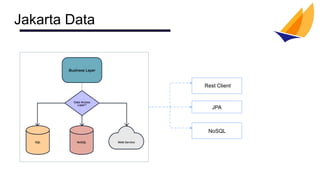
This document discusses NoSQL databases and Jakarta Data, which aims to unify data access. It provides examples of using Jakarta Data annotations to define entities, repositories, and queries for NoSQL databases. Key features discussed include basic CRUD operations, named parameters, sorting, pagination, and keyset pagination to improve efficiency. A demo of Jakarta Data on Open Liberty is referenced that implements entities, repositories, and services for accessing crew member data.











![Document stores
{
"name":"Diana",
"duty":[
"Hunt",
"Moon",
"Nature"
],
"siblings":{
"Apollo":"brother"
}
}
ApacheCouchDB
MongoDB
Couchbase](https://image.slidesharecdn.com/jakartadata-jcon-230620092446-799ab785/85/JakartaData-JCon-pptx-12-320.jpg)














![Query by Text
@MongoFindQuery(filter = "{title:{$regex: :t}}", sort = "{title: 1}")
List<Book> customFind(String t);
@MongoAggregateQuery("[{$match: {name:{$regex: :t}}}, {$sort: {name: 1}}, {$project:
{name: 1}}]")
List<Person> customAggregate(String t);
@MongoUpdateQuery(filter = "{title:{$regex: :t}}", update = "{$set:{name: 'tom'}}")
List<Book> customUpdate(String t);
@MongoDeleteQuery(filter = "{title:{$regex: :t}}", collation = "{locale:'en_US',
numericOrdering:true}")
void customDelete(String t);](https://image.slidesharecdn.com/jakartadata-jcon-230620092446-799ab785/85/JakartaData-JCon-pptx-29-320.jpg)






















![Name-Pattern Repository Methods
Compose your own save, findBy, deleteBy, countBy & more methods by
following precise naming conventions with reserved keywords and entity
property names within the method name.
Product[] findByNameLikeAndPriceBetween(String namePattern,
float minPrice,
float maxPrice);
find...By indicates a query returning results
And keyword separates NameLike and PriceBetween conditions
Name and Price are entity property names
Like keyword is a type of condition, requires 1 parameter
Between keyword is a type of condition, requires 2 parameters](https://image.slidesharecdn.com/jakartadata-jcon-230620092446-799ab785/85/JakartaData-JCon-pptx-54-320.jpg)


![Sorting of Results
Reserved keywords OrderBy, Asc, and Desc enable sorting of results.
Product[] findByNameLikeAndPriceBetweenOrderByPriceDescNameAsc(String namePattern,
float minPrice,
float maxPrice);
OrderBy keyword indicates the start of the sorting criteria
Asc keyword indicates ascending sort
Desc keyword indicates descending sort](https://image.slidesharecdn.com/jakartadata-jcon-230620092446-799ab785/85/JakartaData-JCon-pptx-57-320.jpg)
![Sorting of Results – better ways
@OrderBy(value = "price", descending = true)
@OrderBy("name")
Product[] findByNameLikeAndPriceBetween(String namePattern,
float minPrice,
float maxPrice);
Method names can get a bit lengthy, so there is also
@OrderBy annotation for sorting criteria that is known in advance
Sort parameters for dynamic sorting
Product[] findByNameLikeAndPriceBetween(String namePattern,
float minPrice,
float maxPrice,
Sort...);
found = products.findByNameLikeAndPriceBetween(namePattern, 10.00f, 20.00f,
Sort.desc("price"), Sort.asc("name"));](https://image.slidesharecdn.com/jakartadata-jcon-230620092446-799ab785/85/JakartaData-JCon-pptx-58-320.jpg)
![Without Method Name Magic?
@Filter(by = "price", op = Compare.Between)
@Filter(by = "name", fn = Function.IgnoreCase, op = Compare.Contains)
@OrderBy("price")
Product[] inPriceRange(float min, float max, String namePattern);
@Filter(by = "name")
@Update(attr = "price", op = Operation.Multiply)
boolean inflatePrice(String productName, float rate);
@Delete
@Filter(by = "reviews", op = Compare.Empty)
int removeUnreviewed();
It could be possible to define queries entirely with annotations.
• This idea was deferred to post v1.0, but Open Liberty has it working in
a prototype:
Javadoc:
https://ibm.biz/JakartaData](https://image.slidesharecdn.com/jakartadata-jcon-230620092446-799ab785/85/JakartaData-JCon-pptx-59-320.jpg)
![Limiting the Number of Results
@OrderBy("price")
Product[] findFirst10ByNameLike(String namePattern);
Sometimes you don’t want to read the entire matching dataset and only
care about the first several results.
First keyword indicates the start of the sorting criteria
10 numeric value optionally indicates how many.
When absent, only the very first result is returned.
Another way:
@OrderBy("price")
Product[] findByNameLike(String namePattern, Limit limit);
found = products.findByNameLike(namePattern, Limit.of(10));](https://image.slidesharecdn.com/jakartadata-jcon-230620092446-799ab785/85/JakartaData-JCon-pptx-60-320.jpg)




















































































