Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Junichi Noda
PPTX, PDF
3,658 views
Apache Sparkを利用した「つぶやきビッグデータ」クローンとリコメンドシステムの構築
デブサミ2016 1日目のセッション内容です。 http://event.shoeisha.jp/devsumi/20160218/session/993/
Technology
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Downloaded 59 times
1
/ 48
2
/ 48
3
/ 48
4
/ 48
5
/ 48
6
/ 48
7
/ 48
8
/ 48
9
/ 48
10
/ 48
11
/ 48
12
/ 48
13
/ 48
14
/ 48
15
/ 48
16
/ 48
17
/ 48
18
/ 48
19
/ 48
20
/ 48
21
/ 48
22
/ 48
23
/ 48
24
/ 48
25
/ 48
26
/ 48
27
/ 48
28
/ 48
29
/ 48
30
/ 48
31
/ 48
32
/ 48
33
/ 48
34
/ 48
35
/ 48
36
/ 48
37
/ 48
38
/ 48
39
/ 48
40
/ 48
41
/ 48
42
/ 48
43
/ 48
44
/ 48
45
/ 48
46
/ 48
47
/ 48
48
/ 48
More Related Content
PPTX
Apache sparkでつぶやきビッグデータ クローンをつくってみた
by
Junichi Noda
PDF
Spark Streamingで作る、つぶやきビッグデータのクローン (2015-11.10版)
by
Junichi Noda
PDF
GEEK ACADEMY REAL Vol.2. 「最先端のデータ解析/Apache Sparkを利用したレコメンドエンジン開発」
by
Junichi Noda
PDF
Spark Streamingで作る、つぶやきビッグデータのクローン(Hadoop Spark Conference Japan 2016版)
by
Junichi Noda
PPTX
Spark streamingを使用したtwitter解析によるレコメンドサービス例
by
Junichi Noda
PDF
Spark Streaming と Spark GraphX を使用したTwitter解析による レコメンドサービス例
by
Junichi Noda
PDF
2015 10 24_spark_osc15tk
by
Junichi Noda
PDF
GraphXはScalaエンジニアにとってのブルーオーシャン @ Scala Matsuri 2014
by
鉄平 土佐
Apache sparkでつぶやきビッグデータ クローンをつくってみた
by
Junichi Noda
Spark Streamingで作る、つぶやきビッグデータのクローン (2015-11.10版)
by
Junichi Noda
GEEK ACADEMY REAL Vol.2. 「最先端のデータ解析/Apache Sparkを利用したレコメンドエンジン開発」
by
Junichi Noda
Spark Streamingで作る、つぶやきビッグデータのクローン(Hadoop Spark Conference Japan 2016版)
by
Junichi Noda
Spark streamingを使用したtwitter解析によるレコメンドサービス例
by
Junichi Noda
Spark Streaming と Spark GraphX を使用したTwitter解析による レコメンドサービス例
by
Junichi Noda
2015 10 24_spark_osc15tk
by
Junichi Noda
GraphXはScalaエンジニアにとってのブルーオーシャン @ Scala Matsuri 2014
by
鉄平 土佐
What's hot
PPTX
Apache NiFiと 他プロダクトのつなぎ方
by
Sotaro Kimura
PDF
楽天のSplunk as a service
by
Rakuten Group, Inc.
PDF
Awsでつくるapache kafkaといろんな悩み
by
Keigo Suda
PDF
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
PPTX
Jazug6周年lt(片倉義昌)
by
Yoshimasa Katakura
PDF
2015/04/25 妖怪は見た!実録Azure事件簿アプリケーション編 / Global Azure Boot Camp
by
Yuki KAN
PDF
2015/04/25 Azure JavaScript API App つくったよ (LT) / Global Azure Boot Camp
by
Yuki KAN
PPTX
Elasticsearch 変わり種プラグインの作り方
by
Ryoji Kurosawa
PPTX
Zabbixによるオートスケーリングクラスタ監視とオペレーション自動化
by
真乙 九龍
PDF
20150312 html5とか勉強会-lt-開発者に知ってほしいi pv6のこと
by
v6app
PDF
elasticsearchプラグイン入門
by
Shinsuke Sugaya
PDF
Spark Streaming on AWS -S3からKinesisへ-
by
chibochibo
PDF
Spark in small or middle scale data processing with Elasticsearch
by
chibochibo
PDF
Osc2013 kansai@kyoto ZABBIX-JP クラウド環境監視効率化
by
Daisuke Ikeda
PDF
ニコニコニュースと全文検索
by
techtalkdwango
PDF
さくらのナレッジの運営から見えるもの
by
法林浩之
PDF
第2回インフラエンジニアのためのプレゼン技術研究会(オススメの技術書)
by
Ken Sawada
PDF
Kafka logをオブジェクトストレージに連携する方法まとめ
by
Keigo Suda
PDF
MariaDBとMroongaで作る全言語対応超高速全文検索システム
by
Kouhei Sutou
PDF
私がCloudStackを使う4つの理由
by
Takuma Nakajima
Apache NiFiと 他プロダクトのつなぎ方
by
Sotaro Kimura
楽天のSplunk as a service
by
Rakuten Group, Inc.
Awsでつくるapache kafkaといろんな悩み
by
Keigo Suda
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
Jazug6周年lt(片倉義昌)
by
Yoshimasa Katakura
2015/04/25 妖怪は見た!実録Azure事件簿アプリケーション編 / Global Azure Boot Camp
by
Yuki KAN
2015/04/25 Azure JavaScript API App つくったよ (LT) / Global Azure Boot Camp
by
Yuki KAN
Elasticsearch 変わり種プラグインの作り方
by
Ryoji Kurosawa
Zabbixによるオートスケーリングクラスタ監視とオペレーション自動化
by
真乙 九龍
20150312 html5とか勉強会-lt-開発者に知ってほしいi pv6のこと
by
v6app
elasticsearchプラグイン入門
by
Shinsuke Sugaya
Spark Streaming on AWS -S3からKinesisへ-
by
chibochibo
Spark in small or middle scale data processing with Elasticsearch
by
chibochibo
Osc2013 kansai@kyoto ZABBIX-JP クラウド環境監視効率化
by
Daisuke Ikeda
ニコニコニュースと全文検索
by
techtalkdwango
さくらのナレッジの運営から見えるもの
by
法林浩之
第2回インフラエンジニアのためのプレゼン技術研究会(オススメの技術書)
by
Ken Sawada
Kafka logをオブジェクトストレージに連携する方法まとめ
by
Keigo Suda
MariaDBとMroongaで作る全言語対応超高速全文検索システム
by
Kouhei Sutou
私がCloudStackを使う4つの理由
by
Takuma Nakajima
Viewers also liked
PDF
広告配信現場で使うSpark機械学習
by
x1 ichi
PDF
How to develop a huge Single Page Application
by
Naoki Yamada
PDF
Akira shibata at developer summit 2016
by
Akira Shibata
PDF
Sparkで始めるお手軽グラフデータ分析
by
Nagato Kasaki
PDF
Selenium boot campの紹介
by
Nozomi Ito
PDF
IT系女子集まれ!女子部カンファレンスvo.1 用スライド資料
by
Kazumi OHIRA
PDF
本当にあったApache Spark障害の話
by
x1 ichi
PPTX
Disrupting Big Data with Apache Spark in the Cloud
by
Jen Aman
PPTX
【18-C-5】C# で iOS/Androidアプリ開発 - Visual Studio 2015 + Xamarin + MVVMCross -
by
ShinichiAoyagi
PPTX
モノづくりを楽しもう! ~ このデバイスとクラウドでできること
by
Kazumi OHIRA
PDF
Kafka 0.10.0 アップデート、プロダクション100ノードでやってみた #yjdsnight
by
Yahoo!デベロッパーネットワーク
PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
PDF
Apache Atlasの現状とデータガバナンス事例 #hadoopreading
by
Yahoo!デベロッパーネットワーク
PDF
Spark as a Platform to Support Multi-Tenancy and Many Kinds of Data Applicati...
by
Spark Summit
PDF
Top 5 mistakes when writing Spark applications
by
hadooparchbook
PDF
クラウドを使ったデザイン データ活用 - Autodesk Forge ご紹介 @ デブサミ 2016
by
Isezaki Toshiaki
PDF
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
PDF
我が家のフロントエンド開発事情
by
Naoki Yamada
PPTX
Sparkでレコメンドエンジンを作ってみた
by
fujita_s
PDF
Java script.trend(spec)
by
dynamis
広告配信現場で使うSpark機械学習
by
x1 ichi
How to develop a huge Single Page Application
by
Naoki Yamada
Akira shibata at developer summit 2016
by
Akira Shibata
Sparkで始めるお手軽グラフデータ分析
by
Nagato Kasaki
Selenium boot campの紹介
by
Nozomi Ito
IT系女子集まれ!女子部カンファレンスvo.1 用スライド資料
by
Kazumi OHIRA
本当にあったApache Spark障害の話
by
x1 ichi
Disrupting Big Data with Apache Spark in the Cloud
by
Jen Aman
【18-C-5】C# で iOS/Androidアプリ開発 - Visual Studio 2015 + Xamarin + MVVMCross -
by
ShinichiAoyagi
モノづくりを楽しもう! ~ このデバイスとクラウドでできること
by
Kazumi OHIRA
Kafka 0.10.0 アップデート、プロダクション100ノードでやってみた #yjdsnight
by
Yahoo!デベロッパーネットワーク
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
Apache Atlasの現状とデータガバナンス事例 #hadoopreading
by
Yahoo!デベロッパーネットワーク
Spark as a Platform to Support Multi-Tenancy and Many Kinds of Data Applicati...
by
Spark Summit
Top 5 mistakes when writing Spark applications
by
hadooparchbook
クラウドを使ったデザイン データ活用 - Autodesk Forge ご紹介 @ デブサミ 2016
by
Isezaki Toshiaki
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
我が家のフロントエンド開発事情
by
Naoki Yamada
Sparkでレコメンドエンジンを作ってみた
by
fujita_s
Java script.trend(spec)
by
dynamis
Similar to Apache Sparkを利用した「つぶやきビッグデータ」クローンとリコメンドシステムの構築
PPTX
Spark Streamingを使ってみた ~Twitterリアルタイムトレンドランキング~
by
sugiyama koki
PPTX
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PDF
Spark Streaming Snippets
by
Koji Agawa
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PPTX
2015 03-12 道玄坂LT祭り第2回 Spark DataFrame Introduction
by
Yu Ishikawa
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
PDF
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
PDF
Apache Sparkの紹介
by
Ryuji Tamagawa
PPT
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
PDF
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
PDF
[Oracle big data jam session #1] Apache Spark ことはじめ
by
Kenichi Sonoda
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
Yifeng spark-final-public
by
Yifeng Jiang
PDF
MapReduceを置き換えるSpark 〜HadoopとSparkの統合〜 #cwt2015
by
Cloudera Japan
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
Spark Streamingを使ってみた ~Twitterリアルタイムトレンドランキング~
by
sugiyama koki
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
Spark Streaming Snippets
by
Koji Agawa
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
2015 03-12 道玄坂LT祭り第2回 Spark DataFrame Introduction
by
Yu Ishikawa
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
Apache Sparkの紹介
by
Ryuji Tamagawa
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
[Oracle big data jam session #1] Apache Spark ことはじめ
by
Kenichi Sonoda
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
Yifeng spark-final-public
by
Yifeng Jiang
MapReduceを置き換えるSpark 〜HadoopとSparkの統合〜 #cwt2015
by
Cloudera Japan
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
More from Junichi Noda
PPTX
とらのあなエンジニア採用イベント 2017年2月9日
by
Junichi Noda
PPTX
[Anitech] ITでアニメを考える、「ShangriLa Meetup5」
by
Junichi Noda
PPTX
アニメ聖地デザインパターン
by
Junichi Noda
PPTX
アニメ聖地巡礼についてのアイデアソンテンプレート
by
Junichi Noda
PPTX
アイデアスケッチ テンプレート
by
Junichi Noda
PPTX
ITを使った今時の聖地巡礼ユーザー分析 in 沼津
by
Junichi Noda
PPTX
ラブライブ!サンシャイン!!入門書 (A4 縦向き)
by
Junichi Noda
PPTX
法規制後でも個人で楽しむ ドローン入門 2016・秋
by
Junichi Noda
PPTX
ラブライブ✕沼津 アニメタイアップについて
by
Junichi Noda
PPTX
Word2Vec Neologdで作るアニメ人工知能
by
Junichi Noda
PPTX
せいまち〜聖地探訪に出会いを求めるのは間違っているだろうか〜
by
Junichi Noda
PPTX
秋葉原IT戦略研究所のご紹介(2016/05/04)
by
Junichi Noda
PPTX
日本のアニメ産業を爆速させるアニメAPIの開発と活用事例 (ニコニコ超会議2016 大和証券ステージ)
by
Junichi Noda
PPTX
ShangriLa Anime APIを利用してアニメ関連のビッグデータ解析を最速で行う
by
Junichi Noda
PPTX
機械学習ライブラリ「Spark MLlib」で作る アニメレコメンドシステム ver 1.1
by
Junichi Noda
PPTX
機械学習ライブラリ「Spark MLlib」で作る アニメレコメンドシステム
by
Junichi Noda
PPTX
秋葉原IT戦略研究所のご紹介
by
Junichi Noda
PPTX
秋葉原IT戦略研究所のREAL~コミュニティ立ち上げから半年間の成果~
by
Junichi Noda
PDF
アカリクVol7 「アドテク」gmoアドパートナーズ株式会社
by
Junichi Noda
PDF
最新!2015年 クラウドAI プラットフォーム比較 AzureML & AmazonML
by
Junichi Noda
とらのあなエンジニア採用イベント 2017年2月9日
by
Junichi Noda
[Anitech] ITでアニメを考える、「ShangriLa Meetup5」
by
Junichi Noda
アニメ聖地デザインパターン
by
Junichi Noda
アニメ聖地巡礼についてのアイデアソンテンプレート
by
Junichi Noda
アイデアスケッチ テンプレート
by
Junichi Noda
ITを使った今時の聖地巡礼ユーザー分析 in 沼津
by
Junichi Noda
ラブライブ!サンシャイン!!入門書 (A4 縦向き)
by
Junichi Noda
法規制後でも個人で楽しむ ドローン入門 2016・秋
by
Junichi Noda
ラブライブ✕沼津 アニメタイアップについて
by
Junichi Noda
Word2Vec Neologdで作るアニメ人工知能
by
Junichi Noda
せいまち〜聖地探訪に出会いを求めるのは間違っているだろうか〜
by
Junichi Noda
秋葉原IT戦略研究所のご紹介(2016/05/04)
by
Junichi Noda
日本のアニメ産業を爆速させるアニメAPIの開発と活用事例 (ニコニコ超会議2016 大和証券ステージ)
by
Junichi Noda
ShangriLa Anime APIを利用してアニメ関連のビッグデータ解析を最速で行う
by
Junichi Noda
機械学習ライブラリ「Spark MLlib」で作る アニメレコメンドシステム ver 1.1
by
Junichi Noda
機械学習ライブラリ「Spark MLlib」で作る アニメレコメンドシステム
by
Junichi Noda
秋葉原IT戦略研究所のご紹介
by
Junichi Noda
秋葉原IT戦略研究所のREAL~コミュニティ立ち上げから半年間の成果~
by
Junichi Noda
アカリクVol7 「アドテク」gmoアドパートナーズ株式会社
by
Junichi Noda
最新!2015年 クラウドAI プラットフォーム比較 AzureML & AmazonML
by
Junichi Noda
Apache Sparkを利用した「つぶやきビッグデータ」クローンとリコメンドシステムの構築
1.
Apache Sparkを利用した 「つぶやきビッグデータ」クローンと リコメンドシステムの構築 GMOインターネット 次世代システム研究室 野田純一
2.
Overview 1.自己紹介 2.目的 3.Sparkについて 4.Spark Streamingについて 5.検証サービス説明 6.Spark Streamingを使用したオンラインTwitter解析によ るレコメンドシステム
「Mikasa」-三笠 7.まとめ
3.
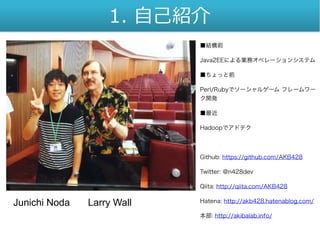
1. 自己紹介 ■結構前 Java2EEによる業務オペレーションシステム ■ちょっと前 Perl/Rubyでソーシャルゲーム フレームワー ク開発 ■最近 Hadoopでアドテク Github:
https://github.com/AKB428 Twitter: @n428dev Qiita: http://qiita.com/AKB428 Hatena: http://akb428.hatenablog.com/ 本部: http://akibalab.info/ Junichi Noda Larry Wall
4.
• Sparkについて少し執筆しました • 「Software
Design 2015年11月号」 • ConoHaを使ったHadoopクラスタの構成例と SparkSQLをつかったデータ処理の実例が記載。
5.
5 ↓これが作りたい 2014 7月22日 NHK
NEWS WEB 2. 目的
6.
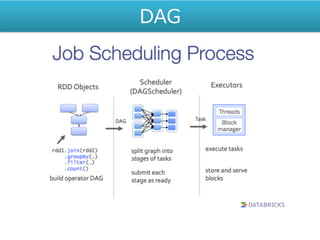
• HadoopのMapReduceとは別アプローチ(DAG)での並列 分散集計処理を行う • インメモリー処理 •
Hadoopエコシステムの一部として扱われるがHadoopと直 接的な関係はない • APIを利用できる言語はScala, Java, Python 3. Sparkについて
7.
5. Sparkについて 〜Spark処理でのDAG DAG
8.
• http://itpro.nikkeibp.co.jp/atcl/column/14/1226001 37/122600004/?ST=bigdata&P=3
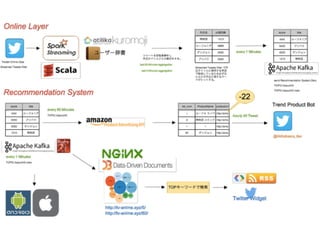
9.
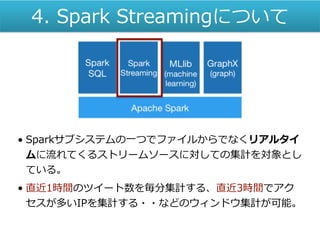
いて • Sparkサブシステムの一つでファイルからでなくリアルタイ ムに流れてくるストリームソースに対しての集計を対象とし ている。 • 直近1時間のツイート数を毎分集計する、直近3時間でアク セスが多いIPを集計する・・などのウィンドウ集計が可能。 4.
Spark Streamingについて
10.
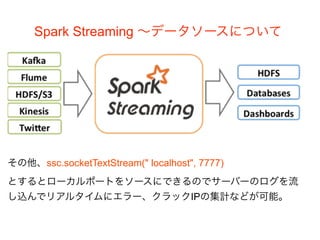
Spark Streaming 〜データソースについて その他、ssc.socketTextStream("
localhost", 7777) とするとローカルポートをソースにできるのでサーバーのログを流 し込んでリアルタイムにエラー、クラックIPの集計などが可能。
11.
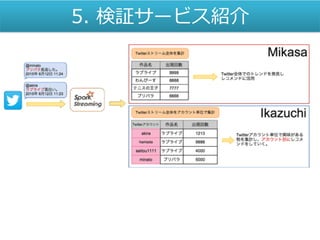
5. 検証サービス紹介
12.
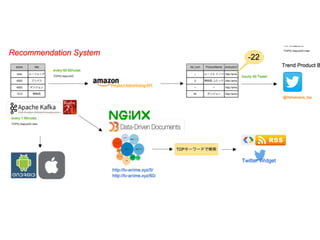
4. Spark Streamingを使用したオンライン Twitter解析によるレコメンドシステム
「 Mikasa」-三笠 https://github.com/AKB428/mikasa_ol https://github.com/AKB428/mikasa_rs
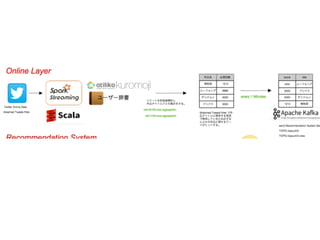
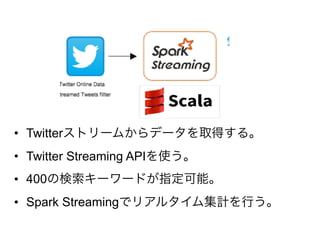
16.
• Twitterストリームからデータを取得する。 • Twitter
Streaming APIを使う。 • 400の検索キーワードが指定可能。 • Spark Streamingでリアルタイム集計を行う。
17.
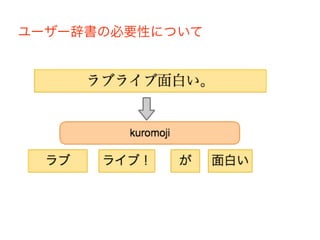
• 日本語文章を単語にわけて分解して集計 • 日本語を分解するため形態素解析ライブラリ kuromojiを使う。 •
アニメ作品など標準辞書にない単語はユーザー辞 書(CSV)を用意。
18.
形態素解析ライブラリの必要性について
19.
ユーザー辞書の必要性について
20.
Spark Streamingによるウィンドウ集計の活用 Mikasaは直近5分、直近60分のデータ集計を毎 分行っている。(合計60*2=120回) 少ないソースコードで、ウィンドウ集計が可能 。
21.
• ソースコード • https://github.com/AKB428/mikasa_ol/blob/maste r/src/main/scala/mikasa.scala
23.
画面デモ(直近5分を毎分集計) (F1)2015年4期 TVアニメ http://tv-anime.xyz/5/ (F1)2016年1期
TVアニメ http://akiba-net.com/5/ (F2)ラブライブ http://lovelive-net.com/5/ (F2)デブサミ http://2045.tokyo/5/ (F2)関東TV番組 http://telev.net/5/ F1=ユーザー辞書に登録してある単語のみ集計 F2=ユーザー辞書外の単語も集計
24.
画面デモ(直近60分を毎分集計) (F1)2015年2期 TVアニメ http://tv-anime.xyz/60/ (F1)ラブライブ
http://tv-anime.biz/60/ (F2)ラブライブ http://lovelive-net.com/60/ (F2)秋葉原 http://akiba-net.com/60/ (F2)関東TV番組 http://telev.net/60/ F1=ユーザー辞書に登録してある単語のみ集計 F2=ユーザー辞書外の単語も集計
25.
画面デモ 過去の履歴キャプチャ
26.
26
27.
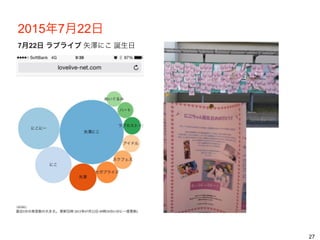
2015年7月22日 7月22日 ラブライブ 矢澤にこ
誕生日 27
28.
28 2015年7月22日
29.
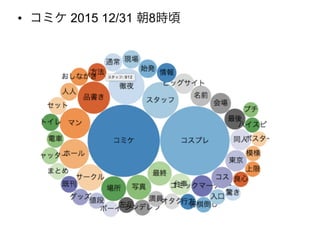
• コミケ 2015
12/31 朝8時頃
30.
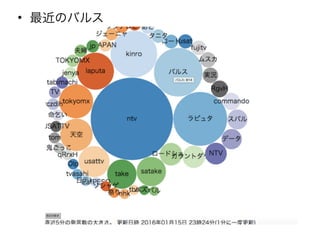
• 最近のバルス
31.
31 京都OSC用 つぶやきビックデータ 検索ハッシュタグ 「#osckansai」 http://2045.tokyo/5/ http://2045.tokyo/60/ ※URLの内容は8/8当日のみ 京都OSC用になります
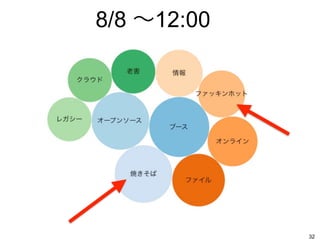
32.
8/8 〜12:00 32
33.
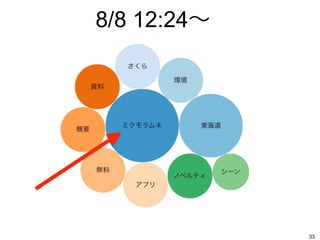
8/8 12:24〜 33
34.
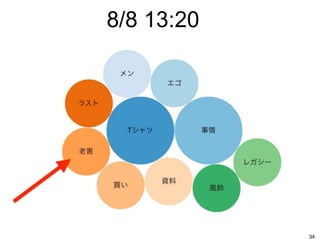
8/8 13:20 34
35.
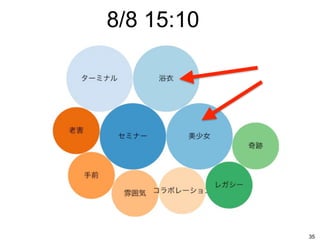
8/8 15:10 35
36.
8/8 15:20 36
37.
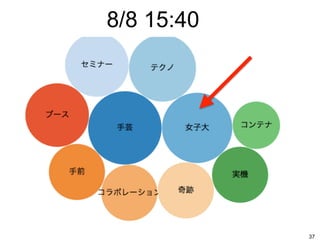
8/8 15:40 37
38.
8/8 16:10 38
39.
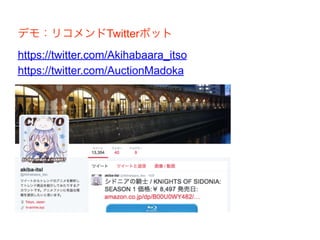
デモ:リコメンドTwitterボット https://twitter.com/Akihabaara_itso https://twitter.com/AuctionMadoka
40.
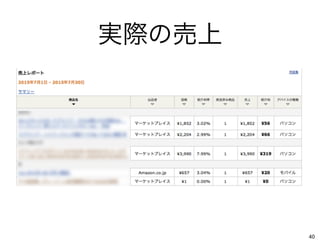
実際の売上 40
41.
サーバーデモ 動作中のサーバーのコンソールを公開
42.
• Mikasa Twitter
のデータ収集解析の2つのアプロ ーチについて • ①Twitter Filter + ユーザー辞書のみの単語で絞る • 1のメリット▶集計しやすい、後続の処理も設計しや すい。 • 1のデメリット▶未知の単語を拾えない、ユーザー辞 書にひもづく別のワードを拾えない • 結論:ある程度、解析対象のドメインが固定されて いるものにはこのアプローチは有効
43.
• ② Twitter
Filter + ユーザー辞書を使いつつ全ての単語を集計 • メリット▶ 未知のワードが拾える、リアルなネットワーク解 析ができる。 • デメリット▶ ジャンクワードが多く出現するのでデータクレ ンジングの作業にコストがかかる。 • 結論:解析対象が不明なドメインの場合、まずこのアプローチ で回す。計測対象のネットワークが変動しやすいドメインの場 合はこのアプローチが有効。ある程度アプローチ2で回してア プローチ1に切り替える、もしくはアプローチ1を追加した二 段のサービスに設計する。
44.
Spark Streaming 〜ソースコード補足 •
TwitterUtilは実体はJavaのTwitterライブラリで あるtwitter4j • Twitter解析にはTwitterAPI特有のAPIレートリ ミット、単一IPによる高負荷時のアクセス制 限があるので注意 • Twitter開発者アカウントには電話番号が必須 になったので気軽に開発はできなくなりつつ ある。
45.
Mikasaインストールについて インストールマニュアル https://gist.github.com/AKB428/c30bc6a979e05fa3a022 • TwitterAPIとAmazonAPIのアカウントがあれば1時間でセッ トアップ完了。 • AmazonAPIはリコメンドしない場合は不要。 •
TwitterAPIのアカウント取得も10分程度で可能。 Mikasa OL https://github.com/AKB428/mikasa_ol Mikasa RS https://github.com/AKB428/mikasa_rs
46.
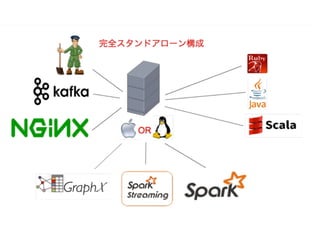
• 作ったシステムはスタンドアロンでも安定して動く( 4ヶ月放置しても安定動作 Spark1.4、Spark1.5) •
視覚的にわかりやすい、作りやすいのでSpark入門用 の教材に最適、会社ではインターン生にCDH、HDPク ラスタを構築してもらい、クラスタ上で動作するよう 作ってもらったりしている。(分散処理を体験したい 学生向け) • イベントのハッシュタグを監視し、イベントの展示モ ニタなどに使うといい感じ。(OSCでは実際使っても らっている。 6.まとめ
47.
コミュニティブースやっています! IT系の同人誌を売っています。 つぶやきビッグデータクローンのデモもあるので 是非お立ち寄りください
48.
ご清聴ありがとうございました あんず&このは LINEスタンプ発売中
Download
























































































![[Oracle big data jam session #1] Apache Spark ことはじめ](https://cdn.slidesharecdn.com/ss_thumbnails/oraclebigdatajamsession1apachesparkquickstart-191127094941-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Anitech] ITでアニメを考える、「ShangriLa Meetup5」](https://cdn.slidesharecdn.com/ss_thumbnails/anitechitshangrilameetup5-170128172553-thumbnail.jpg?width=640&height=640&fit=bounds)

















