Downloaded 178 times







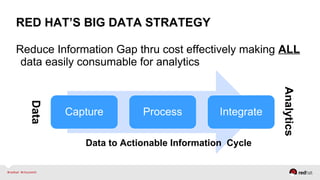

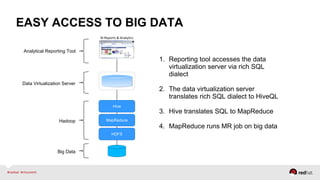
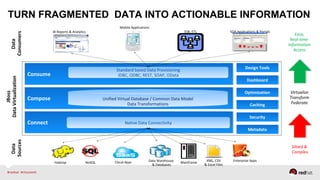

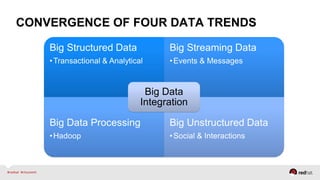




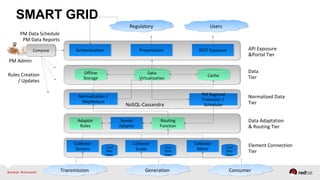
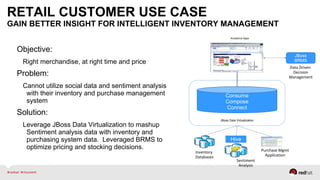




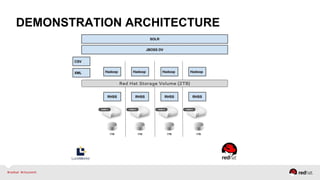


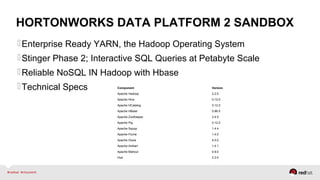

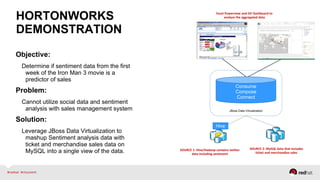

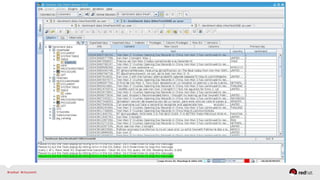








The document discusses Red Hat's approach to leveraging big data through data virtualization, emphasizing its role in democratizing access to data and improving business insights. It outlines real-world applications, such as enhancing inventory management and optimizing smart grid projects, by integrating various data sources seamlessly. The presentation also highlights the benefits of using JBoss Data Virtualization to increase time-to-market for reports and facilitates better decision-making through comprehensive middleware solutions.



































![[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015e26couchbaseandjbossdatavirtualization-150616073132-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


































































