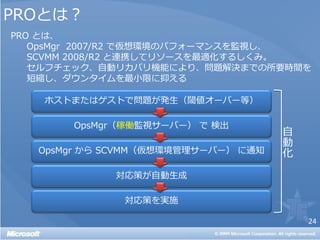
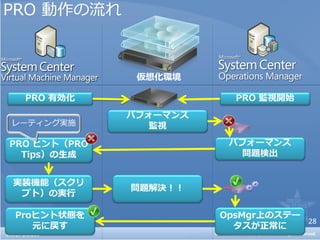
PRO モニター 一覧
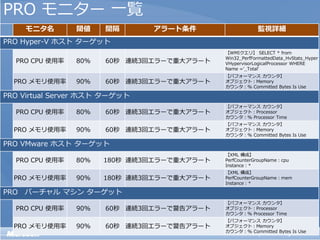
モニタ名 閾値 間隔 アラート条件 監視詳細
PRO Hyper-V ホスト ターゲット
【WMIクエリ】 SELECT * from
Win32_PerfFormattedData_HvStats_Hyper
PRO CPU 使用率 80% 60秒 連続3回エラーで重大アラート VHypervisorLogicalProcessor WHERE
Name ='_Total'
【パフォーマンス カウンタ】
PRO メモリ使用率 90% 60秒 連続3回エラーで重大アラート オブジェクト:Memory
カウンタ:% Committed Bytes Is Use
PRO Virtual Server ホスト ターゲット
【パフォーマンス カウンタ】
PRO CPU 使用率 80% 60秒 連続3回エラーで重大アラート オブジェクト:Processor
カウンタ:% Processor Time
【パフォーマンス カウンタ】
PRO メモリ使用率 90% 60秒 連続3回エラーで重大アラート オブジェクト:Memory
カウンタ:% Committed Bytes Is Use
PRO VMware ホスト ターゲット
【XML 構成】
PRO CPU 使用率 80% 180秒 連続3回エラーで重大アラート PerfCounterGroupName:cpu
Instance:*
【XML 構成】
PRO メモリ使用率 90% 180秒 連続3回エラーで重大アラート PerfCounterGroupName:mem
Instance:*
PRO バーチャル マシン ターゲット
【パフォーマンス カウンタ】
PRO CPU 使用率 90% 60秒 連続3回エラーで警告アラート オブジェクト:Processor
カウンタ:% Processor Time
【パフォーマンス カウンタ】 29
PRO メモリ使用率 90% 60秒 連続3回エラーで警告アラート オブジェクト:Memory
カウンタ:% Committed Bytes Is Use



![本日のテーマ
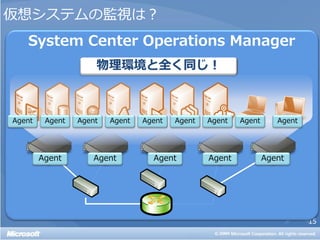
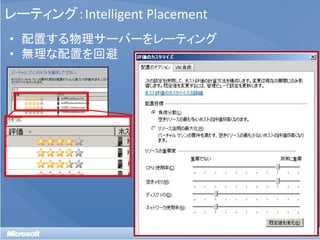
• [おさらい] 物理環境をどう監視するか?
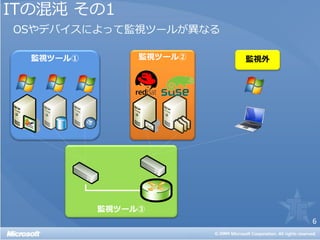
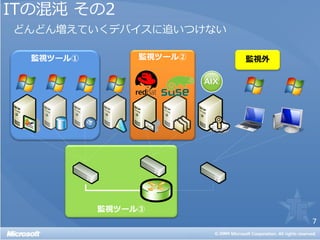
• 仮想環境を監視するには特別な手法が必要なのか?
• 仮想環境の監視は物理環境以上に面倒なのか?
2](https://image.slidesharecdn.com/20091211junichia-091215030232-phpapp01/85/System-Center-Operations-Manager-2-320.jpg)

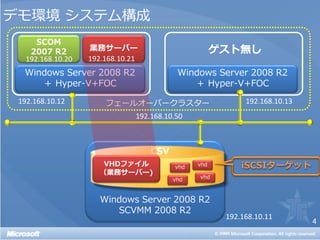





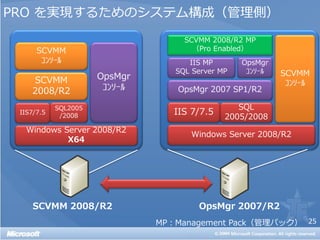
![Live Migration の実行方法
• クラスターノードを停止する
• [フェールオーバークラスター]管理コンソール
• Virtual Machine Manager 管理コンソール
• Windows PowerShell コマンドレット
20](https://image.slidesharecdn.com/20091211junichia-091215030232-phpapp01/85/System-Center-Operations-Manager-20-320.jpg)
![PowerShell で Live Migration
クラスターグループ「CLUSTERGRP」クラスタノード「NODE-A」から
「NODE-B」に仮想マシン「GYOUMU」を移動する場合
方法1:フェールオーバークラスターのコマンドレットを使用
PS>Get-Cluster CLUSTERGRP | Move-ClusterVirtualMachineRole –Name “GYOMU”
-Node “NODE-B”
方法2:Virtual Machine Managerのコマンドレットを使用
PS>$VM = Get-VM –Name “GYOMU” | Where {$_.VMHost.Name –eq “NODE-A”}
PS>$GUID = [guid]::NewGUID()
PS>$VMHOST = Get-VMHost | Where {$_.Name –eq “NODE-B”}
PS>MOVE-VM –vm $VM –vmhost $VMHOST –RunAsynchronously –jobgroup $GUID
21](https://image.slidesharecdn.com/20091211junichia-091215030232-phpapp01/85/System-Center-Operations-Manager-21-320.jpg)












![MOVで実践したサーバーAPI実装の超最適化について [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevera-191031084650-thumbnail.jpg?width=640&height=640&fit=bounds)



























































