Download as PDF, PPTX




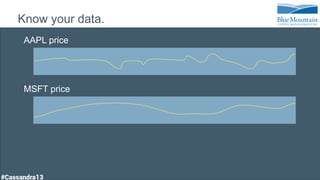
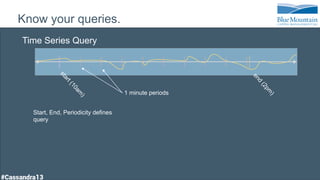
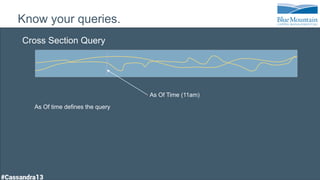
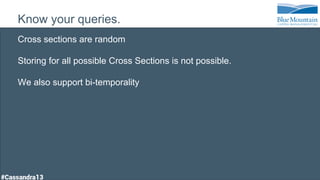




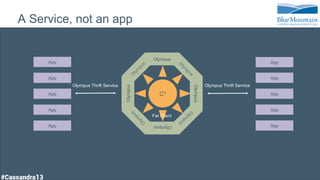

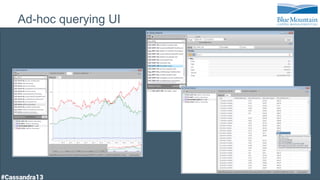




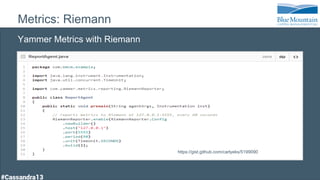

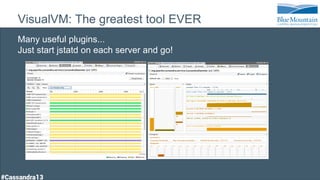



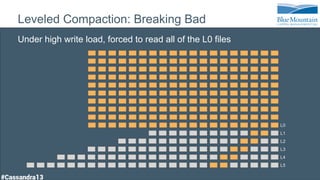
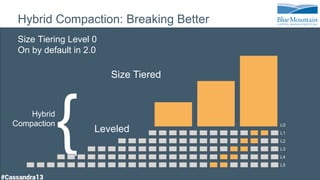




The document discusses a financial time series architecture used by BlueMountain Capital to handle a high volume of queries across data centers efficiently. It outlines the data model and query optimization techniques for time series data while detailing challenges in scaling, including performance tuning and specific changes made to Cassandra. Metrics handling and monitoring using Riemann and other tools are emphasized to ensure system performance and reliability.





























![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
























































