Download as PDF, PPTX











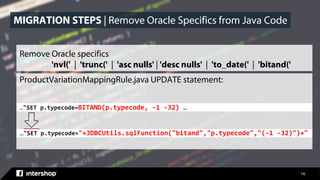

![18
Iterator<ProductPO> pIterator = pH.getObjectsBySQLWhere("sku=? and domainID=?
and rownum=1", new String[] { sku, aDomain.getUUID() }).iterator();
Iterator<ProductPO> pIterator = null;
try
{
Map<String, Object> params = new HashMap<>();
params.put("SKU", sku);
params.put("DomainUUID", aDomain.getUUID());
productsIterator =
appProvider.get().getQueryExecutor().executePageableQuery("product/GetProductBySKUSimple"
, params);
if (productsIterator.hasNext())
{
ProductPO p = productsIterator.next();
aProduct = productViewProvider.create(p.getUUID(), aDomain.getUUID());
}
} …
MIGRATION STEPS | Extract Queries into Query Files](https://image.slidesharecdn.com/2018-09-20productjenskleinschmidtmssqlserver-180927120254/85/Intershop-Commerce-Management-with-Microsoft-SQL-Server-18-320.jpg)






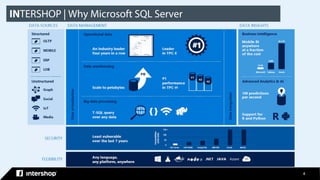
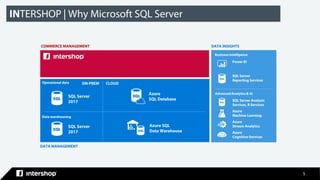
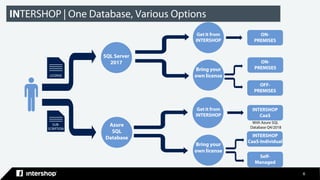
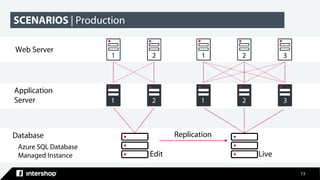
This document discusses Intershop Commerce Management's support for Microsoft SQL Server and Azure SQL Database as operational databases. Key points include: - Intershop Commerce Management version 7.10 now supports Microsoft SQL Server and Azure SQL Database in addition to Oracle Database. - Microsoft SQL Server and Azure SQL Database provide features for business intelligence, advanced analytics, data management, and machine learning. - Organizations have options to use SQL Server on-premises, Azure SQL Database on Azure, or let Intershop manage the database through their commerce-as-a-service offering. - The document outlines the steps taken to migrate an existing Intershop implementation from Oracle to Microsoft SQL Server, including



































































