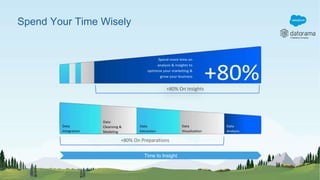
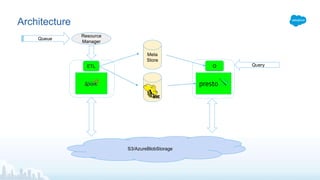
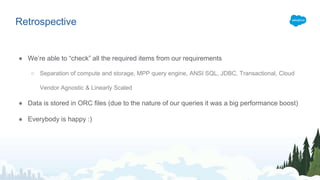
Datorama, acquired by Salesforce in 2018, is a rapidly growing company specializing in integrating and unifying marketing data from various sources to provide actionable insights and optimize campaign performance. The document outlines Datorama's architecture, including features such as data lakes and ETL processes, designed to handle mutable data with high performance and reliability. It highlights key metrics showcasing Datorama's scale and operational capabilities, emphasizing their commitment to meeting evolving data management needs.