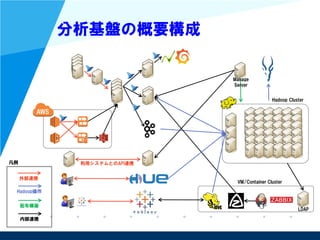
前提:niconicoの概要
MAU 約919万
ID発行数 約6210万
有料会員約252万
ユーザアクション
- コンテンツ視聴
- コンテンツ投稿
- コメント
- マイリスト
- お気に入り
- タグ編集
ユーザ
アクション
ファミリー
サービス
アクセス
デバイス
動画
静画
マンガ
電子書籍
生放送
チャンネル
アプリ
ブロマガ
立体
大百科
市場
ニコニ広告
実況
コモンズ
コミュニティ
ニュース
ニコナレ
RPGアツマール
PC
iOS
Android
SPモード
Xbox One
3DS
PS4
Vii U
PS Vita
光Box+
PS Vita TV
ビエラ
TV Box
Fire TV
LG TV
Gear VR
7.
前提:niconicoの概要
MAU 約919万
ID発行数 約6210万
有料会員約252万
ユーザアクション
- コンテンツ視聴
- コンテンツ投稿
- コメント
- マイリスト
- お気に入り
- タグ編集
ユーザ
アクション
ファミリー
サービス
アクセス
デバイス
動画
静画
マンガ
電子書籍
生放送
チャンネル
アプリ
ブロマガ
立体
大百科
市場
ニコニ広告
実況
コモンズ
コミュニティ
ニュース
ニコナレ
RPGアツマール
PC
iOS
Android
SPモード
Xbox One
3DS
PS4
Vii U
PS Vita
光Box+
PS Vita TV
ビエラ
TV Box
Fire TV
LG TV
Gear VR
- 多様なユーザアクション
- 多様なファミリーサービス
- 多様なアクセスデバイス
これらが同一ユーザID体系の上で行われる。