Downloaded 63 times




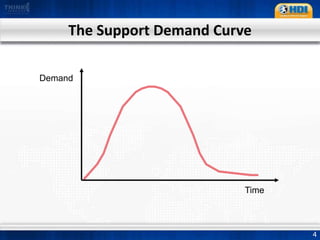
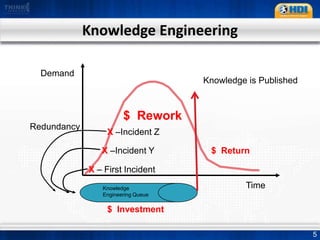
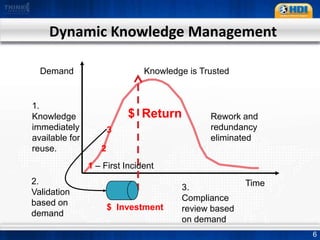



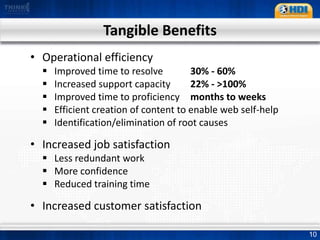

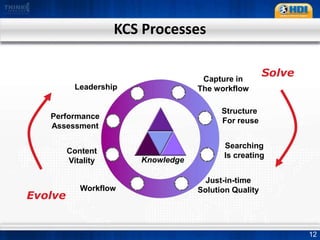
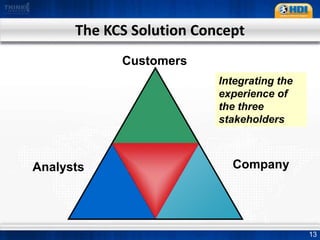
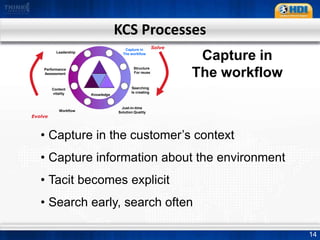
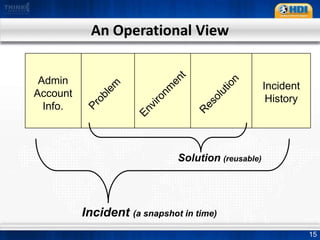
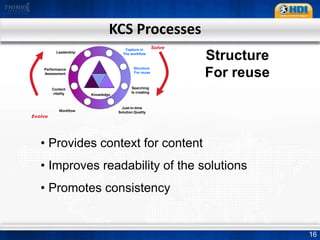






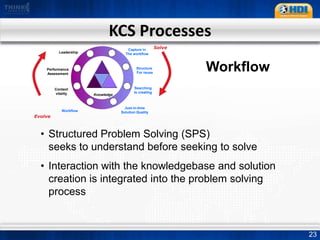
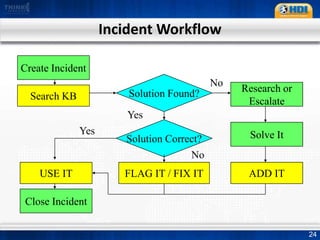
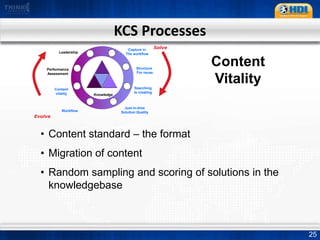

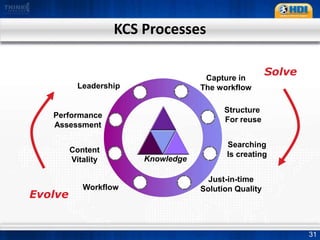



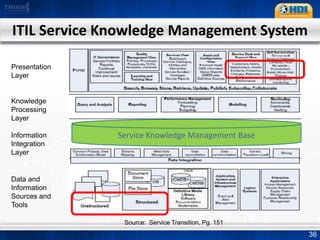






This document provides an overview of knowledge management best practices using the Knowledge-Centered Support (KCS) methodology. It discusses how KCS has evolved from traditional knowledge engineering approaches to become integrated into the problem-solving workflow. Key aspects of KCS include capturing knowledge as a byproduct of solving problems, evolving knowledge based on demand, and developing a collaborative knowledge base. The document outlines the KCS framework and processes and how they align with and enhance the ITIL framework for service management.








































![KCS-Brochure[1]](https://cdn.slidesharecdn.com/ss_thumbnails/6e78203a-ccc9-4bdc-a048-c0b30f1b997f-161026100925-thumbnail.jpg?width=640&height=640&fit=bounds)














































