Downloaded 63 times



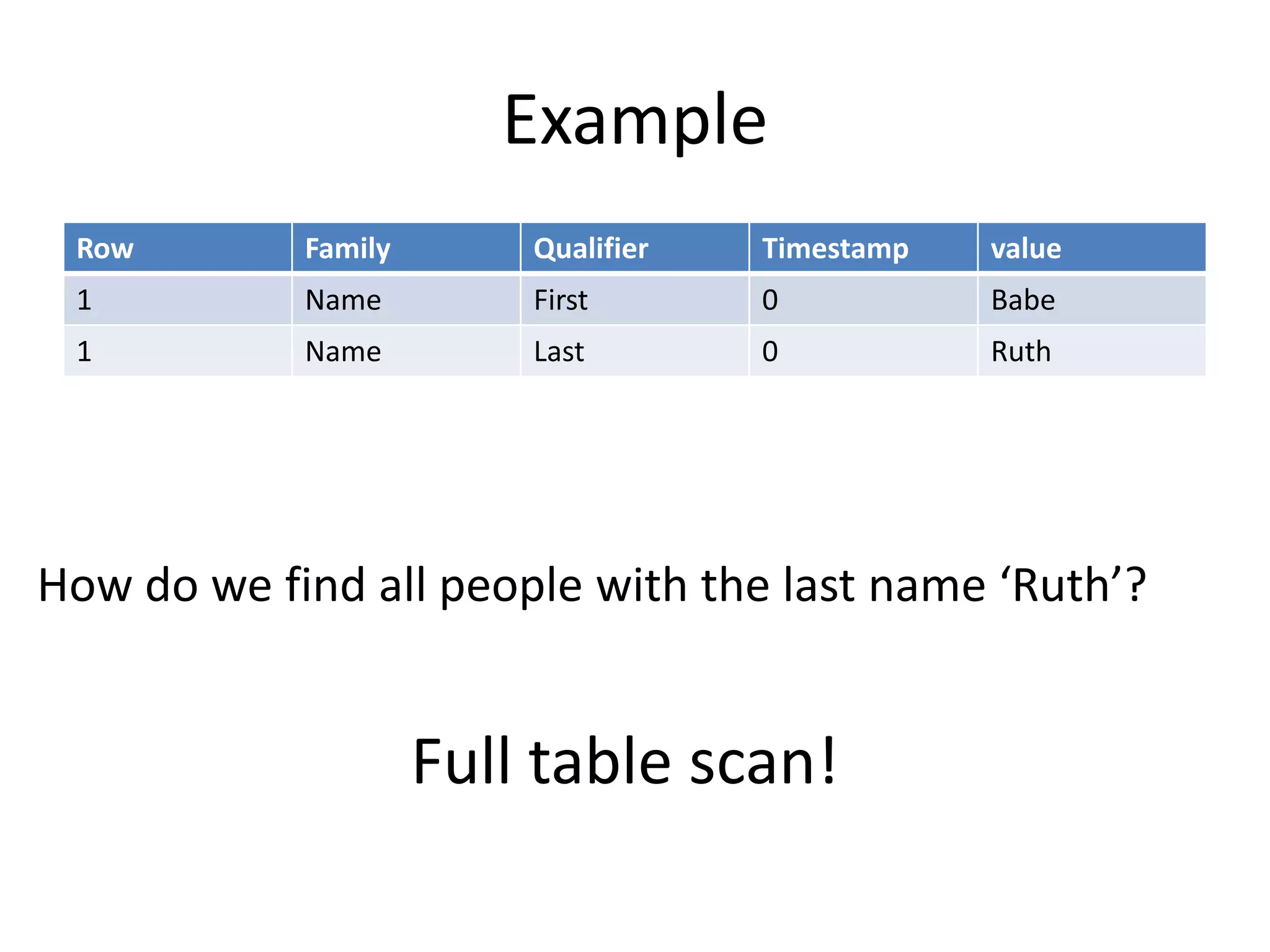




























The document discusses secondary indexing in HBase, addressing challenges in efficiently performing lookups deeper than row keys and proposing various implementations like Omid and Percolator. It highlights the need for flexible indexing strategies tailored to specific data use cases, pointing out considerations for built-in vs. external libraries, index cardinality, and client-side management of indexes. The author emphasizes the importance of allowing users to choose their indexing methods while maintaining ease of use and performance.

















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















