Downloaded 776 times















![A fight against complexity
!
…
5. We’re against complexity. We believe designing systems
is a fight against complexity. […] Most of the time the
best way to fight complexity is by not creating it at all.
…
The Redis Manifesto▸](https://image.slidesharecdn.com/redis-140308045328-phpapp02/75/Everything-you-always-wanted-to-know-about-Redis-but-were-afraid-to-ask-16-2048.jpg)




















![Scripting
Hello world!
> EVAL "
return redis.call('SET',
KEYS[1],
ARGV[1])" 1 foo 42
OK
!
> GET foo
"42"](https://image.slidesharecdn.com/redis-140308045328-phpapp02/75/Everything-you-always-wanted-to-know-about-Redis-but-were-afraid-to-ask-39-2048.jpg)
![Scripting
DECREMENT-IF-GREATER-THAN
EVAL "
local res = redis.call('GET', KEYS[1]);
!
if res ~= nil then
res = tonumber(res);
if res ~= nil and res > tonumber(ARGV[1]) then
res = redis.call('DECR', KEYS[1]);
end
end
!
return res" 1 foo 100](https://image.slidesharecdn.com/redis-140308045328-phpapp02/75/Everything-you-always-wanted-to-know-about-Redis-but-were-afraid-to-ask-40-2048.jpg)
![Scripting
Some more commands
๏
EVALSHA sha1 nkeys key [key…] arg [arg…]
‣
Client libraries optimistically use EVALSHA
-
‣
๏
On NOSCRIPT error, EVAL is used
Automatic version management
SCRIPT LOAD script
‣
Cached scripts are no flushed until server restart
‣
Ensures EVALSHA will not fail (e.g. MULTI/EXEC)](https://image.slidesharecdn.com/redis-140308045328-phpapp02/75/Everything-you-always-wanted-to-know-about-Redis-but-were-afraid-to-ask-41-2048.jpg)










![Replication
Some commands & configuration
๏
Trivial setup
‣
‣
๏
slaveof <host> <port>
SLAVEOF [<host> <port >| NO ONE]
Some more configuration tips
‣
slave-serve-stale-data [yes|no]
‣
repl-ping-slave-period <seconds>
‣
masterauth <password>](https://image.slidesharecdn.com/redis-140308045328-phpapp02/75/Everything-you-always-wanted-to-know-about-Redis-but-were-afraid-to-ask-52-2048.jpg)





















The document provides an in-depth overview of Redis, a popular open-source in-memory data structure store, covering its architecture, key features, and use cases. It discusses various data structures supported by Redis, scripting capabilities, persistence options, replication, and performance optimization techniques. Additionally, it highlights the significance of Redis in enhancing scalability for major platforms like Twitter and Instagram.
Overview of the Redis presentation is given with a brief definition as a remote dictionary server.
Basic commands in Redis demonstrated: setting and retrieving keys using redis-cli.
Key segments of the presentation covered: Introduction, Redis basics, and mastering Redis.
Various types of NoSQL databases mentioned, highlighting Redis's role and sponsorship history.
Real-world usage of Redis by prominent platforms such as Twitter, Instagram, and GitHub for scalability.
Discussion on Redis as an in-memory data structure server emphasizing simplicity and performance.
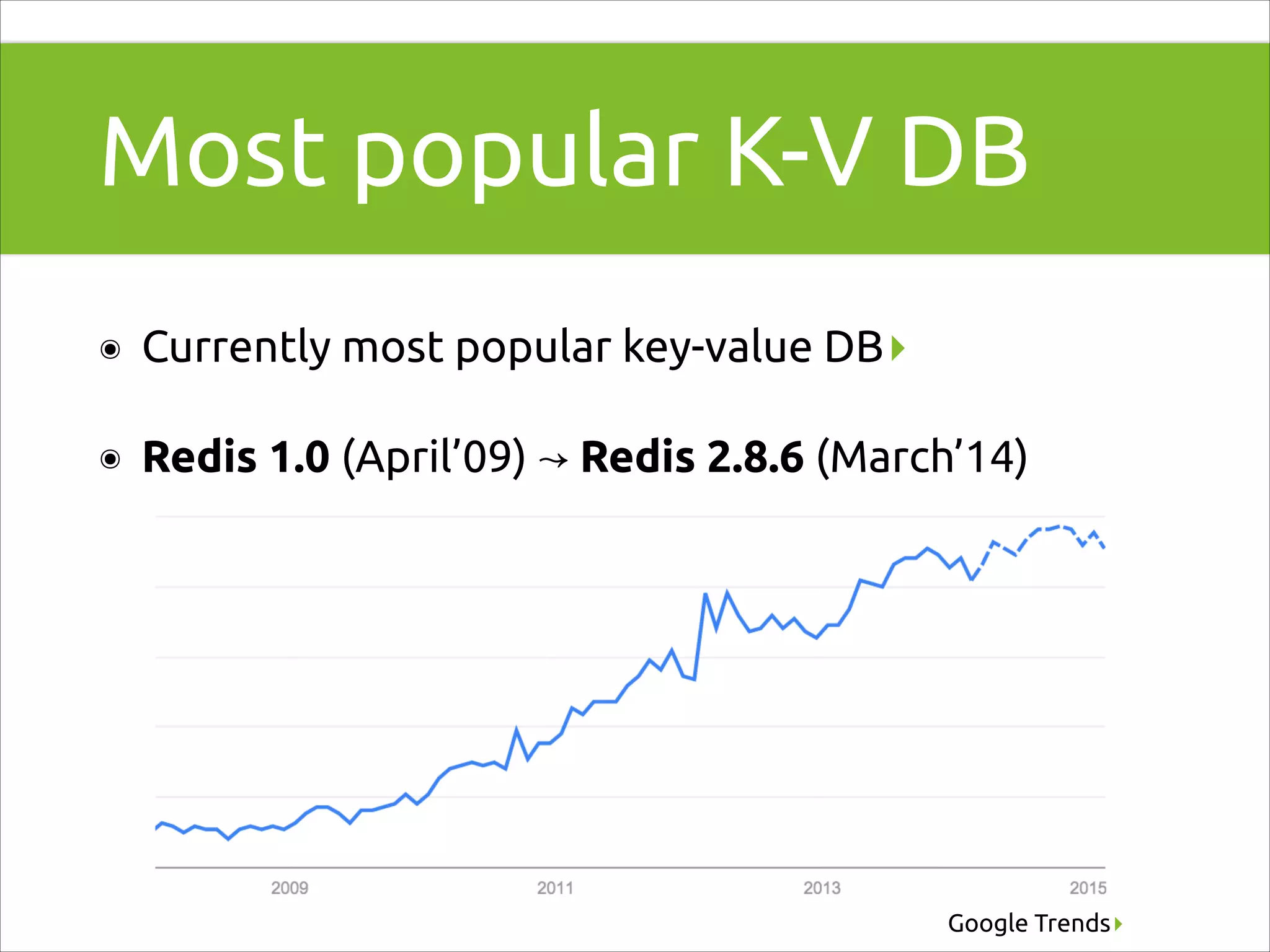
Redis's ascent as a key-value database with mentions of various releases and improvements up to March 2014.
Introduction to various Redis commands including server and client interface utilities.
Performance metrics showcasing Redis handling large request volumes at high speeds.
Concise attributes of Redis being simple, fast, predictable, reliable, widely supported, and lightweight.
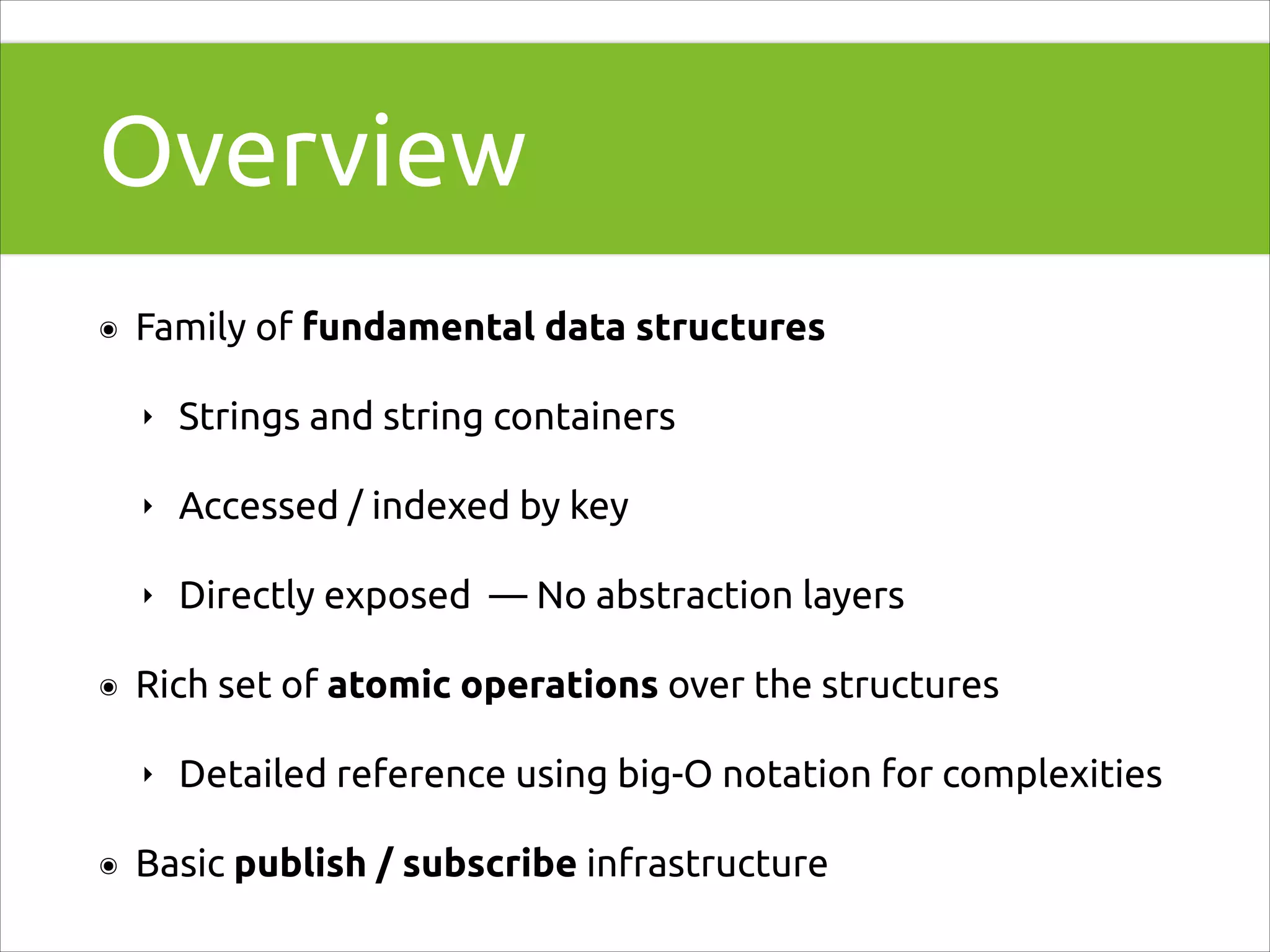
Fundamental overview of Redis data structures, emphasizing atomic operations and subscription infrastructure.
Explains key management, naming conventions, and the functionality of key expiration.
Introduction to basic data types in Redis including strings, hashes, lists, sets, and ordered sets.
Overview of publish/subscribe functionality in Redis and its operations for decoupling events.
Explanation of Redis transactions, their limitations, and the advantages of Lua scripting for atomic operations.
Diverse practical examples of using Redis for various applications and benefits from real-time data.
Insights into persistence strategies via RDB and AOF, while ensuring data durability.
Explains replication mechanisms in Redis, along with basic security features.
General tips for optimizing Redis performance, including hardware specifications and configuration.
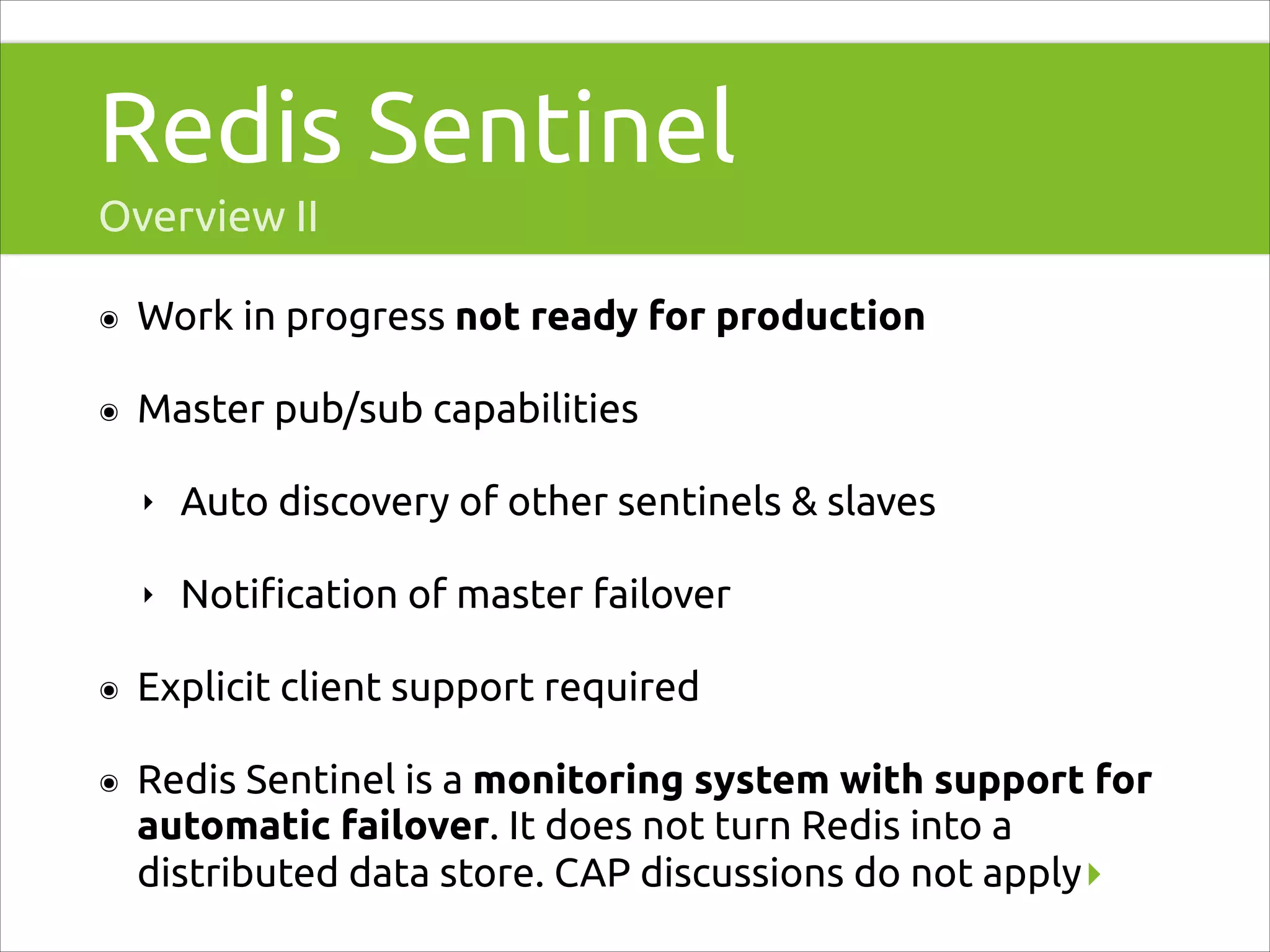
Discussion on Redis Sentinel for high availability solutions, failover capabilities, and cluster introduction.
Strategic insights into data sharding within Redis architecture including challenges and solutions.
Wrap-up and acknowledgment, closing the presentation on Redis.






![[오픈소스컨설팅] Red Hat ReaR (relax and-recover) Quick Guide](https://cdn.slidesharecdn.com/ss_thumbnails/redhatrearrelax-and-recoverquickguidev1-170419093210-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)


