Download as PDF, PPTX


















![Simple Agent
module MCollective
module Agent
class Printer<RPC::Agent
Printer
metadata :name => 'printer',
:description => 'Printers and printing',
:author => 'Gary Larizza',
:license => 'BSD',
:version => '0.1',
:url =>'http://puppetlabs.com',
:timeout => 100
action 'list'
'list' do
reply[:output] = `lpstat -a | cut -d ' ' -f 1
lpstat 1`.split("n")
end
end
end
end](https://image.slidesharecdn.com/mcollective-puppetslidesafe-111103124847-phpapp02/75/Introduction-to-Marionette-Collective-24-2048.jpg)
![Simple Agent
module MCollective
module Agent
class Printer<RPC::Agent
Printer
metadata :name => 'printer',
:description => 'Printers and printing',
:author => 'Gary Larizza',
:license => 'BSD',
:version => '0.1',
:url =>'http://puppetlabs.com',
:timeout => 100
action 'list'
'list' do
reply[:output] = `lpstat -a | cut -d ' ' -f 1
lpstat 1`.split("n")
end
end
end
end](https://image.slidesharecdn.com/mcollective-puppetslidesafe-111103124847-phpapp02/75/Introduction-to-Marionette-Collective-25-2048.jpg)
![Simple Agent
module MCollective
module Agent
Agent Name
class Printer<RPC::Agent
Printer
metadata :name => 'printer',
:description => 'Printers and printing',
:author => 'Gary Larizza',
:license => 'BSD',
:version => '0.1',
:url =>'http://puppetlabs.com',
:timeout => 100
action 'list'
'list' do
reply[:output] = `lpstat -a | cut -d ' ' -f 1
lpstat 1`.split("n")
end
end
end
end](https://image.slidesharecdn.com/mcollective-puppetslidesafe-111103124847-phpapp02/75/Introduction-to-Marionette-Collective-26-2048.jpg)
![Simple Agent
module MCollective
module Agent
Agent Name
class Printer<RPC::Agent
Printer
metadata :name => 'printer',
:description => 'Printers and printing',
:author => 'Gary Larizza',
:license => 'BSD',
Action Name
:version => '0.1',
:url =>'http://puppetlabs.com',
:timeout => 100
action 'list'
'list' do
reply[:output] = `lpstat -a | cut -d ' ' -f 1
lpstat 1`.split("n")
end
end
end
end](https://image.slidesharecdn.com/mcollective-puppetslidesafe-111103124847-phpapp02/75/Introduction-to-Marionette-Collective-27-2048.jpg)
![Simple Agent
module MCollective
module Agent
Agent Name
class Printer<RPC::Agent
Printer
metadata :name => 'printer',
:description => 'Printers and printing',
:author => 'Gary Larizza',
:license => 'BSD',
Action Name
Command to be Run
:version => '0.1',
:url =>'http://puppetlabs.com',
:timeout => 100
action 'list'
'list' do
reply[:output] = `lpstat -a | cut -d ' ' -f 1
lpstat 1`.split("n")
end
end
end
end](https://image.slidesharecdn.com/mcollective-puppetslidesafe-111103124847-phpapp02/75/Introduction-to-Marionette-Collective-28-2048.jpg)
![Simple Agent
module MCollective
module Agent
class Printer<RPC::Agent
Printer
metadata :name => 'printer',
:description => 'Printers and printing',
:author => 'Gary Larizza',
:license => 'BSD',
:version => '0.1',
:url =>'http://puppetlabs.com',
:timeout => 100
action 'list'
'list' do
reply[:output] = `lpstat -a | cut -d ' ' -f 1
lpstat 1`.split("n")
end
end
end
end](https://image.slidesharecdn.com/mcollective-puppetslidesafe-111103124847-phpapp02/75/Introduction-to-Marionette-Collective-29-2048.jpg)

![Output
Determining the amount of hosts matching filter for 2 seconds .... 89
* [ ============================================================> ] 89 / 89
lab15-hsimaclab-hhs
result: ["psm_HHS_201Lab",
"psm_HHS_Bookroom",
"psm_HHS_Media_Center",
"psm_HHS_Office_9040",
"psm_HHS_Office_9050"]
lab12-hsimaclab-hhs
result: ["psm_HHS_201Lab",
"psm_HHS_Bookroom",
"psm_HHS_Media_Center",
"psm_HHS_Office_9040",
"psm_HHS_Office_9050"]](https://image.slidesharecdn.com/mcollective-puppetslidesafe-111103124847-phpapp02/75/Introduction-to-Marionette-Collective-31-2048.jpg)




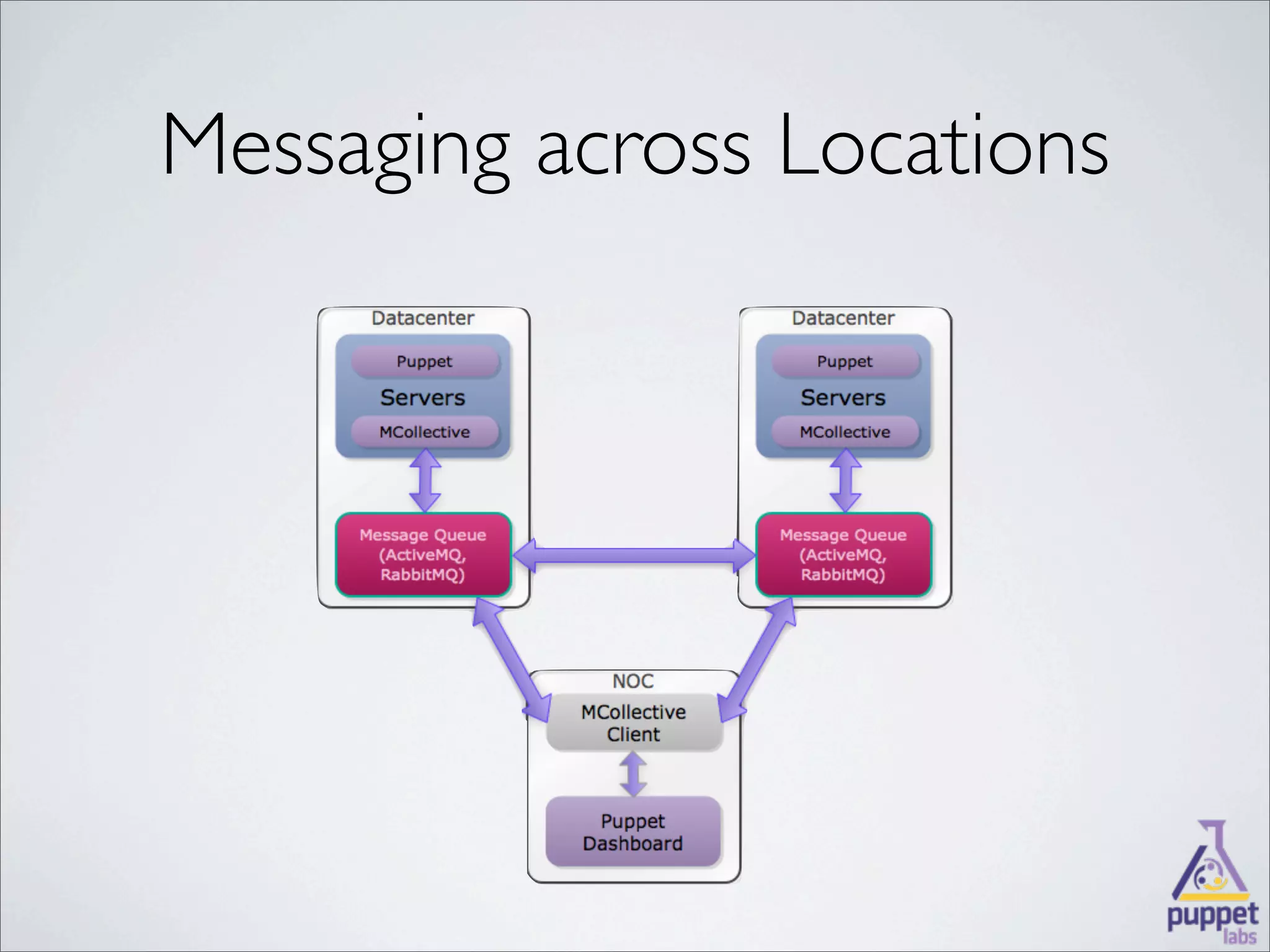




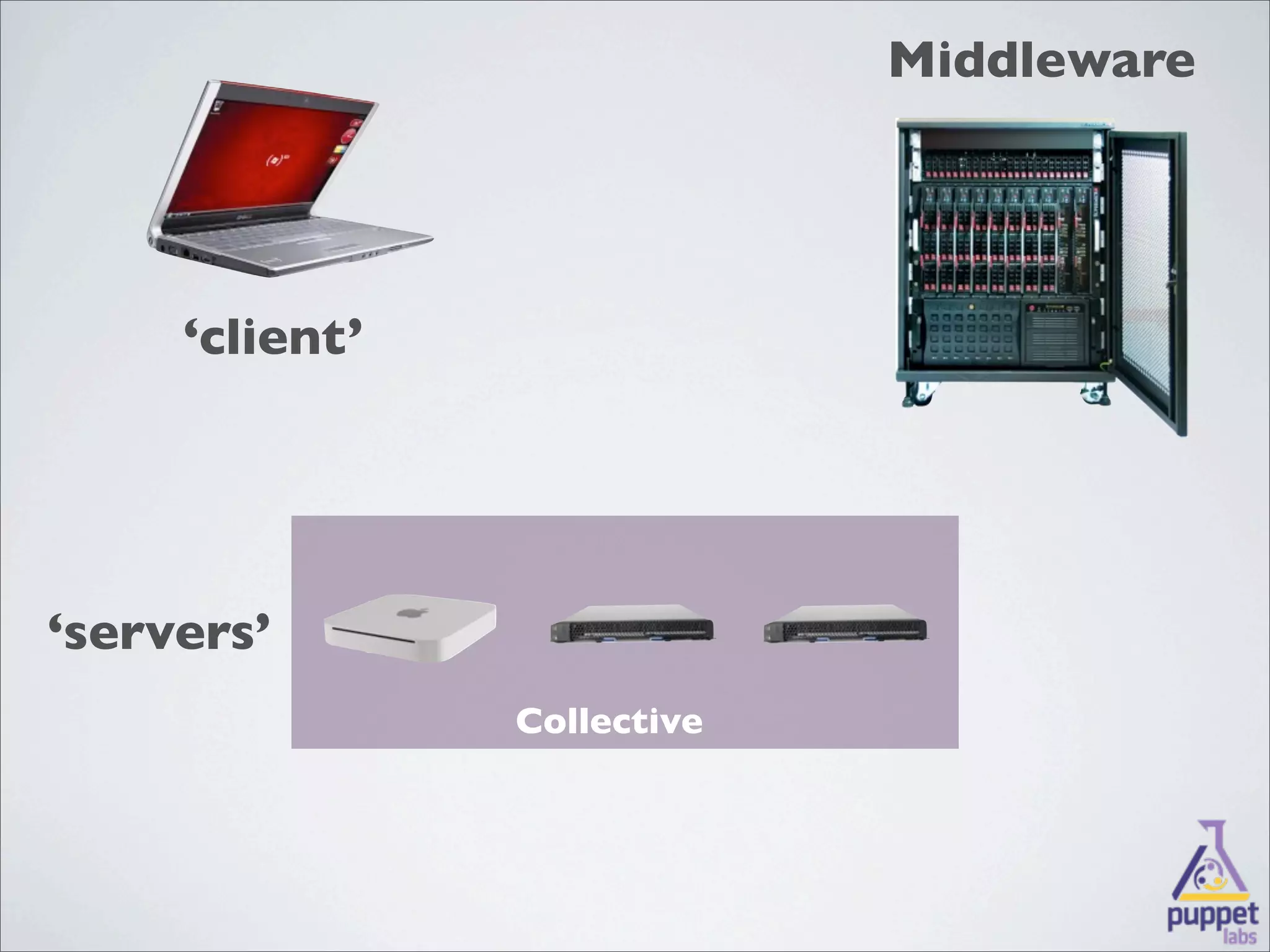
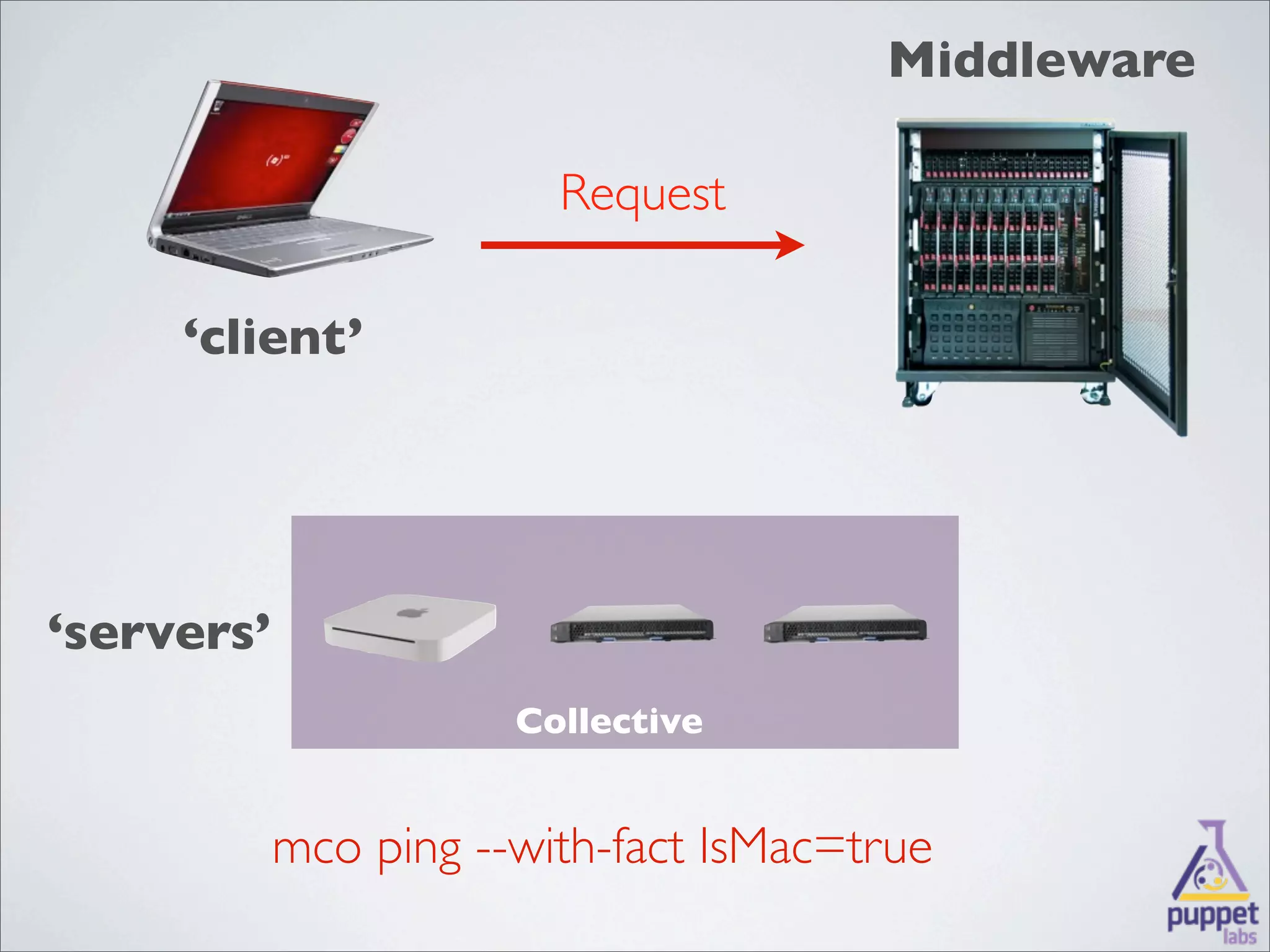
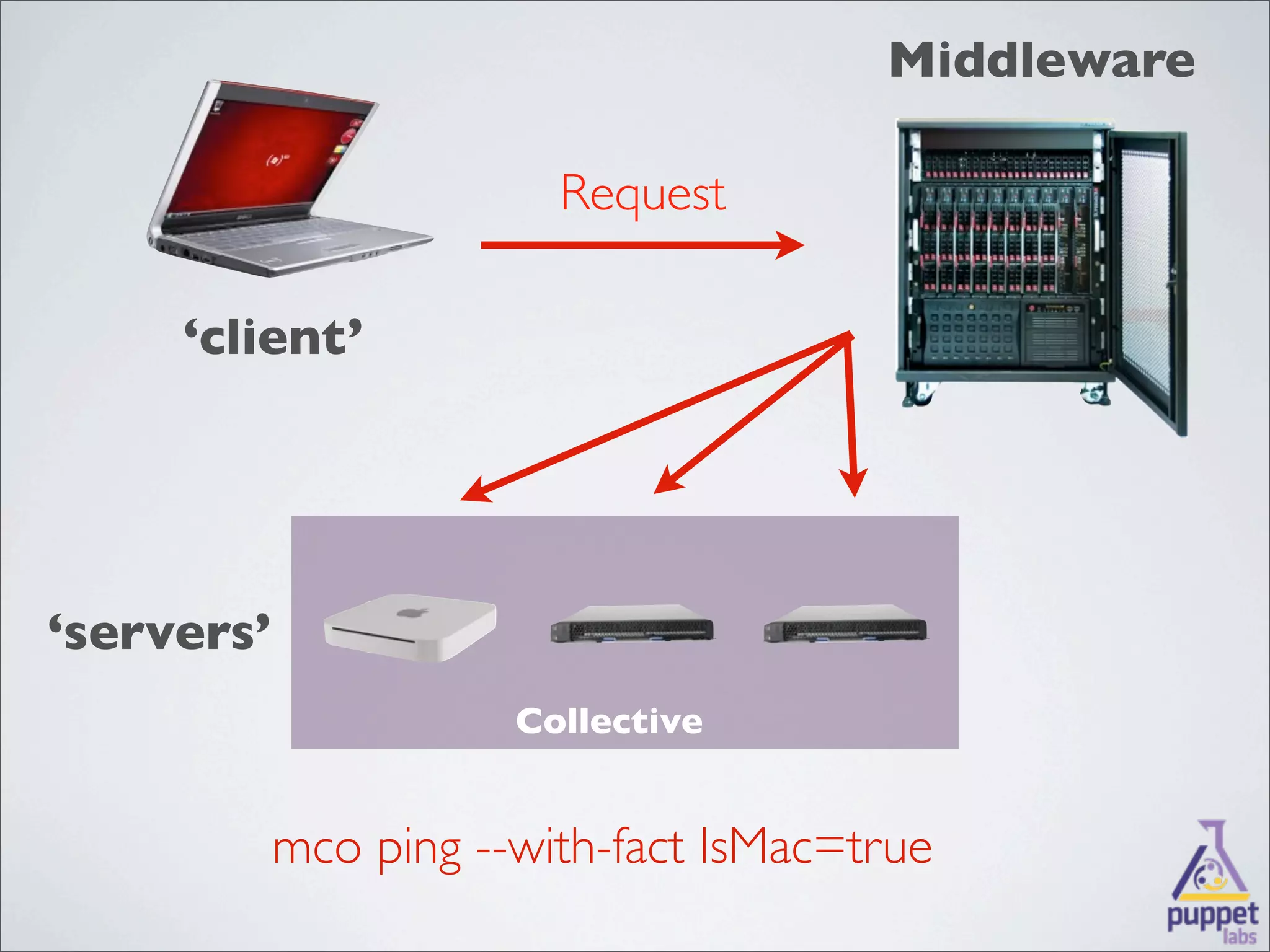
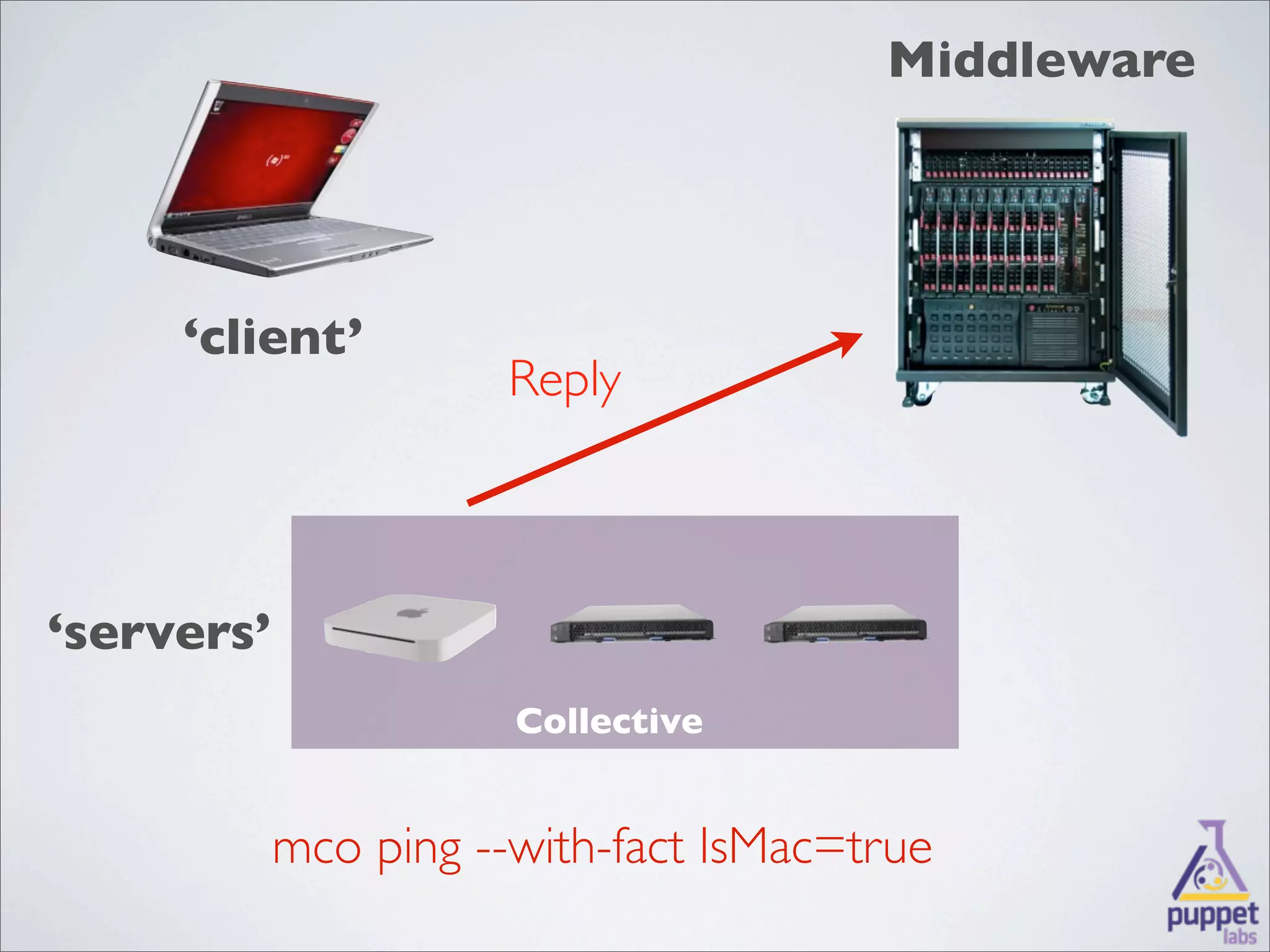
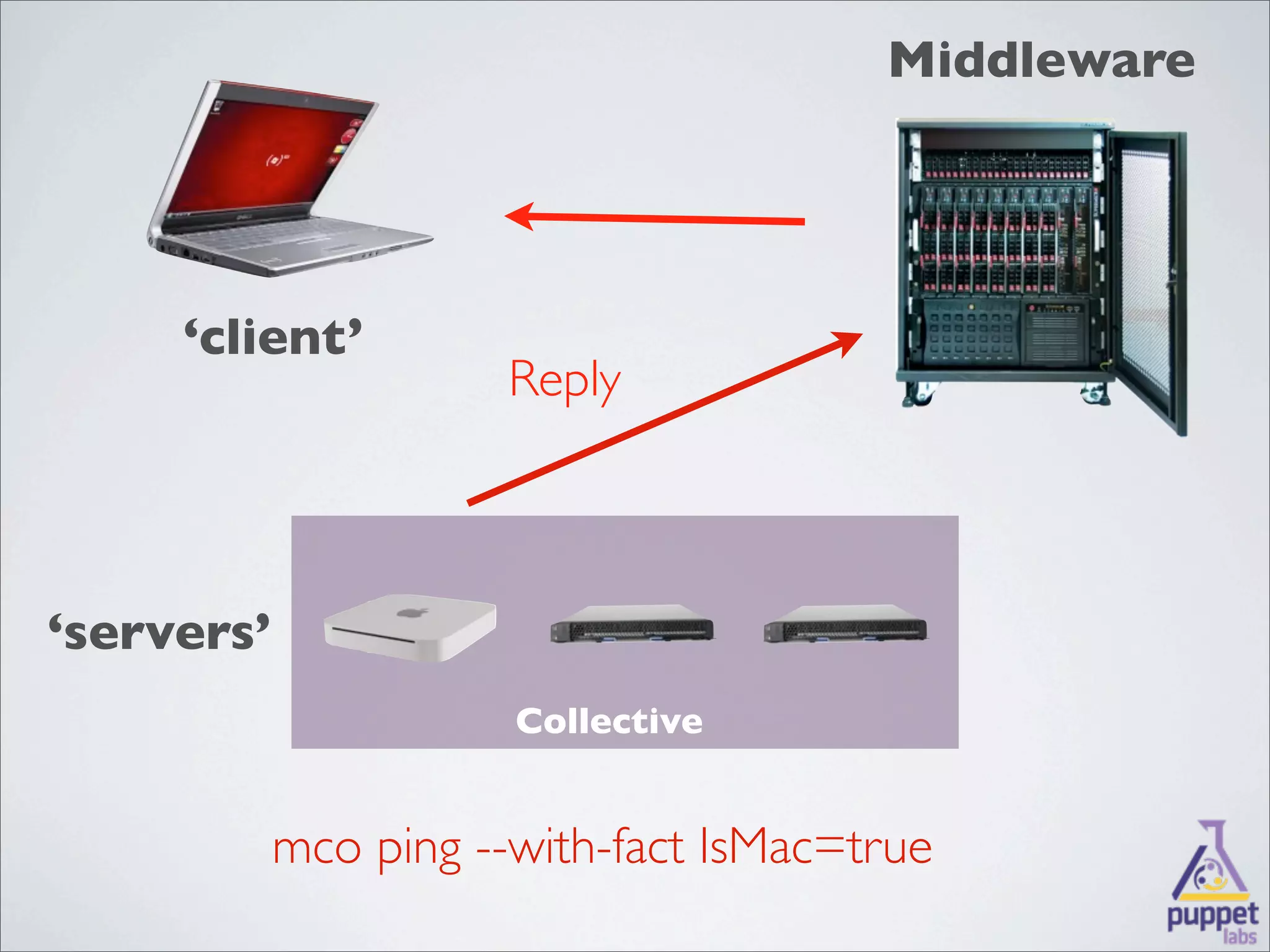
MCollective is a framework for system management and orchestration that allows users to execute tasks across many servers simultaneously. It uses message queuing as middleware to facilitate communication between a client and servers. Users can write custom agents in Ruby to perform actions on servers in response to messages. MCollective provides features for system discovery, inventory collection, task execution, and configuration management across thousands of nodes.









































![Backbone/Marionette recap [2015]](https://cdn.slidesharecdn.com/ss_thumbnails/backbonemarionette2015-150109101453-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

































































