











![Data Mining Tasks
Classification [Predictive]
Clustering [Descriptive]
Association Rule Discovery [Descriptive]
Sequential Pattern Discovery [Descriptive]
Regression [Predictive]
Deviation Detection [Predictive]](https://image.slidesharecdn.com/itsallaboutdatamining-101029094247-phpapp01/85/Its-all-about-data-mining-15-320.jpg)





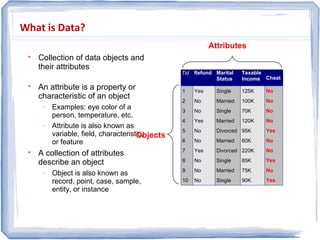



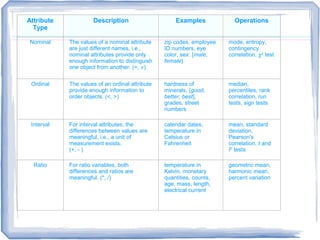







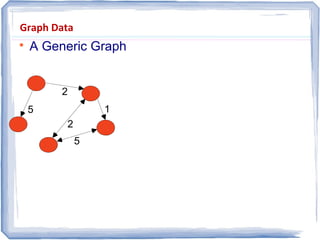
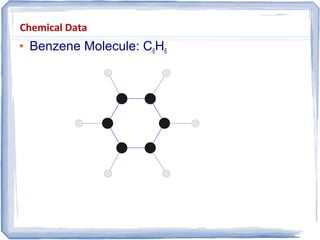
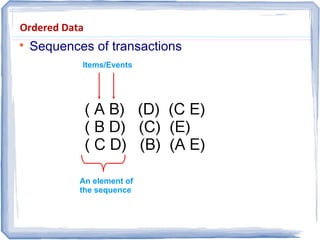

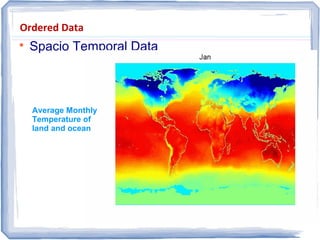

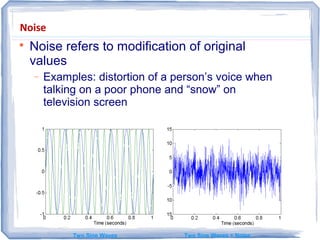





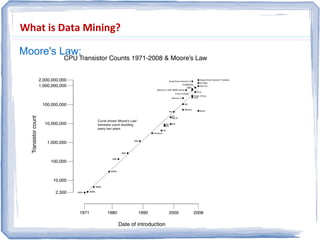
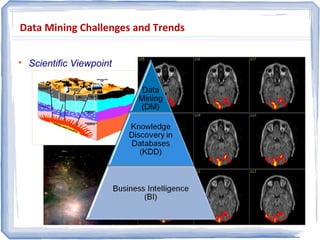
The document provides an overview of data mining, including: 1) It defines data mining as the process of extracting patterns from large datasets that are valid, novel, useful and understandable. 2) It discusses some of the challenges of data mining like dealing with noise and missing data and not overfitting models. 3) It outlines several common data mining tasks like classification, clustering, association rule mining and sequential pattern mining.


































![Wk. 3. Data [12-05-2021] (2).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/wk-240205070901-8f81e253-thumbnail.jpg?width=640&height=640&fit=bounds)





































