Download as PDF, PPTX







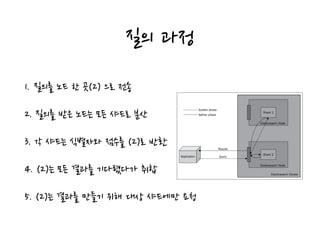
















The document discusses Elastic search queries. It covers the basic query process, types of queries including basic and complex queries. It then describes different methods for constructing queries including using URI parameters, request body JSON, and provides examples. It also outlines the standard request body structure and includes some common additional options like pagination.
![[제1회 루씬 한글분석기 기술세미나] solr로 나만의 검색엔진을 만들어보자](https://cdn.slidesharecdn.com/ss_thumbnails/1solr-130414211148-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


































































