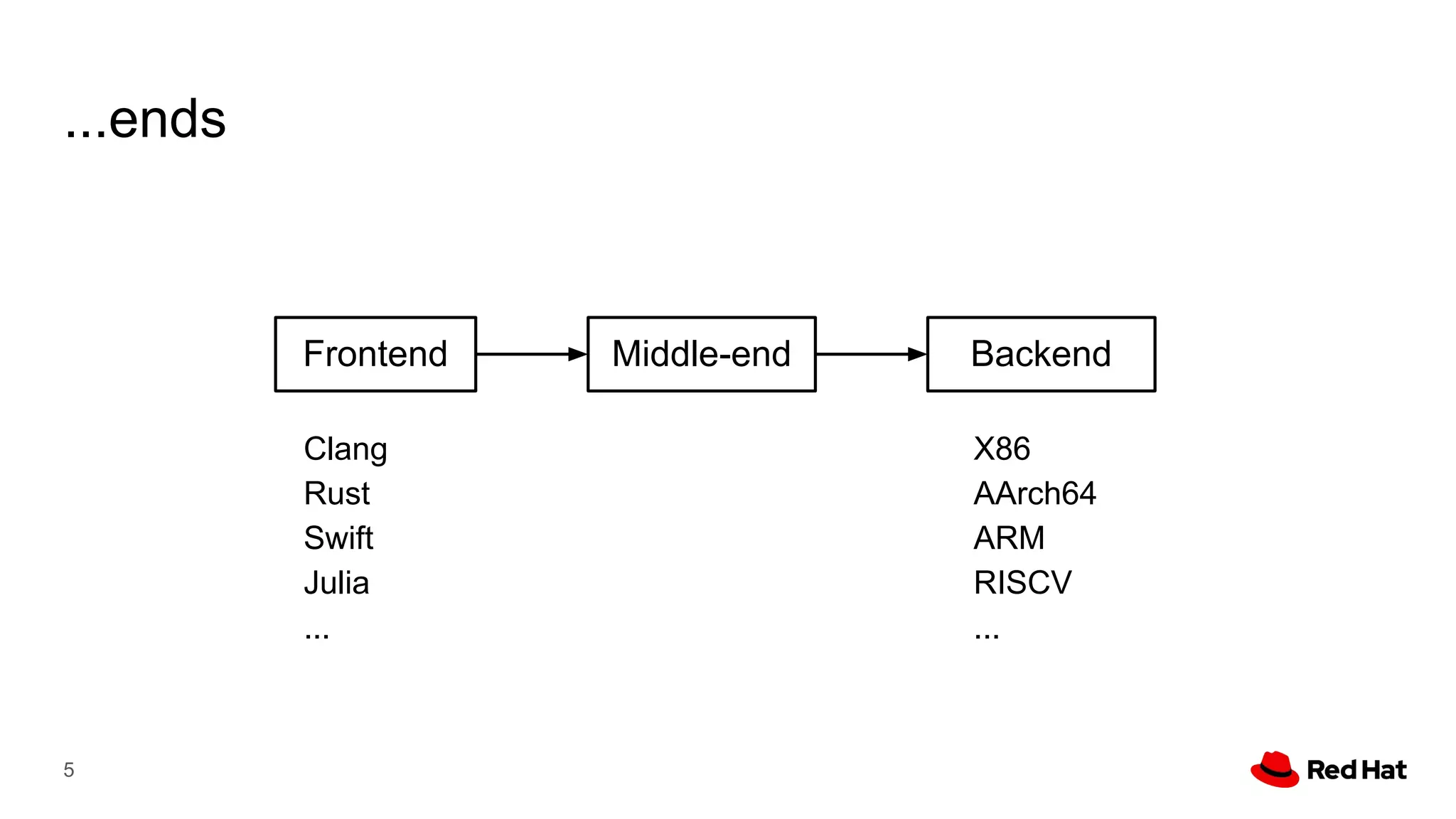
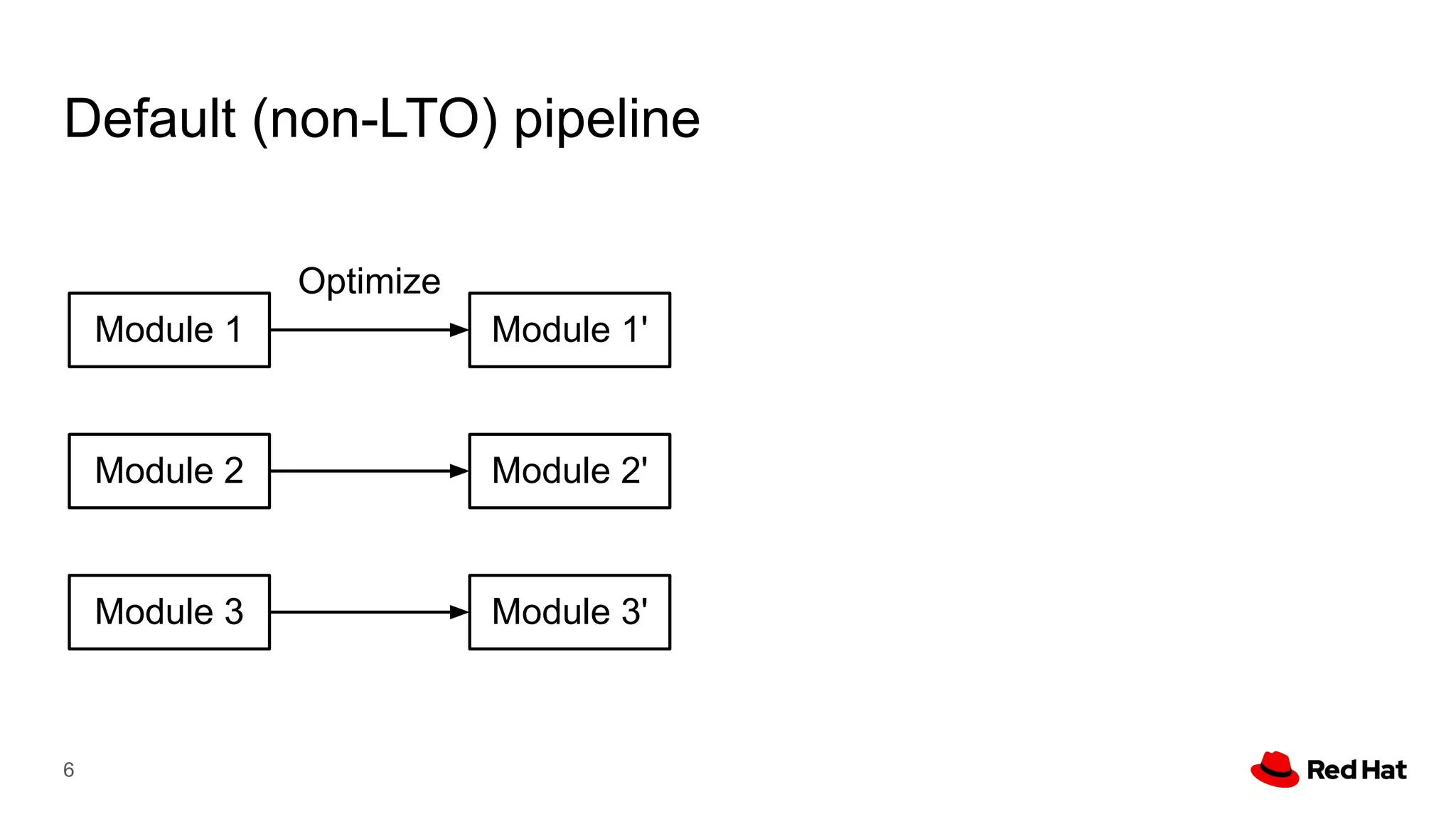
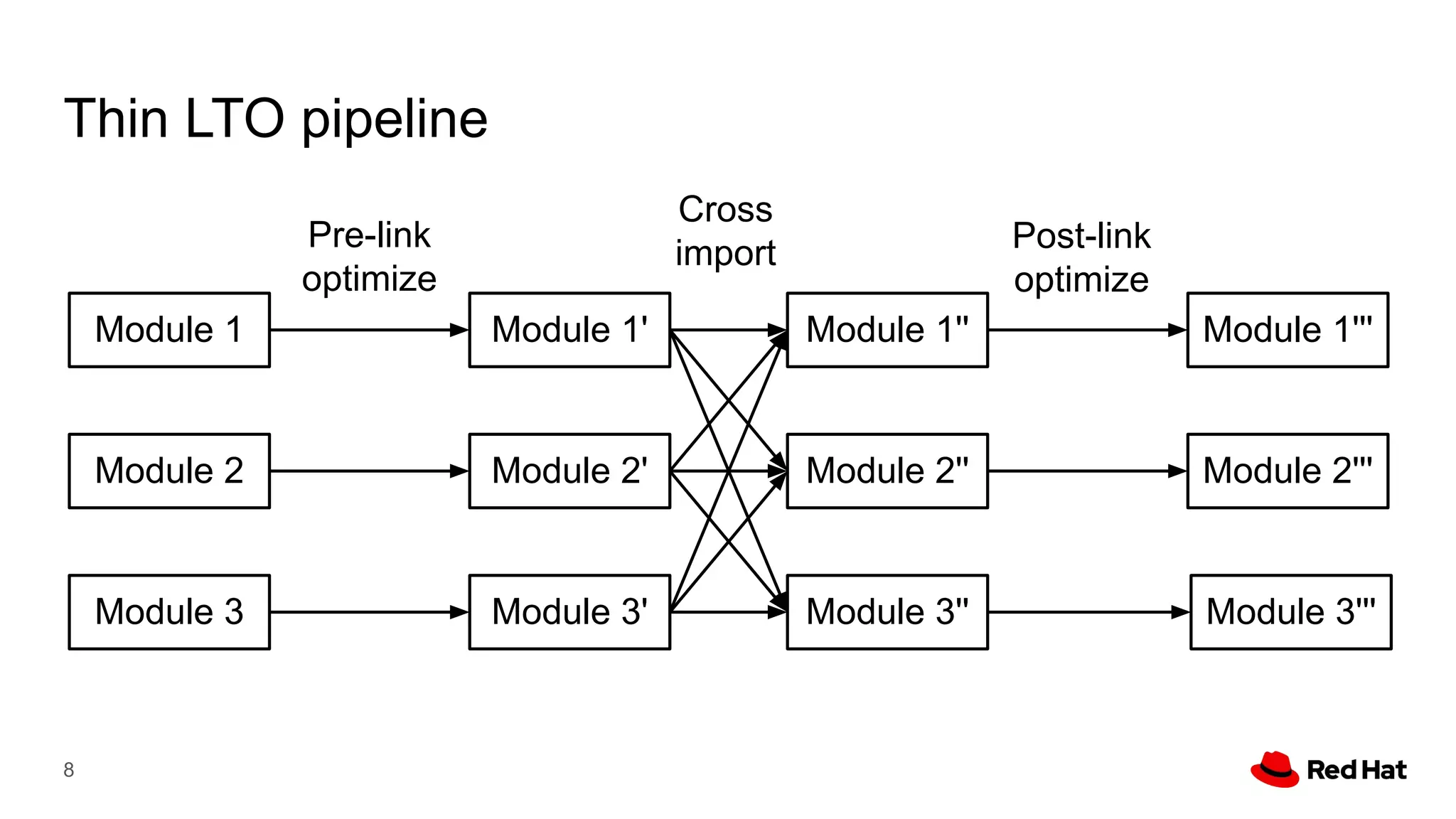
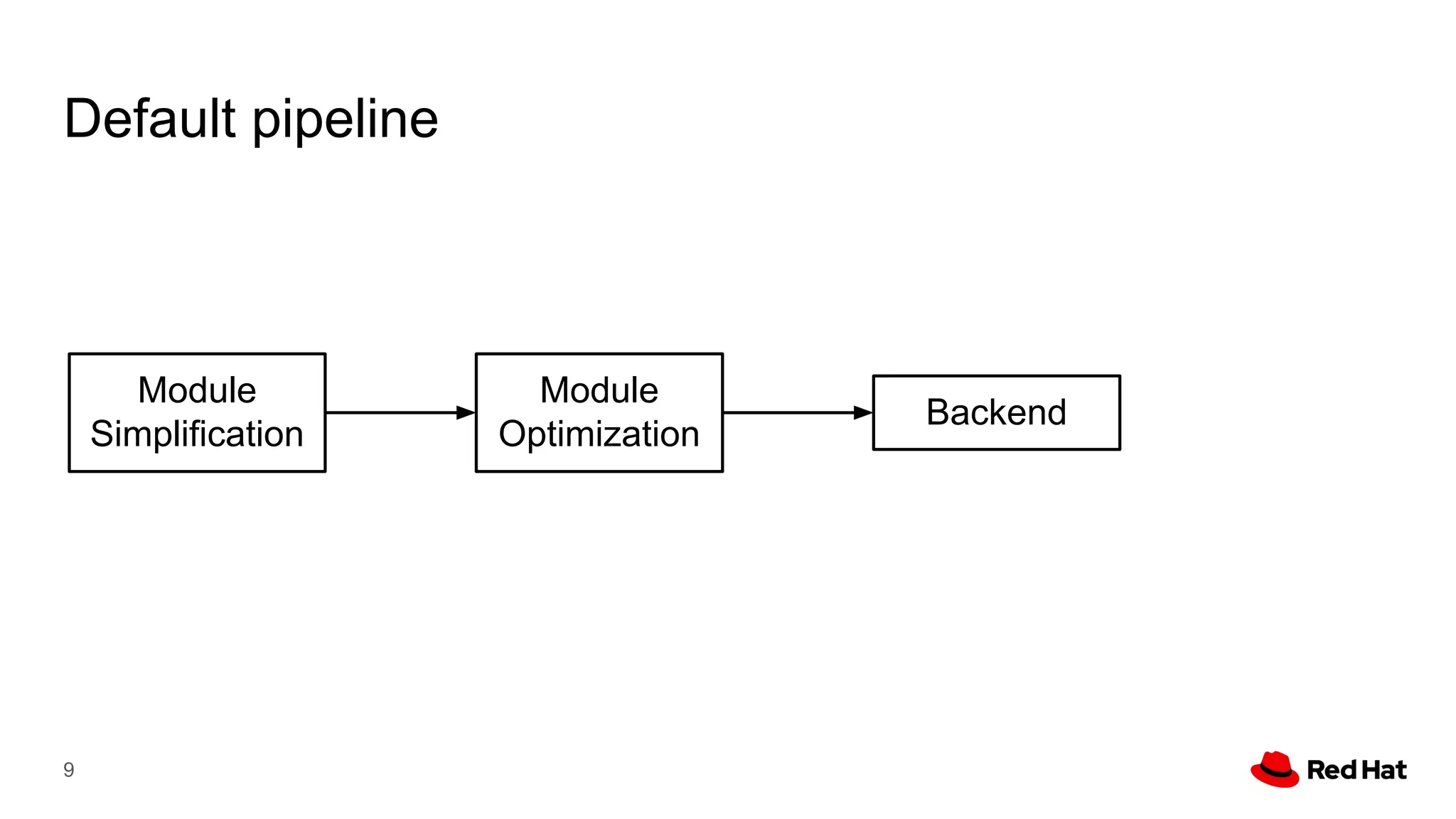
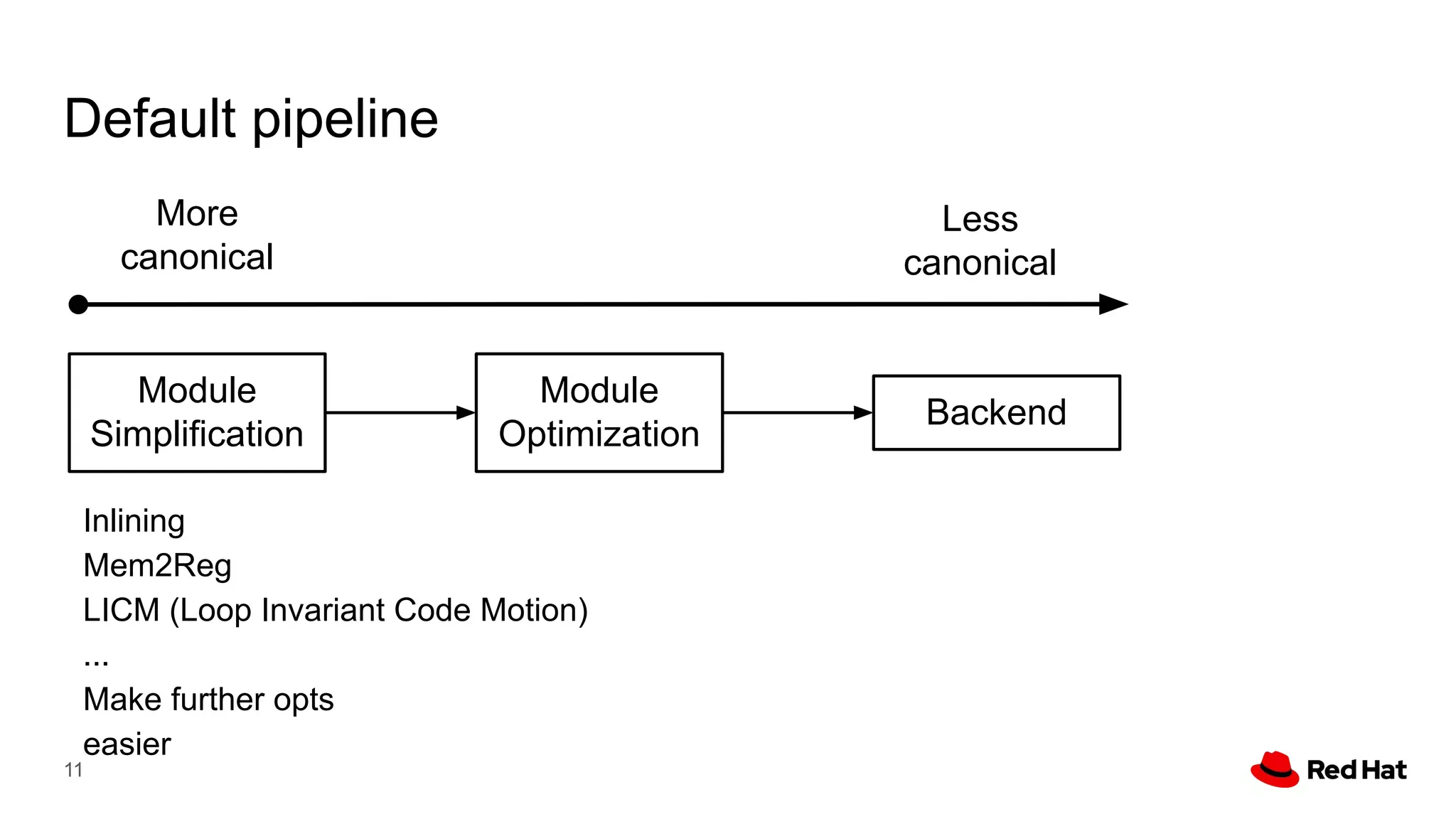
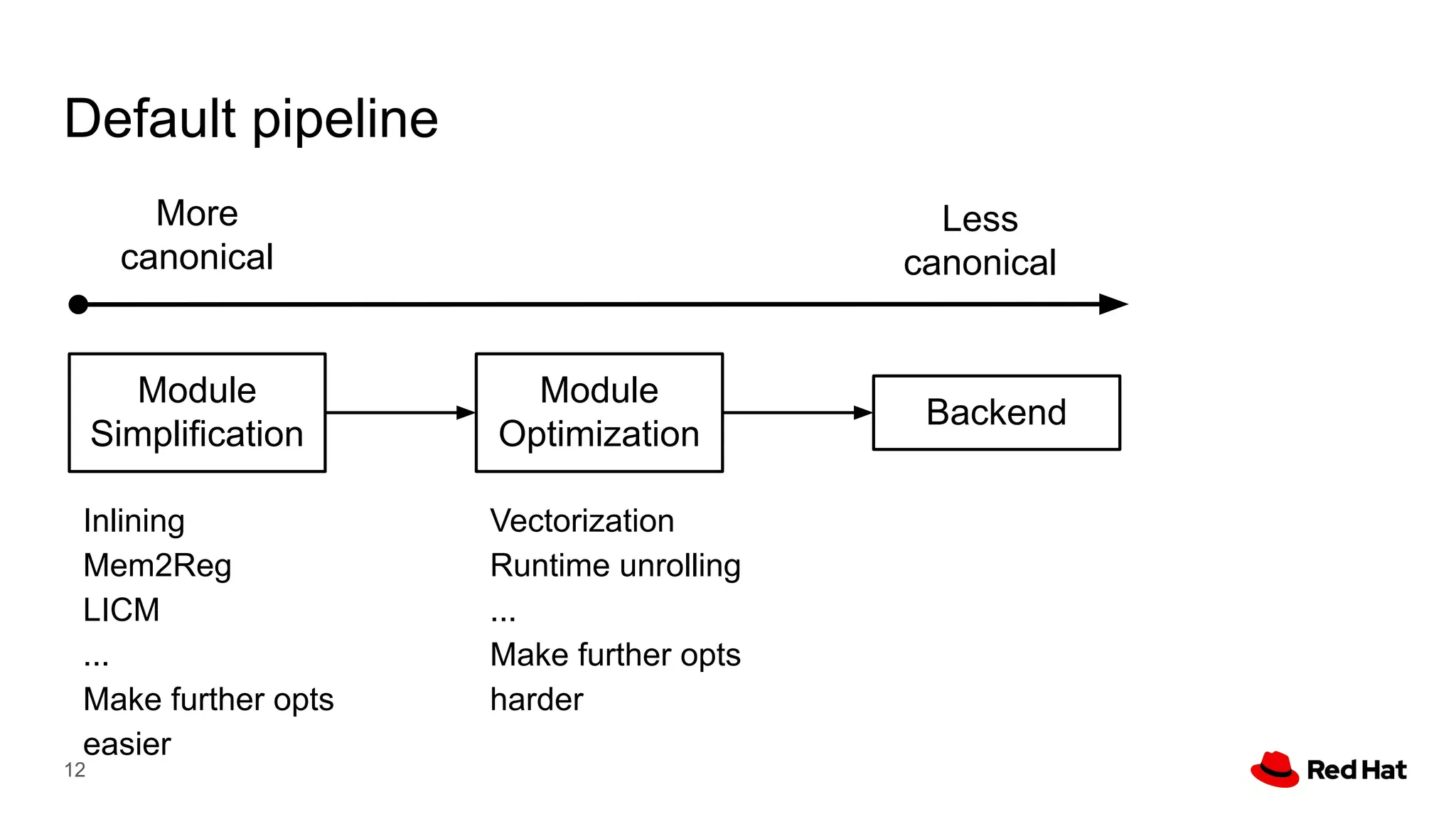
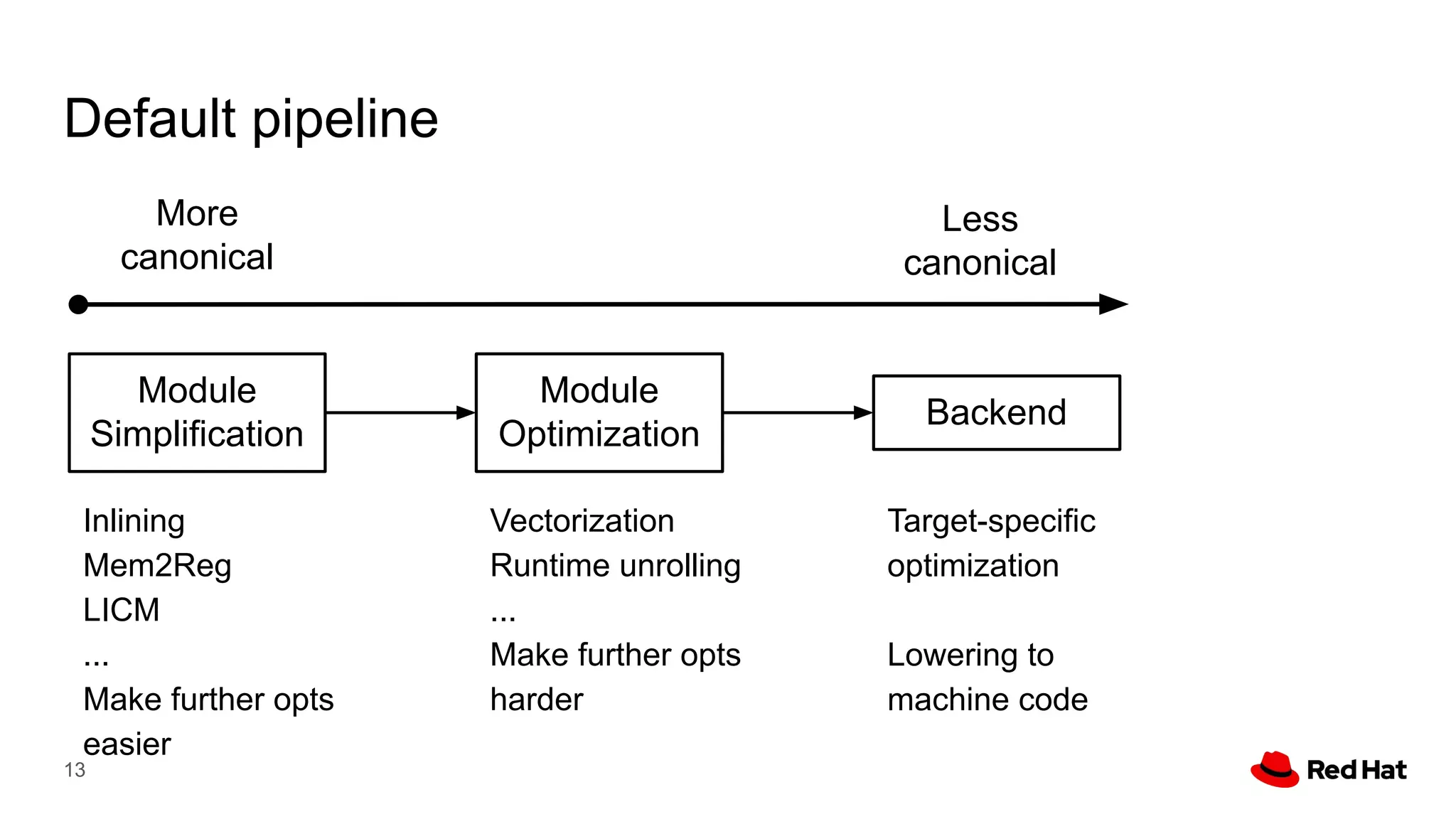
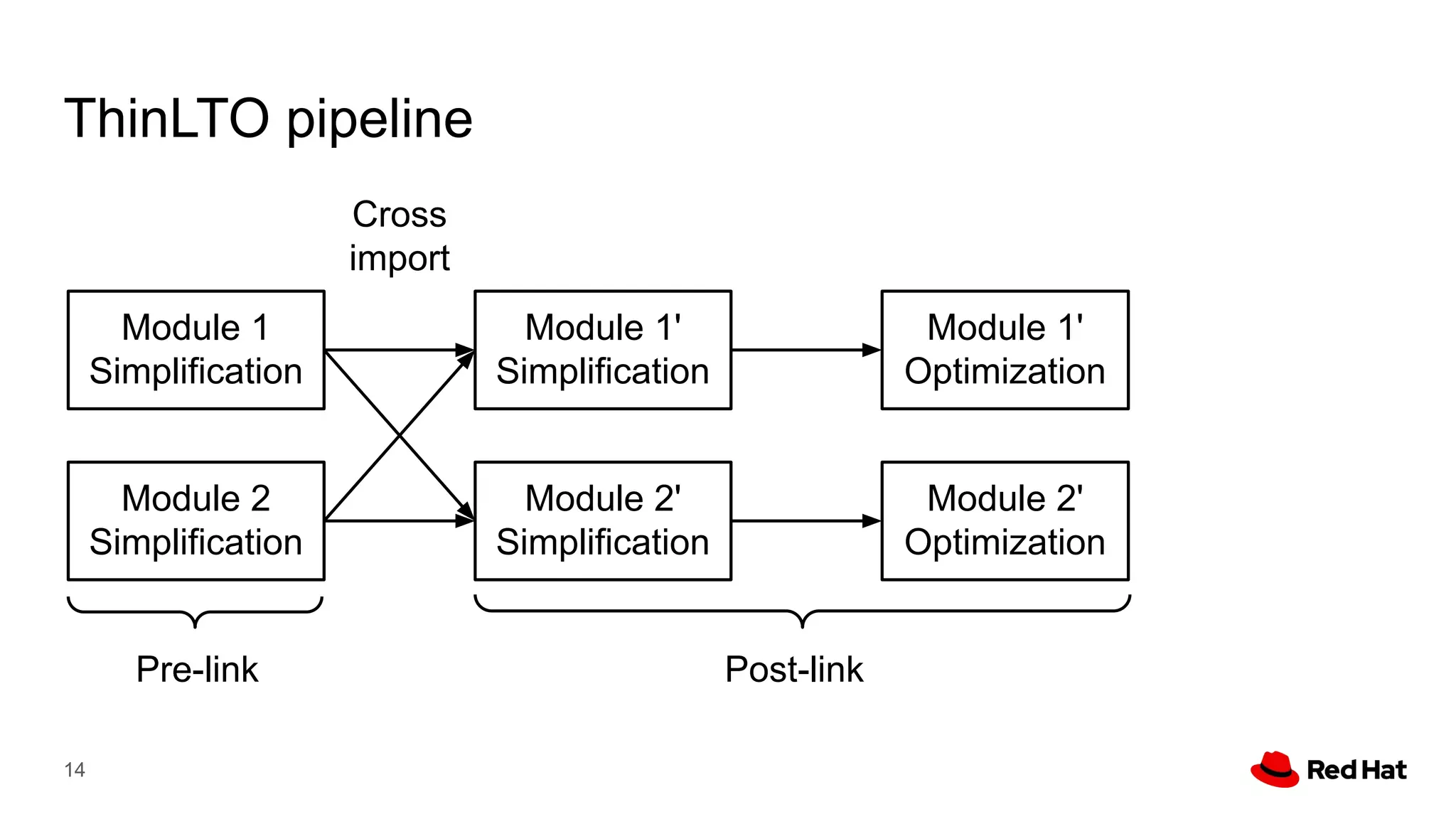
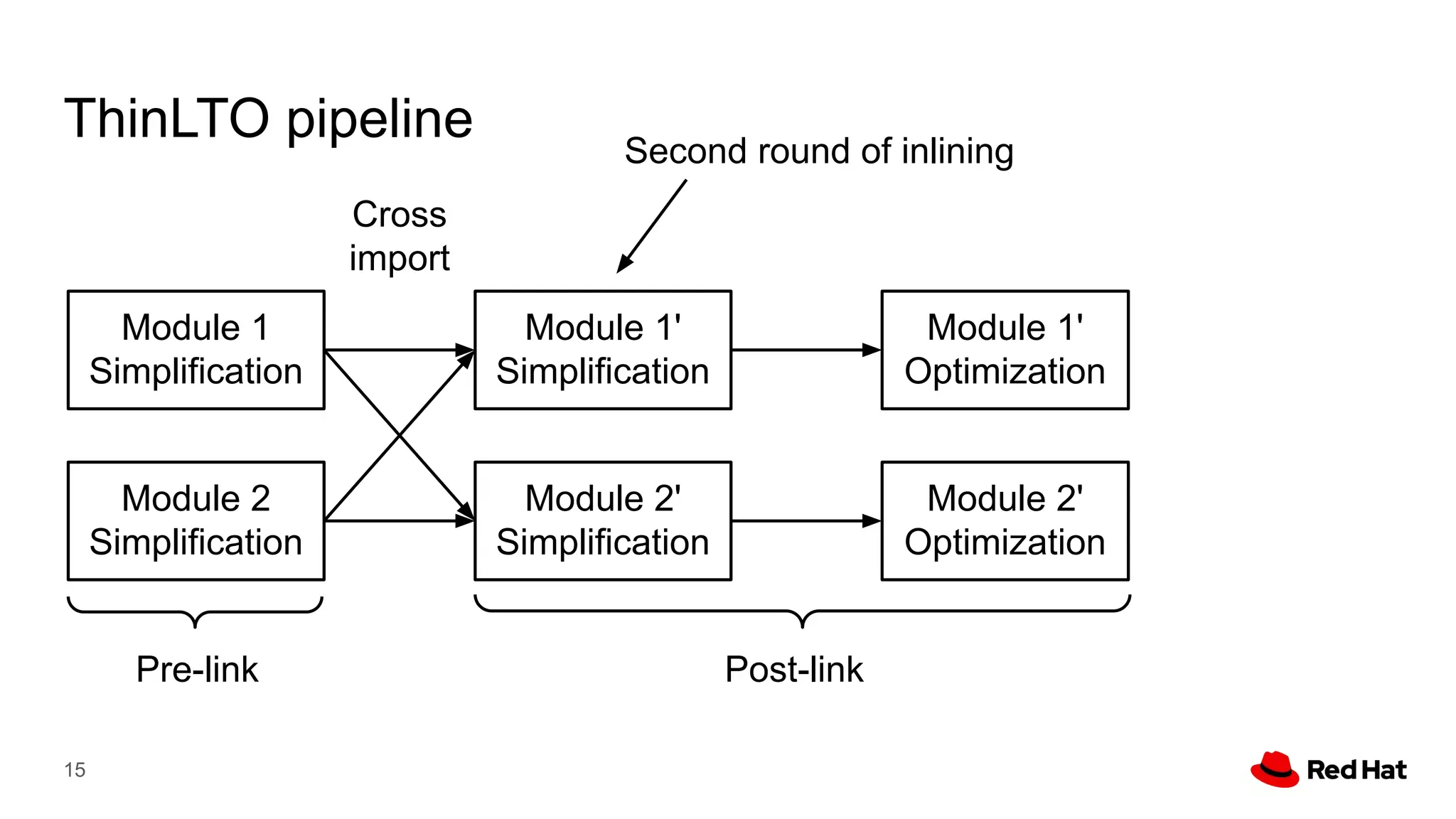
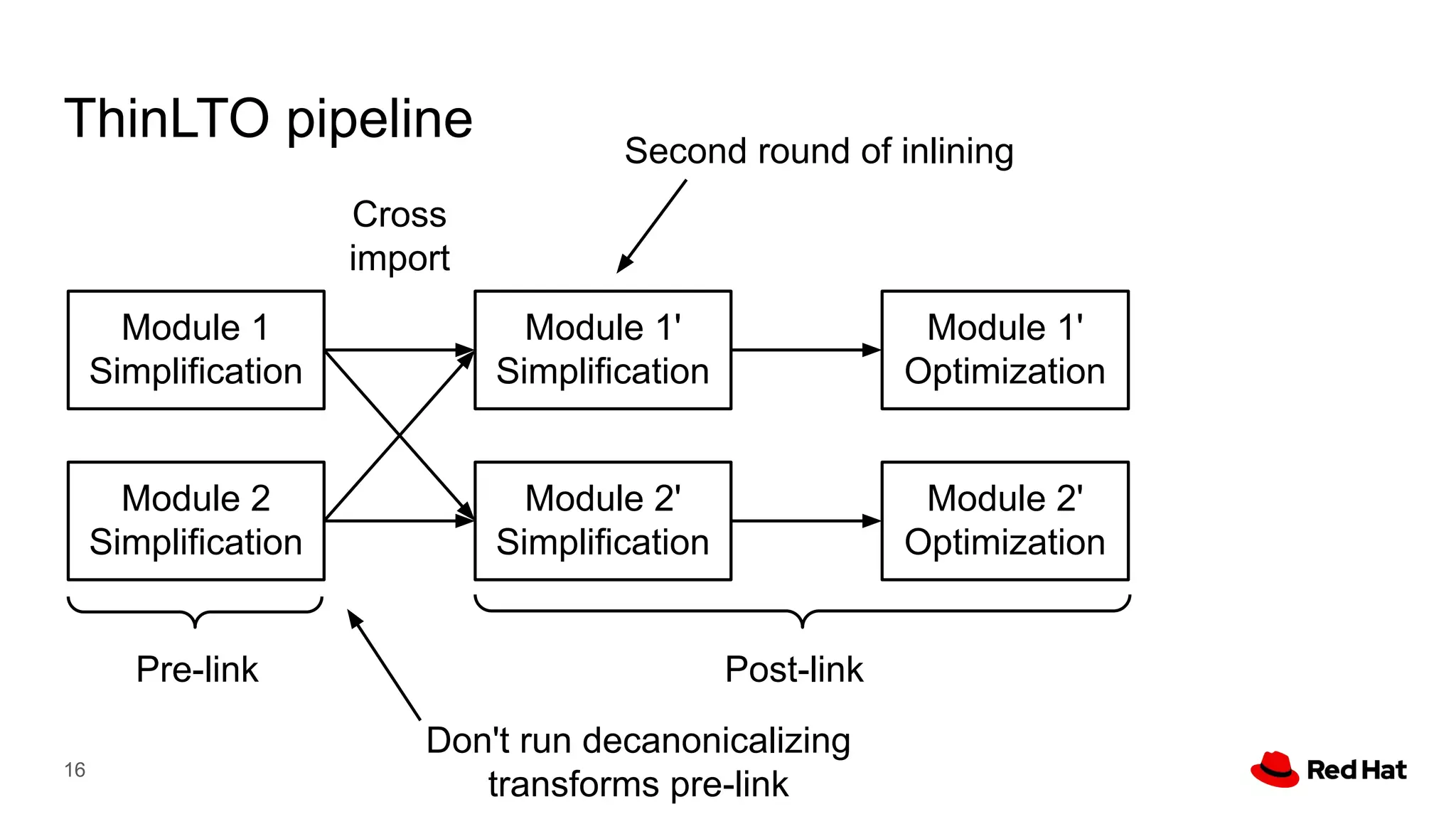
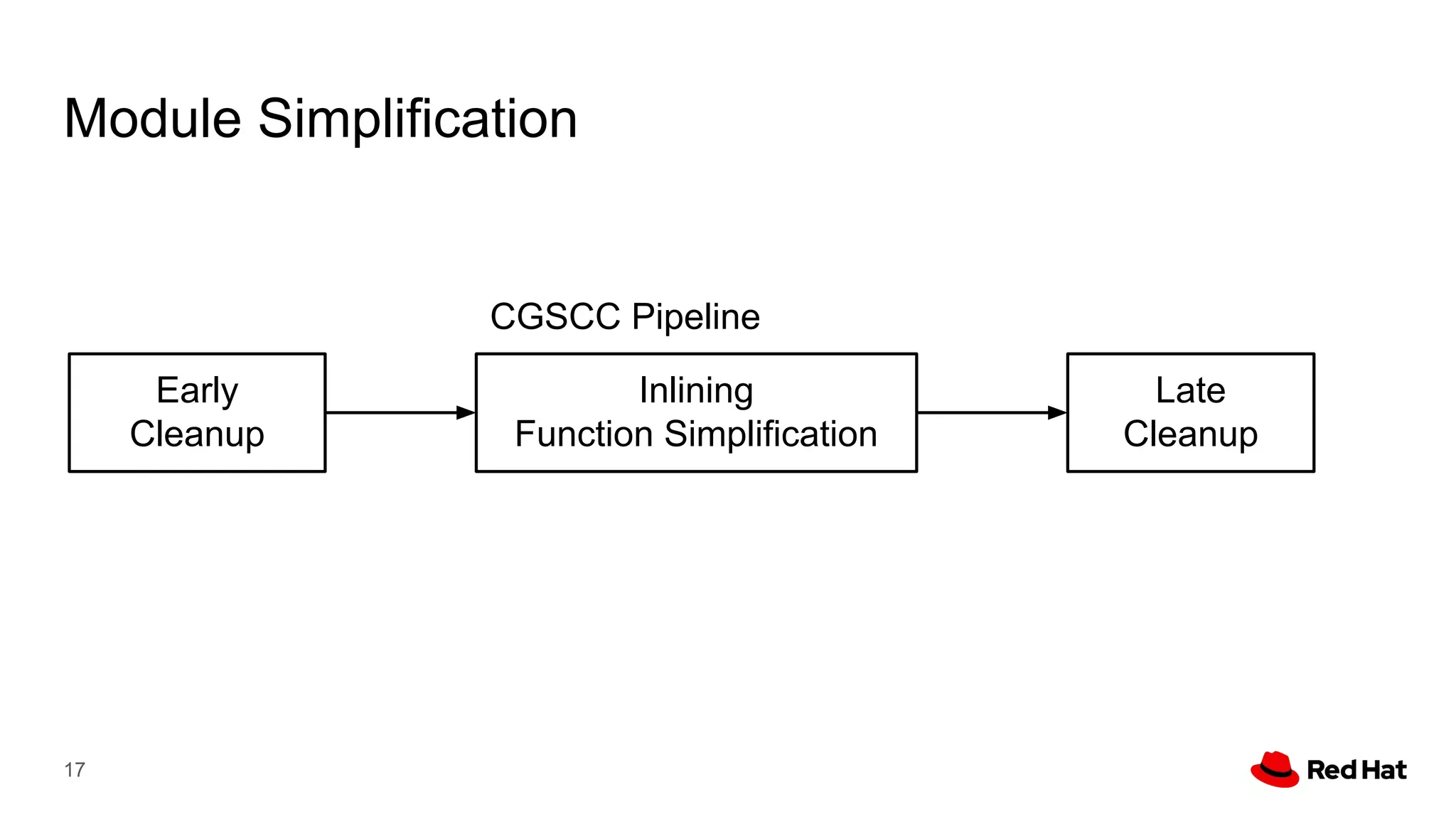
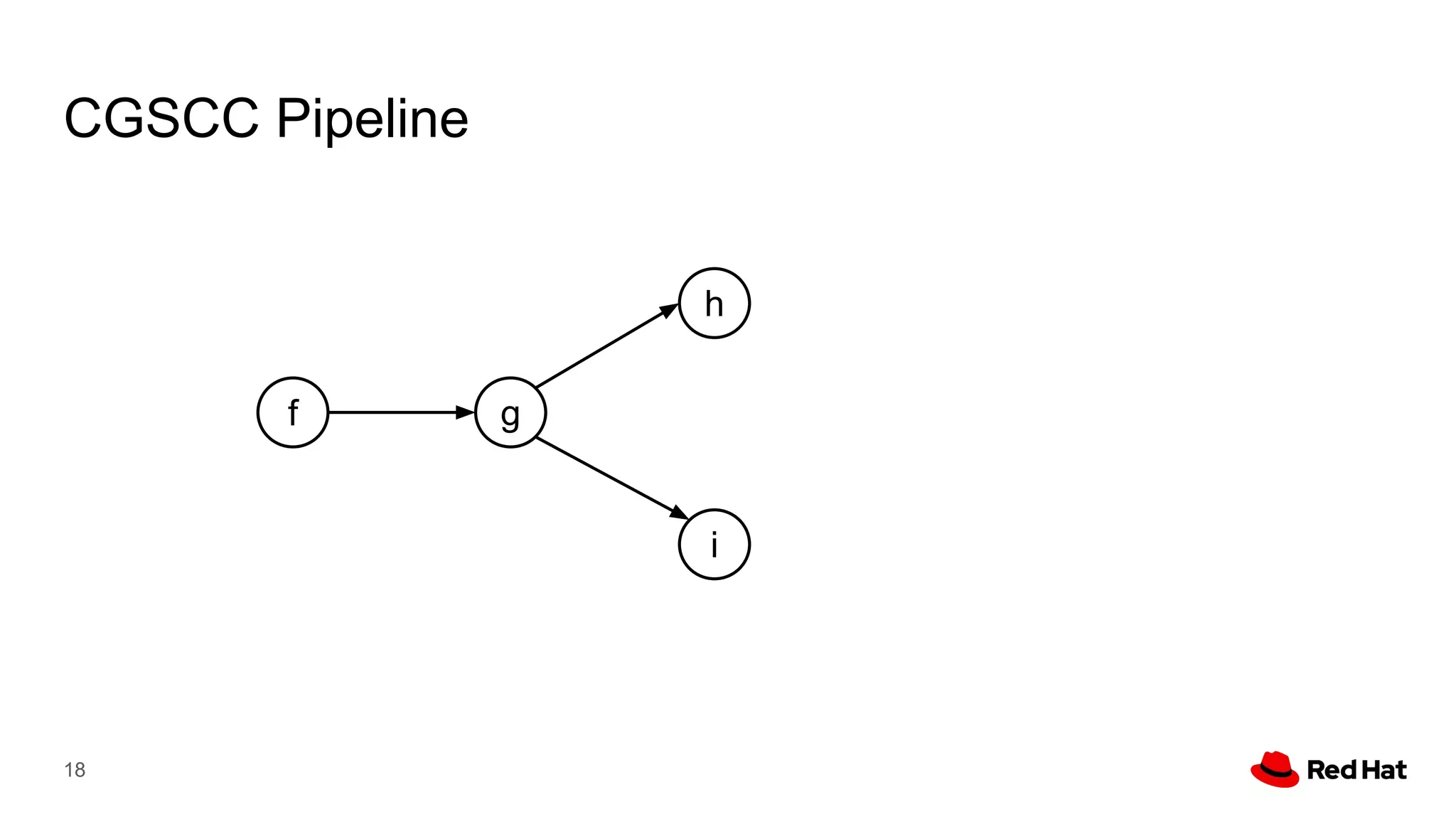
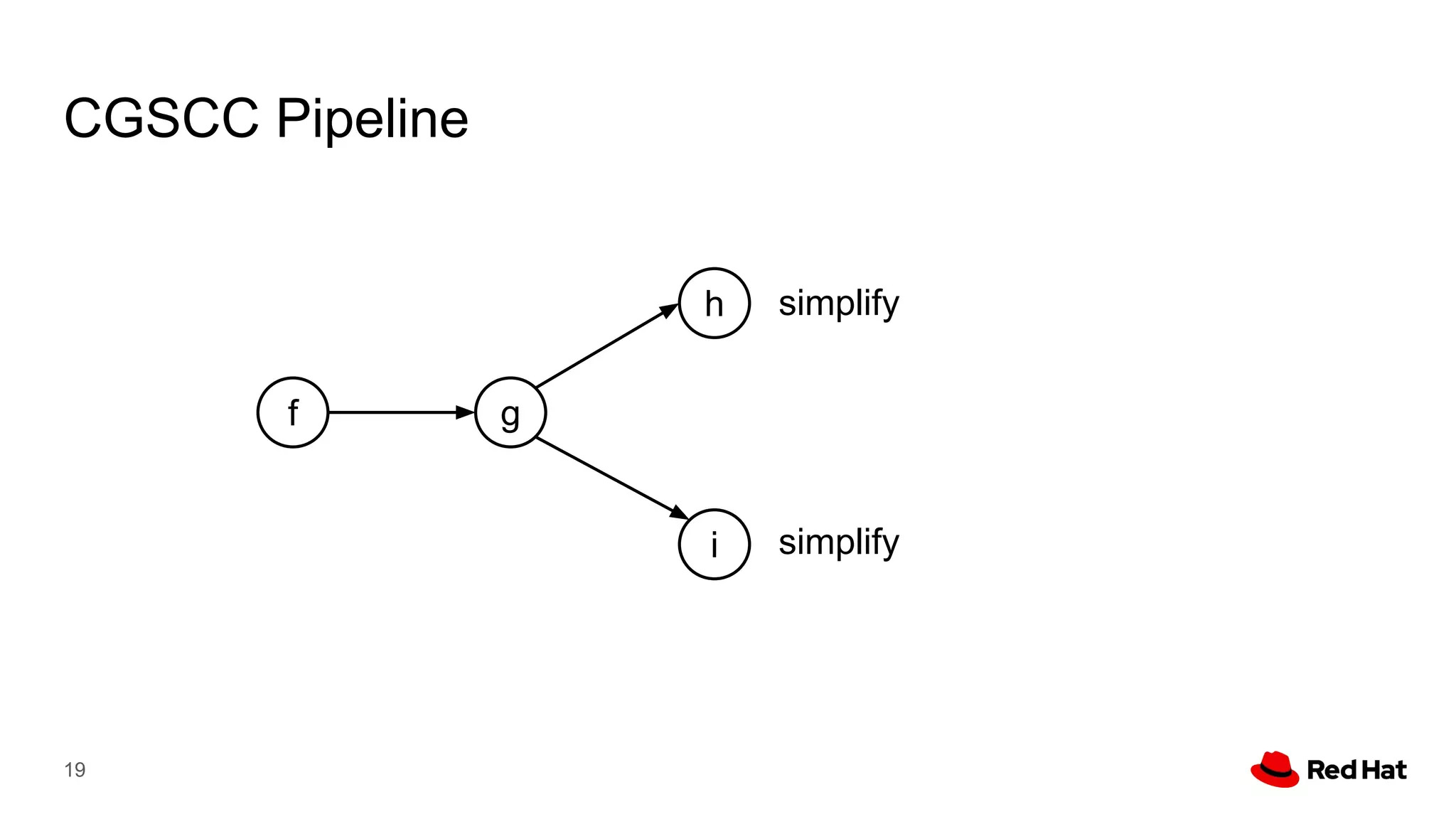
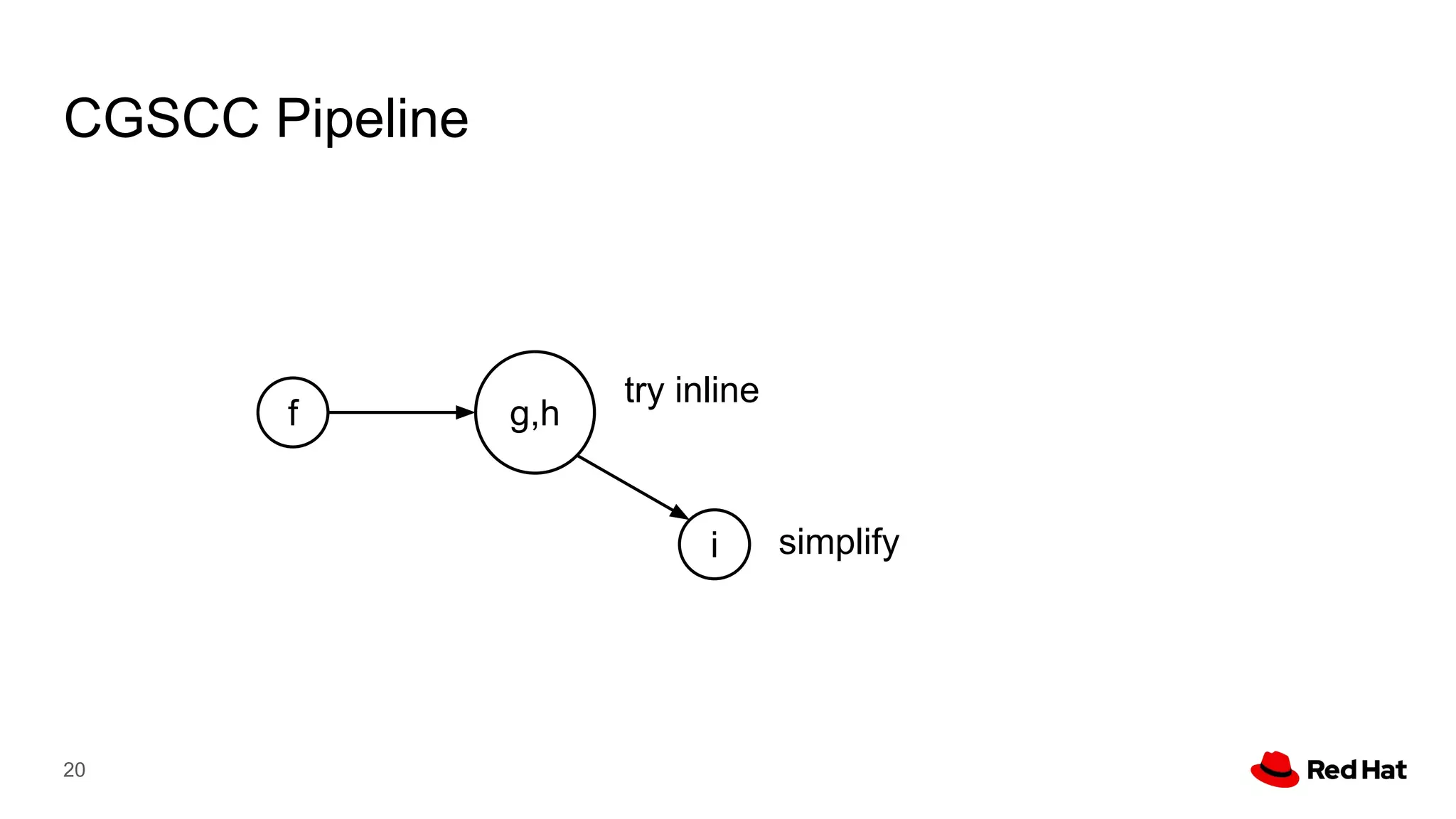
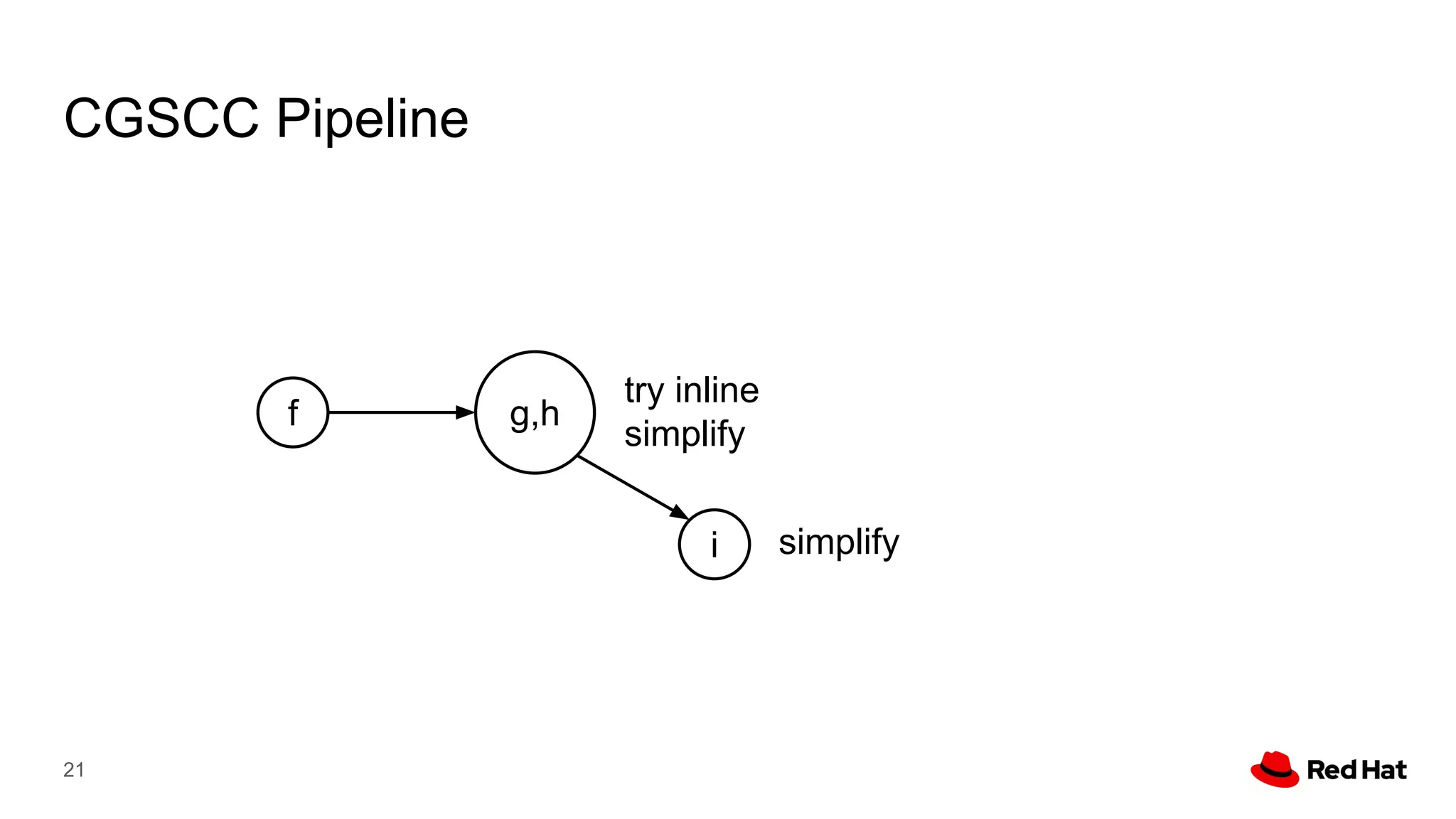
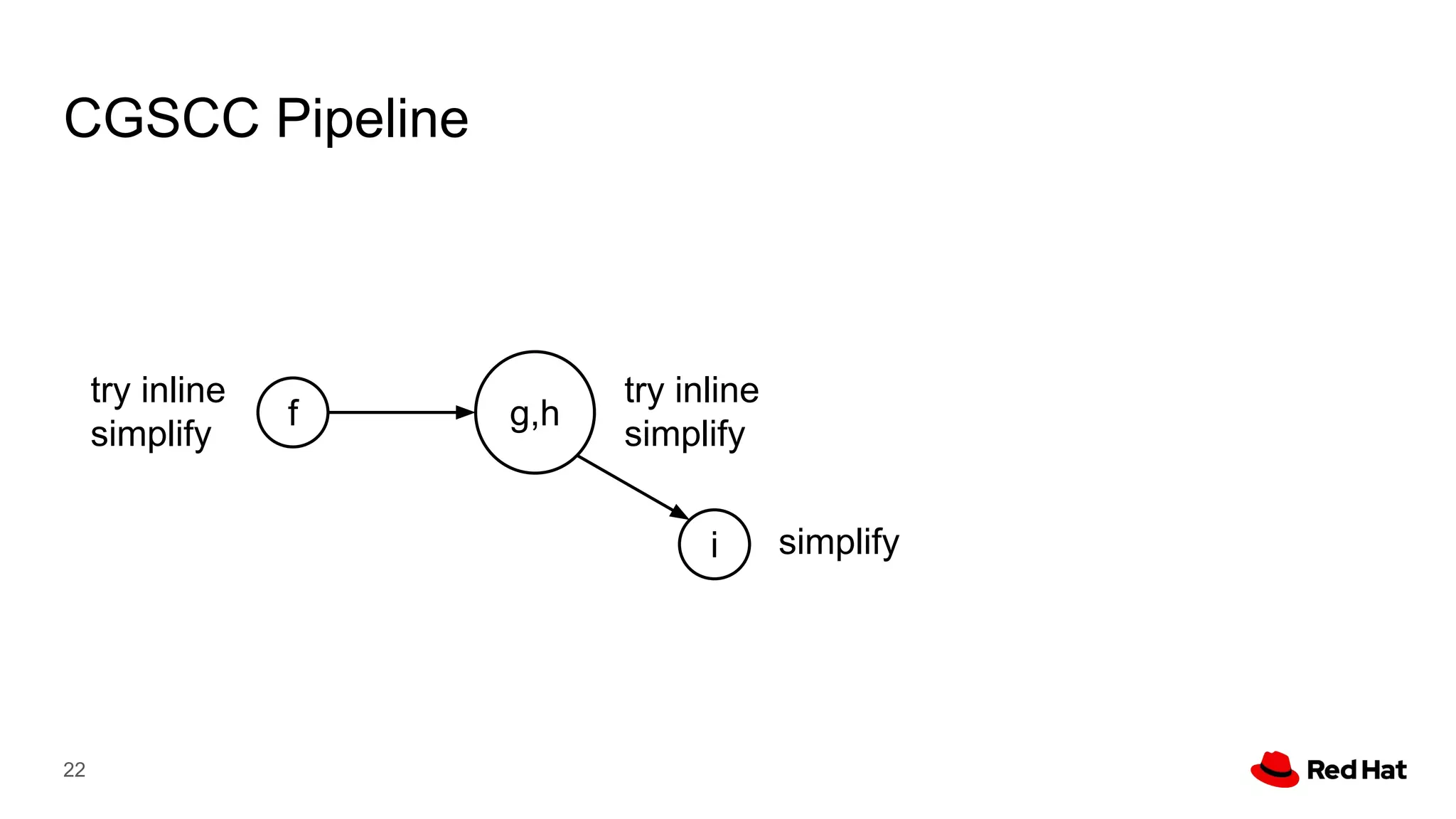
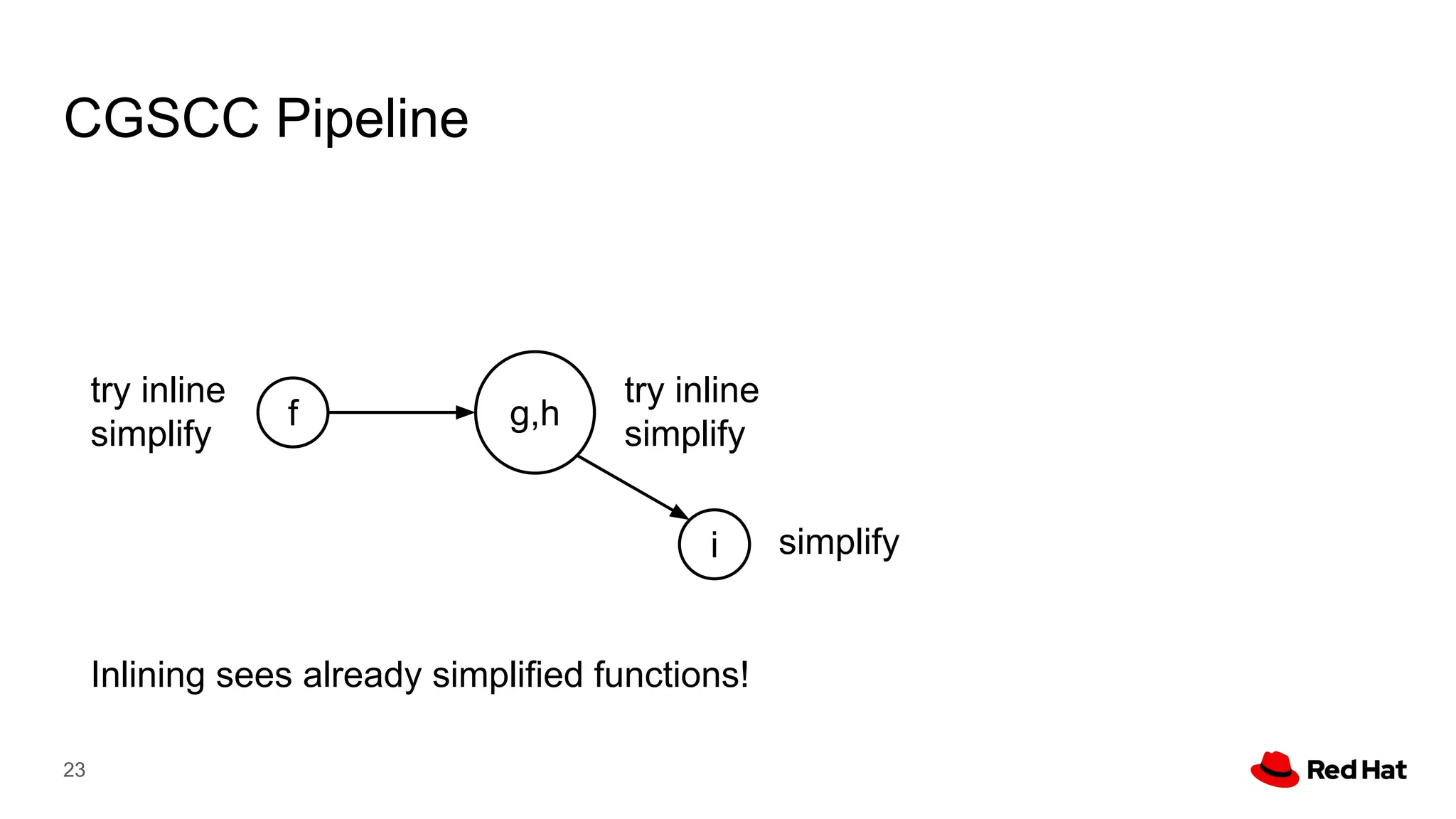
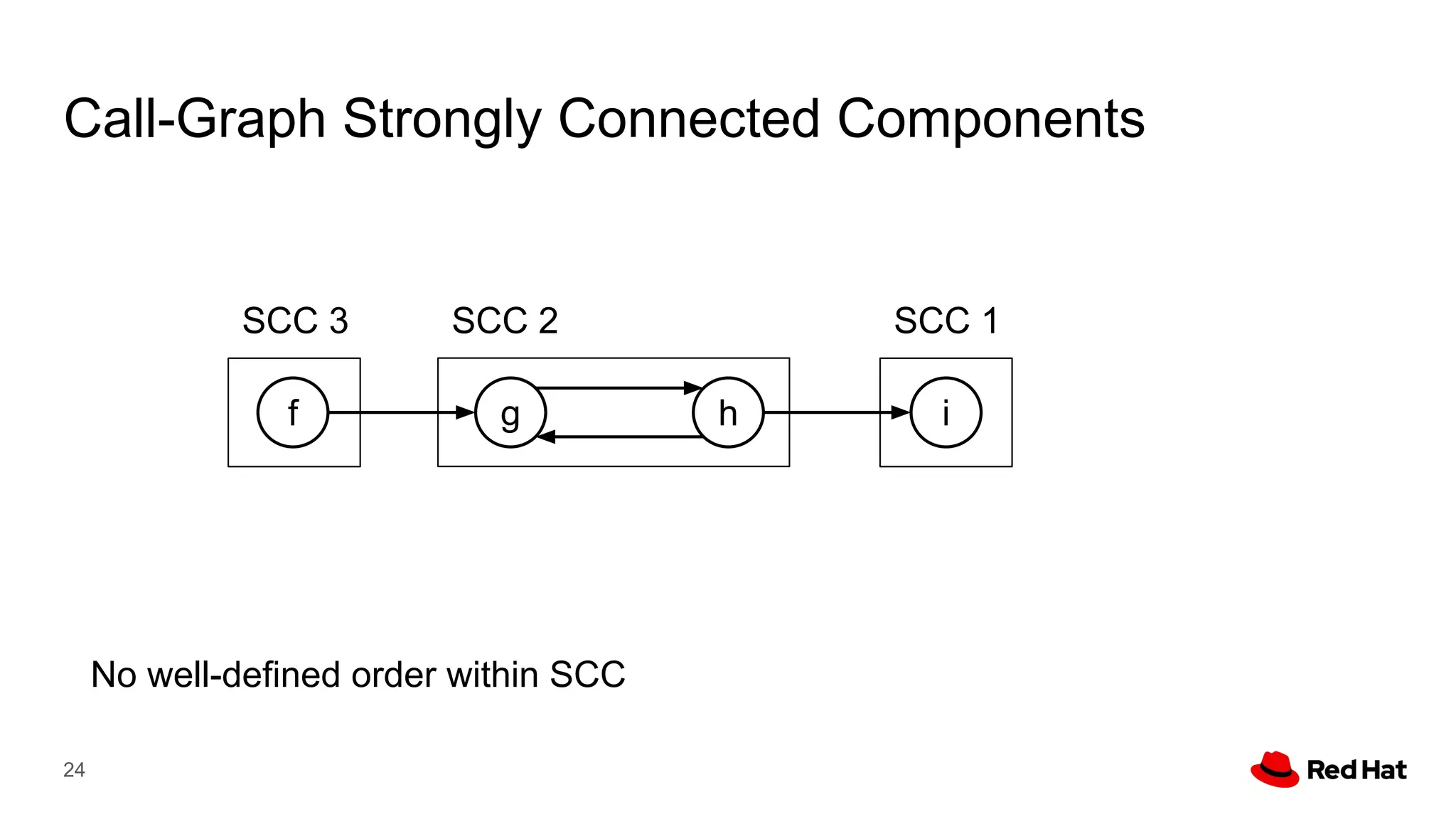
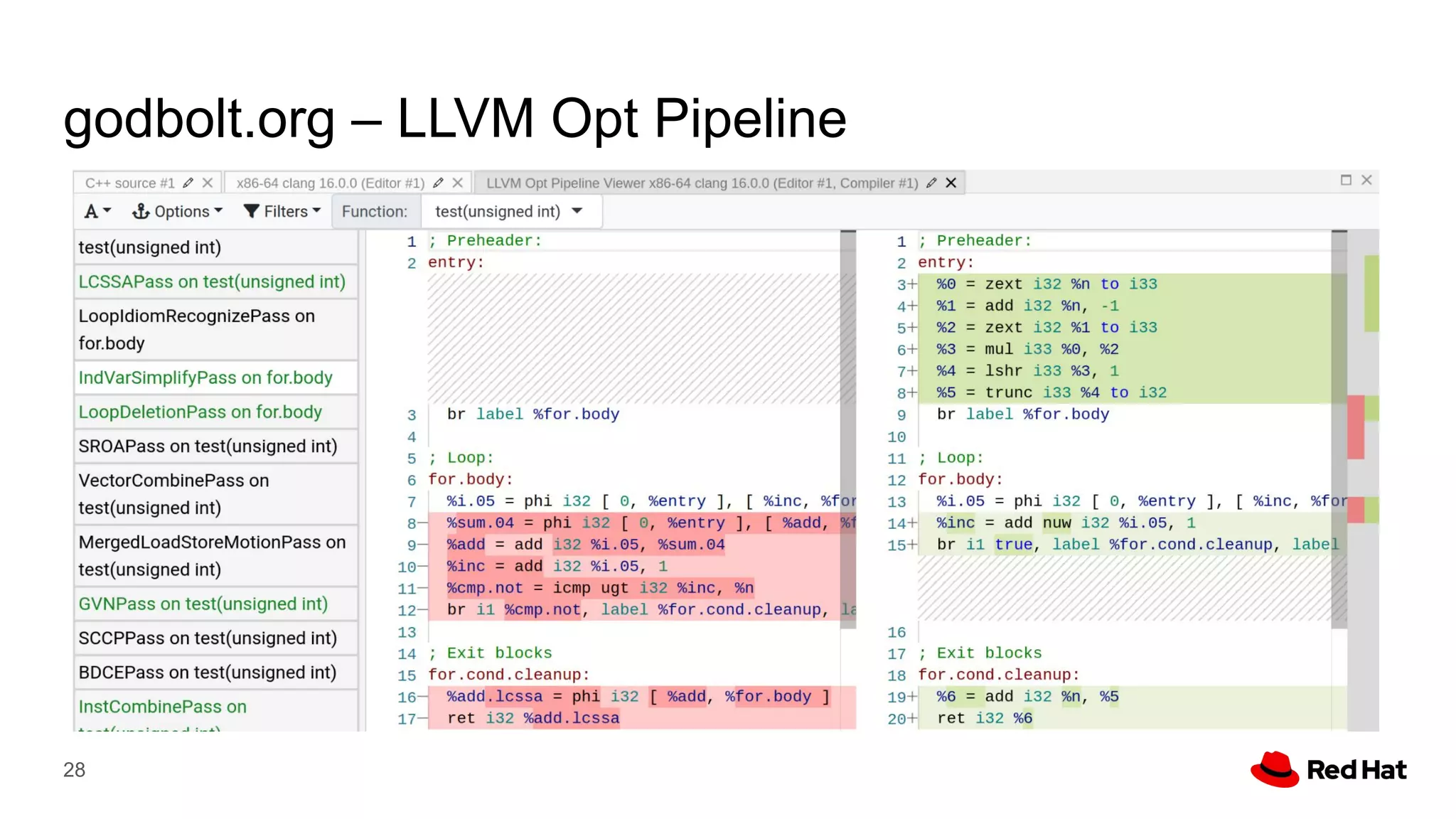
This document presents a detailed overview of the LLVM optimizer, specifically focusing on the middle-end optimization pipeline and important optimization passes. It discusses various techniques such as module simplification, control-flow optimization, instruction combining, and memory optimizations, providing insights into how different passes interact within the optimization process. Additionally, it outlines the responsibilities and constraints of key optimization passes used in LLVM, as well as examples of optimization strategies employed.























![[아이펀팩토리] 2018 데브데이 서버위더스 _04 리눅스 게임 서버 성능 분석](https://cdn.slidesharecdn.com/ss_thumbnails/devday-2018-03-jinukkim1-180328105248-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)






![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

