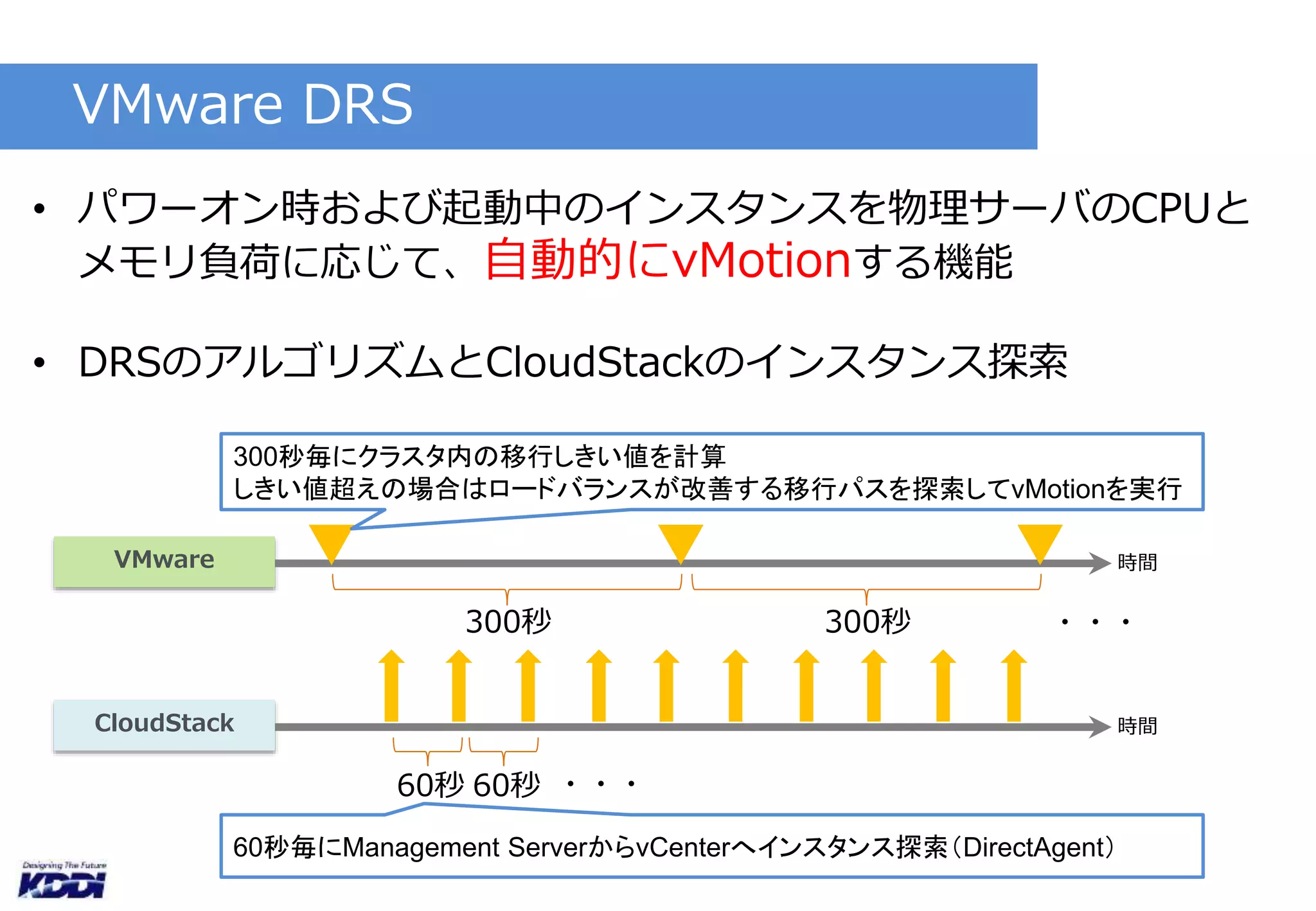
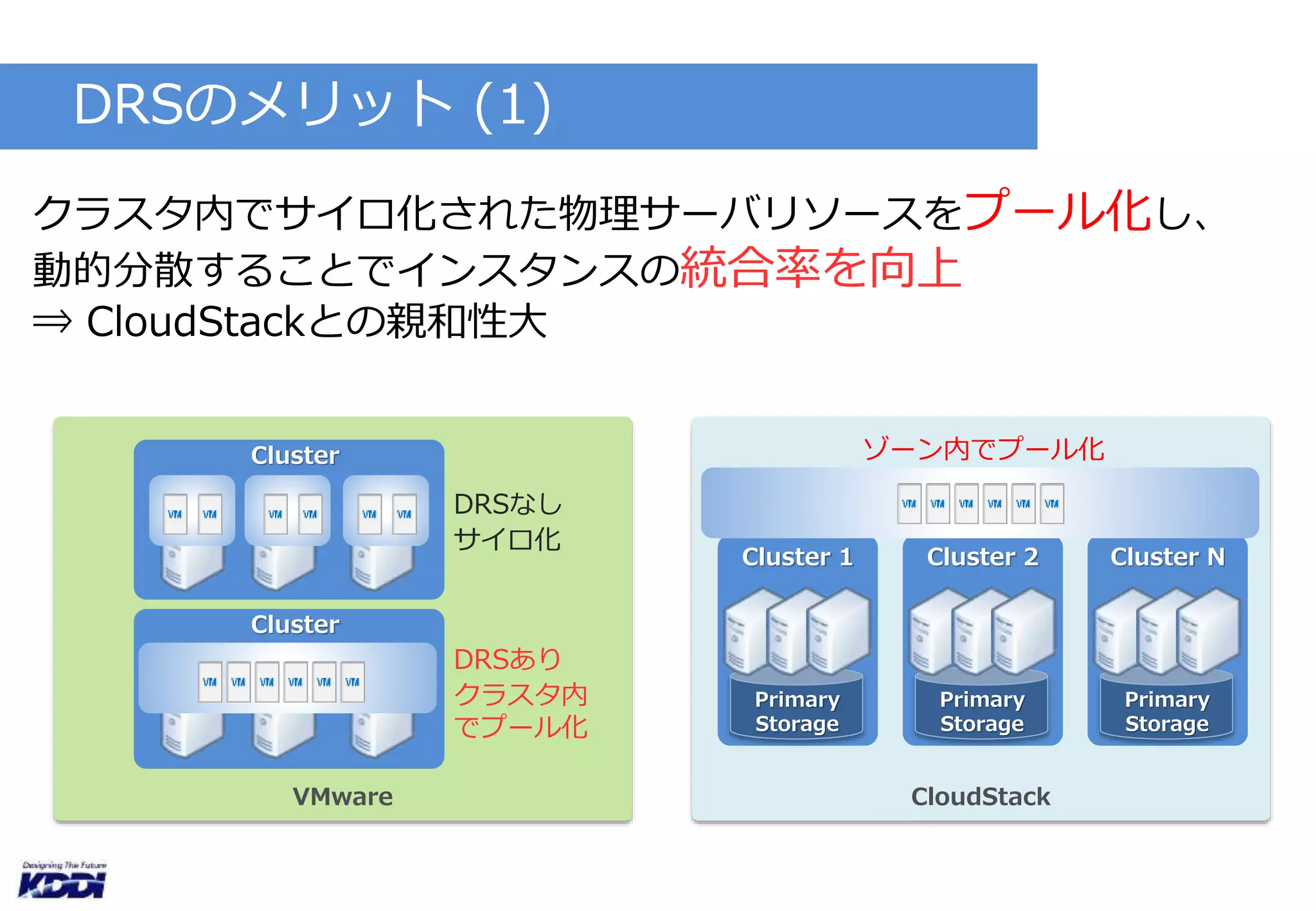
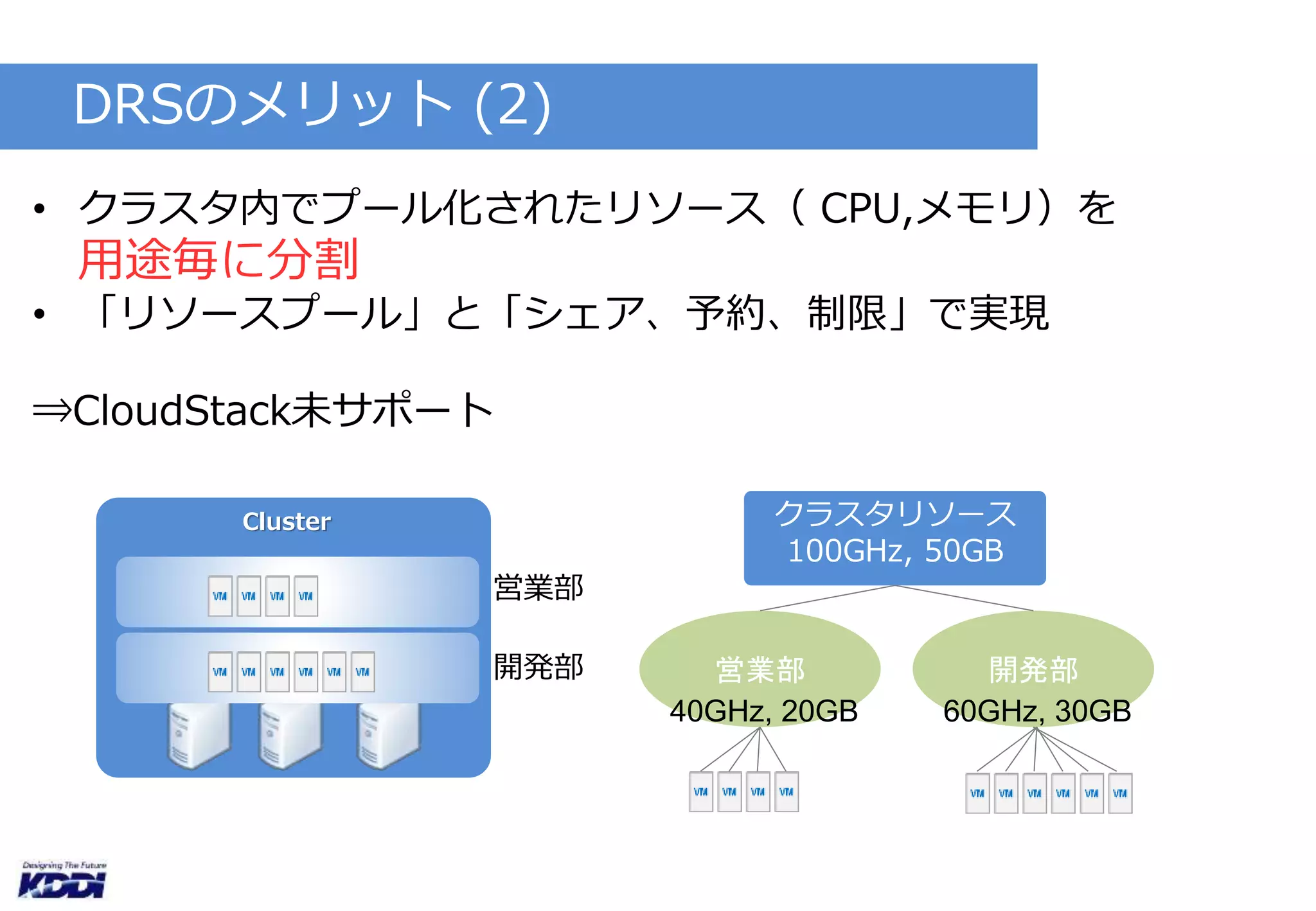
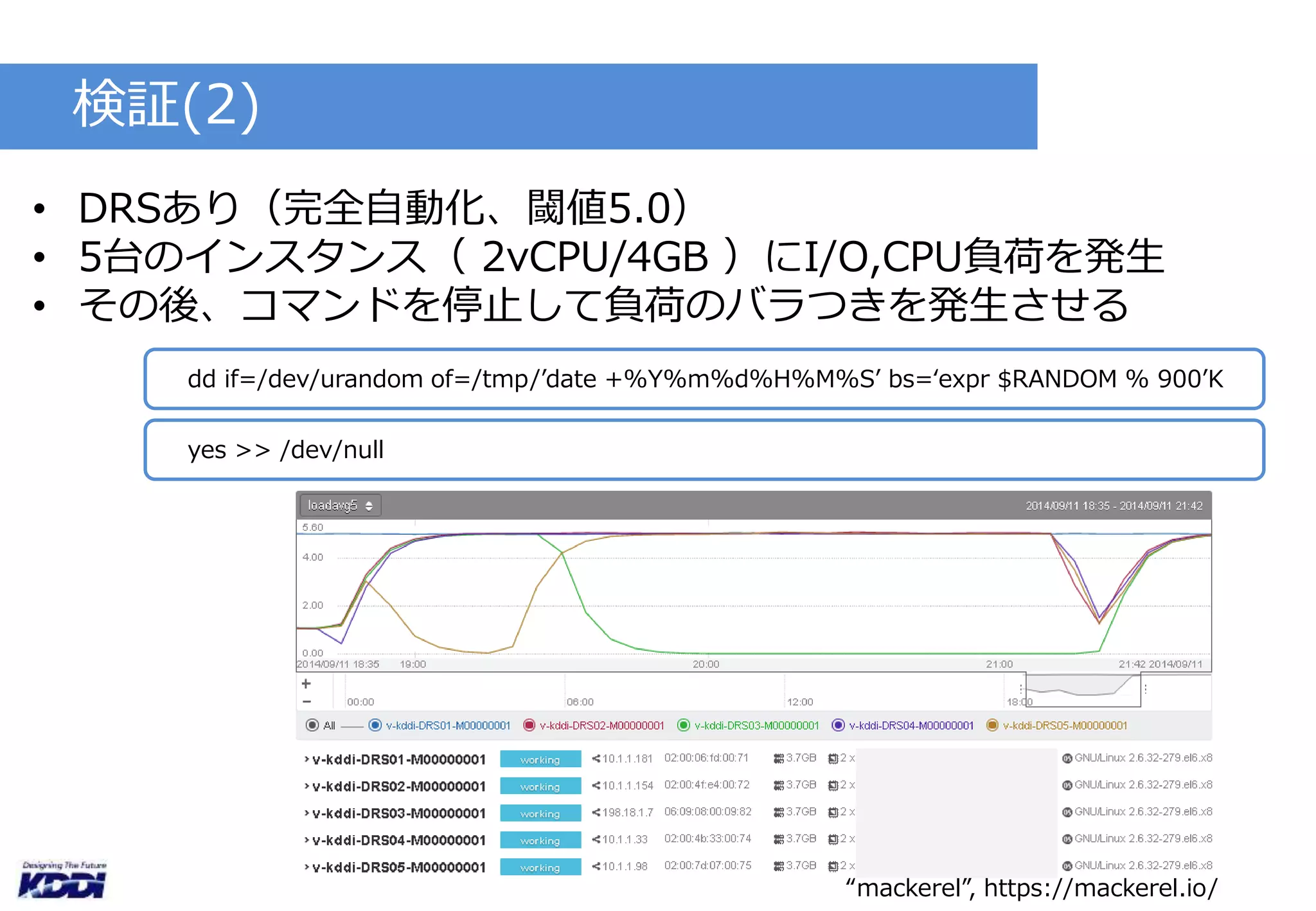
検証(1)
• DRSなし
• vCenterで2vCPU/4GBのインスタンスを手動vMotion
17:25:39 vMotion開始
17:25:57 vMotion完了
17:26:34,313 (DirectAgent) Detecting a new state but couldn't find a old state so adding it to the
changes
17:26:36,708 (DirectAgent) VM is now missing from host report but we detected that it might be
migrated to other host by vCenter
17:26:36,708 (DirectAgent) VM is now missing from host report and VM is not at
starting/migrating state, remove it from host VM-sync map, oldState: Running
17:27:17,526 (DirectAgent:”物理サーバ名”) find VM on host
(management-server.log一部抜粋)
vMotion完了から約2分未満でCloudStackがインスタンスを検知
検証(2 cont,)
18:545号機のインスタンスのI/O,CPU負荷を停止
19:01 2号機がDRSで他方のホストへvMotion
19:01:34,311 (DirectAgent) Detecting a new state but couldn't find a old state so adding it to the
changes
19:01:37,192 (DirectAgent) VM is now missing from host report but we detected that it might be
migrated to other host by vCenter
19:01:37,192 (DirectAgent) VM is now missing from host report and VM is not at
starting/migrating state, remove it from host VM-sync map, oldState: Running
19:02:03,481 (DirectAgent:”物理サーバ名”) find VM on host
19:02:03,481 (DirectAgent:”物理サーバ名”) VM found in host cache
(management-server.log一部抜粋)
vMotion完了から約2分未満でCloudStackがインスタンスを検知
“mackerel”, https://mackerel.io/
10.
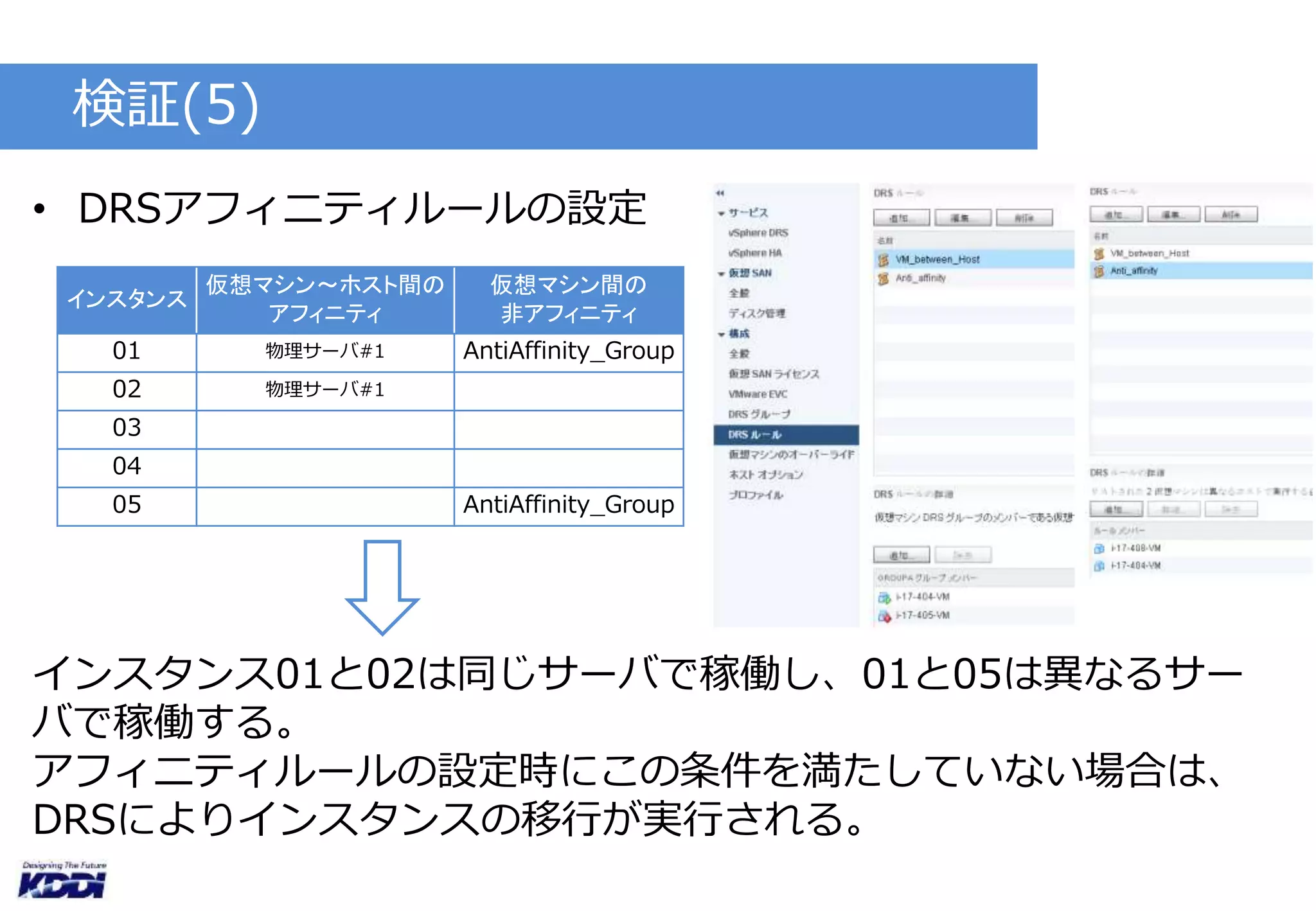
検証(3)
• DRSあり(完全自動化、閾値5.0)
• 5台のインスタンス( 2vCPU/4GB )にI/O,CPU負荷を発生
• 任意のインスタンスでVMスナップショットとボリュームスナッ
プショットを取得
19:36:34,347 (DirectAgent) Detecting a new state but couldn't find a old state so adding it to the
changes
19:36:34,347 (DirectAgent) VM is now missing from host report but we detected that it might be
migrated to other host by vCenter
19:01:37,192 (DirectAgent) VM is now missing from host report and VM is not at
starting/migrating state, remove it from host VM-sync map, oldState: Running
19:36:42,870 (DirectAgent:”物理サーバ名”) find VM on host
19:36:42,870 (DirectAgent:”物理サーバ名”) VM found in host cache
(management-server.log一部抜粋)
VMスナップショットを取得したインスタンス、ボリュー
ムスナップショット取得中のインスンタンスがDRSの移行対象
となりvMotionが実行される。
11.
検証(4)
• インスタンスの移行時のログでストップコマンドの実行が出力
される場合がある。
• ログ出力時にインスタンスの停止は未発生。
17:34:34,343 (DirectAgent) VM is now missing from host report but we detected that it might be
migrated to other host by vCenter
17:34:34,343 (DirectAgent) VM is now missing from host report and VM is not at
starting/migrating state, remove it from host VM-sync map, oldState: Running
17:34:34,439 INFO (DirectAgent) VM is at Running and we received a power-off report while
there is no pending jobs on it
17:34:34,441 Sending "com.cloud.agent.api.StopCommand“
17:34:34,441 Executing "com.cloud.agent.api.StopCommand"
17:34:34,441 Executing resource StopCommand:
17:34:34,458 find VM on host
17:34:34,458 VM not found in host cache
(management-server.log一部抜粋)