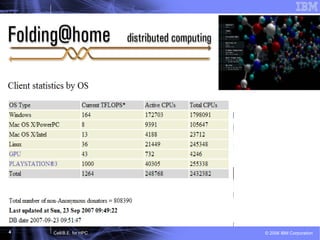
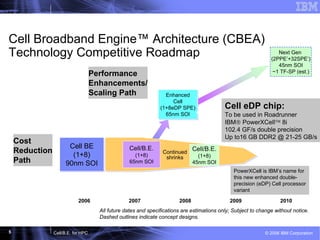
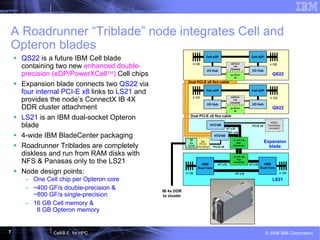
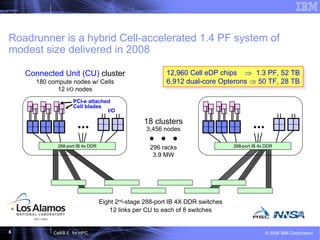
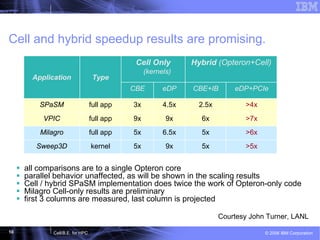
This document discusses the Cell Broadband Engine (CBE) architecture and its use for high-performance computing (HPC). It provides examples of the CBE achieving speedups of 3-9x on full applications compared to a single Opteron core through the use of the Synergistic Processing Elements. It also outlines future directions for the CBE, including making it easier to program, enhancing the processing elements, and integrating a complete Roadrunner node onto a single chip.