




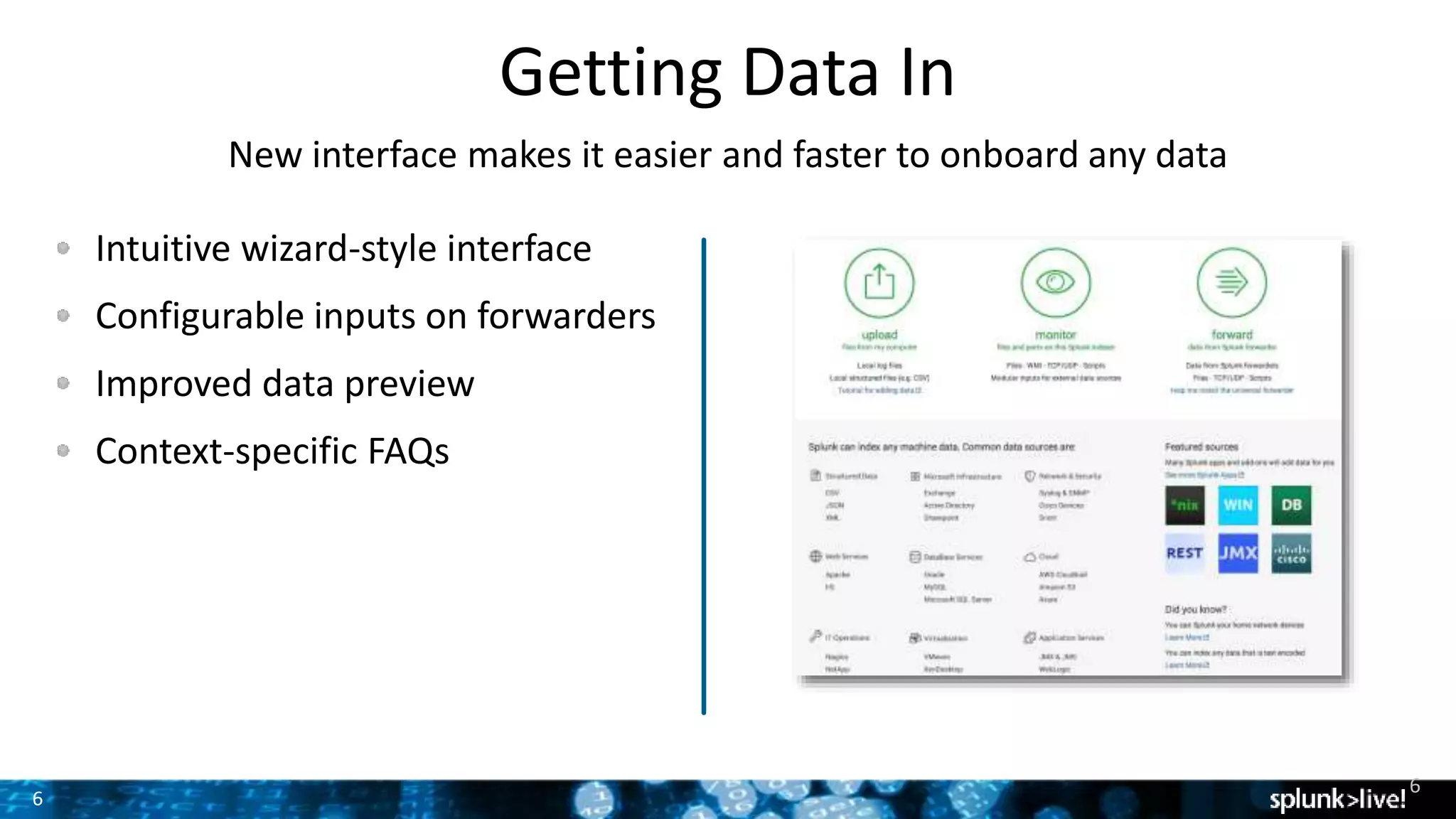



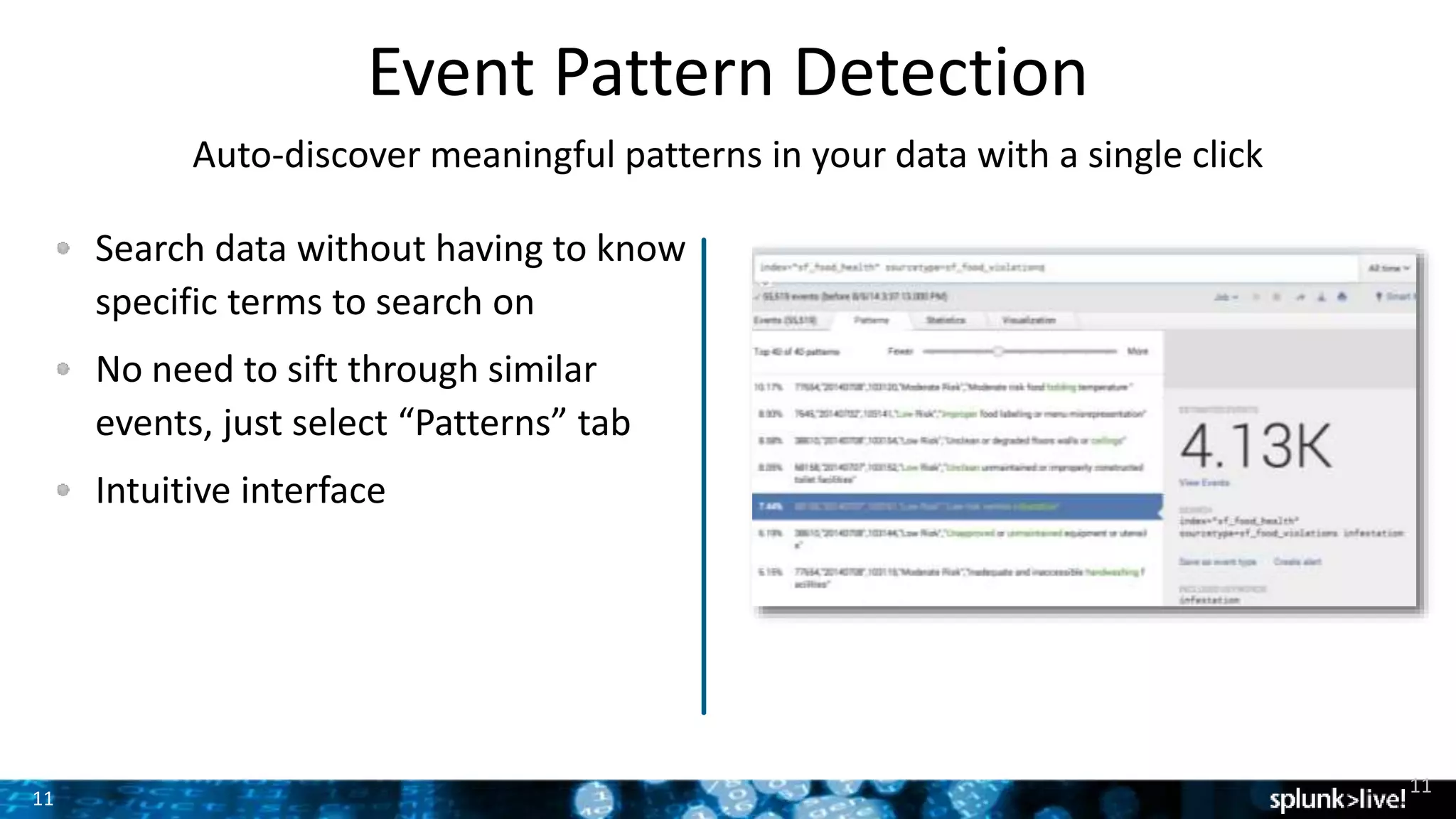


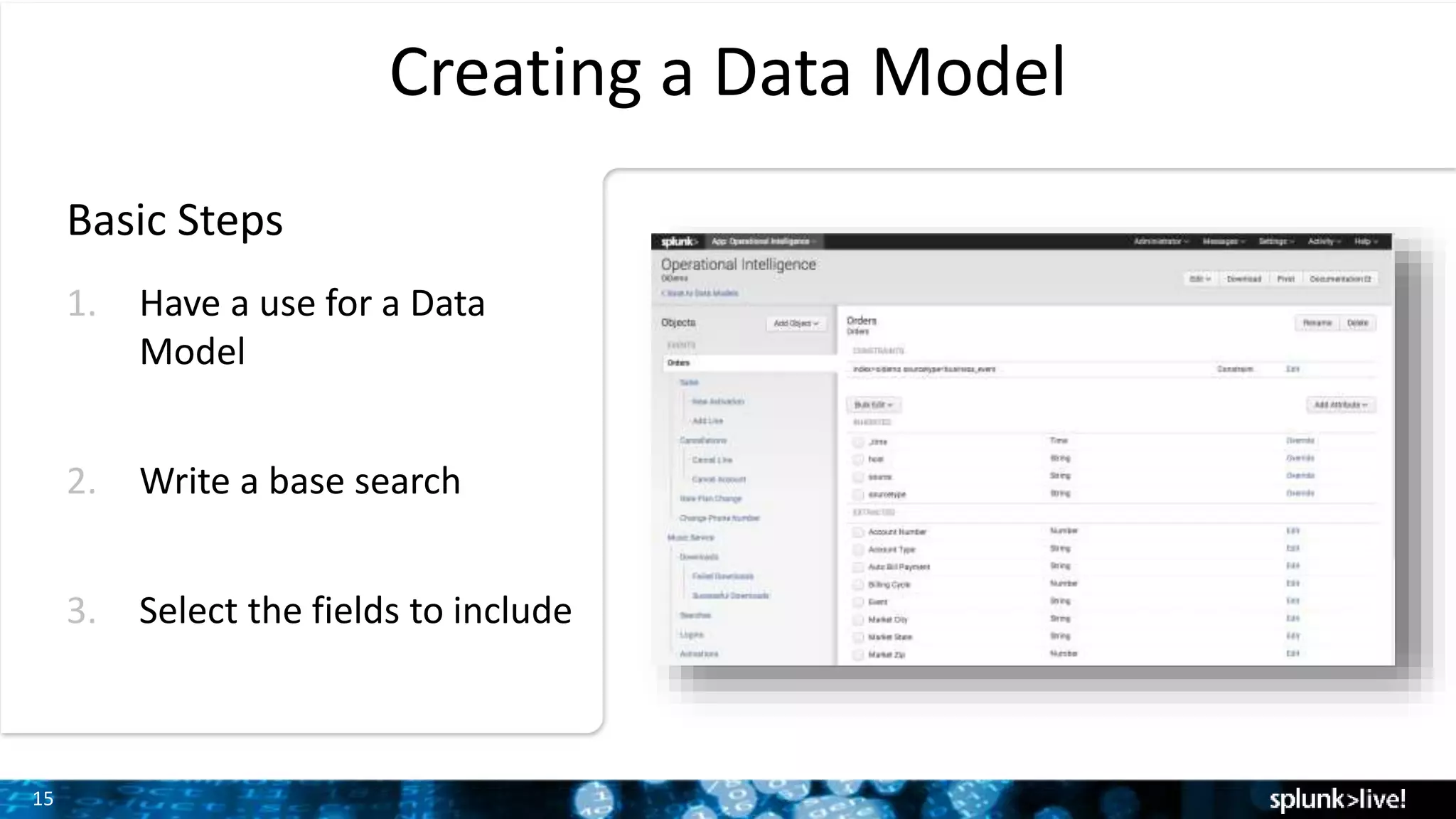
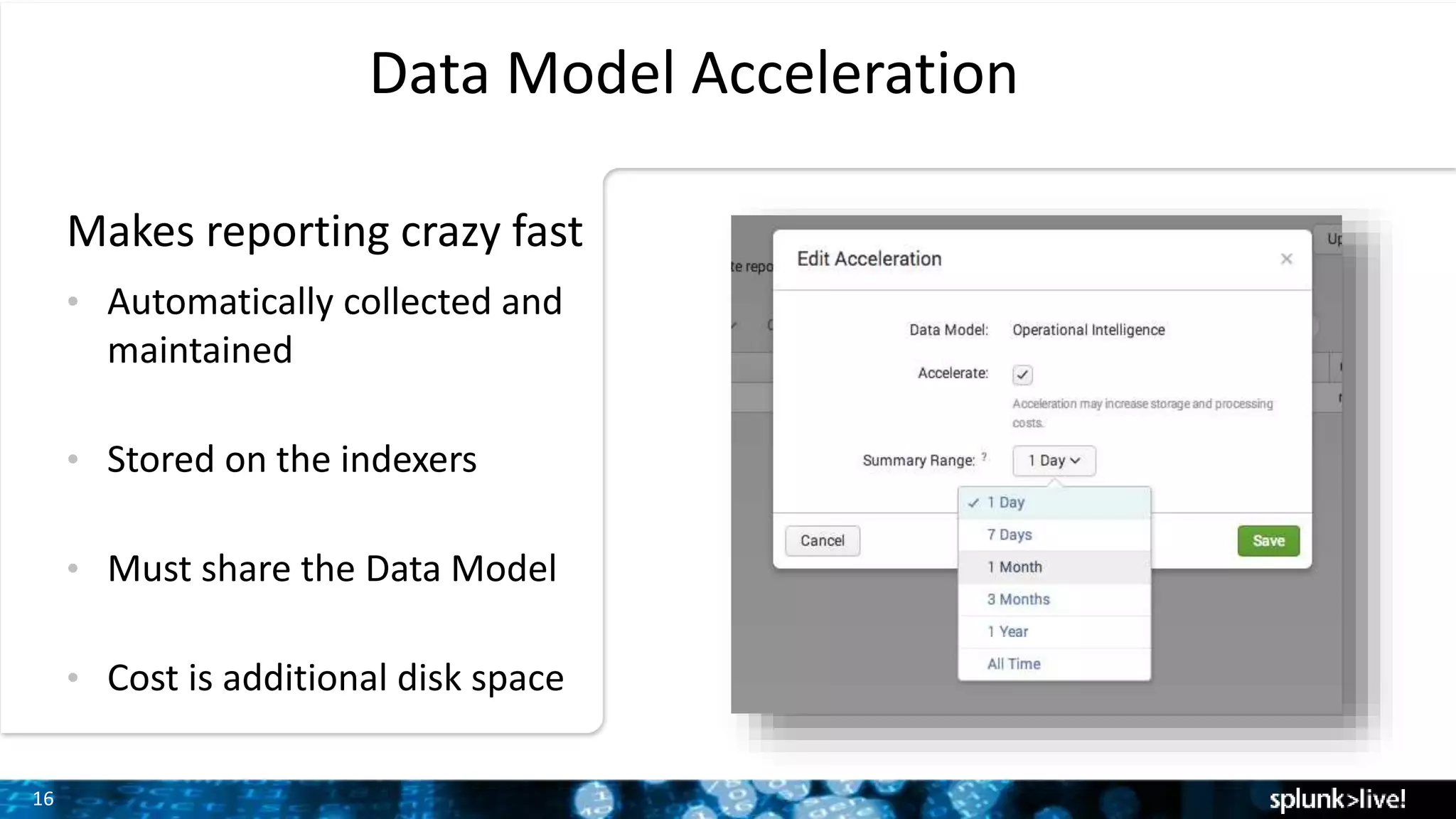


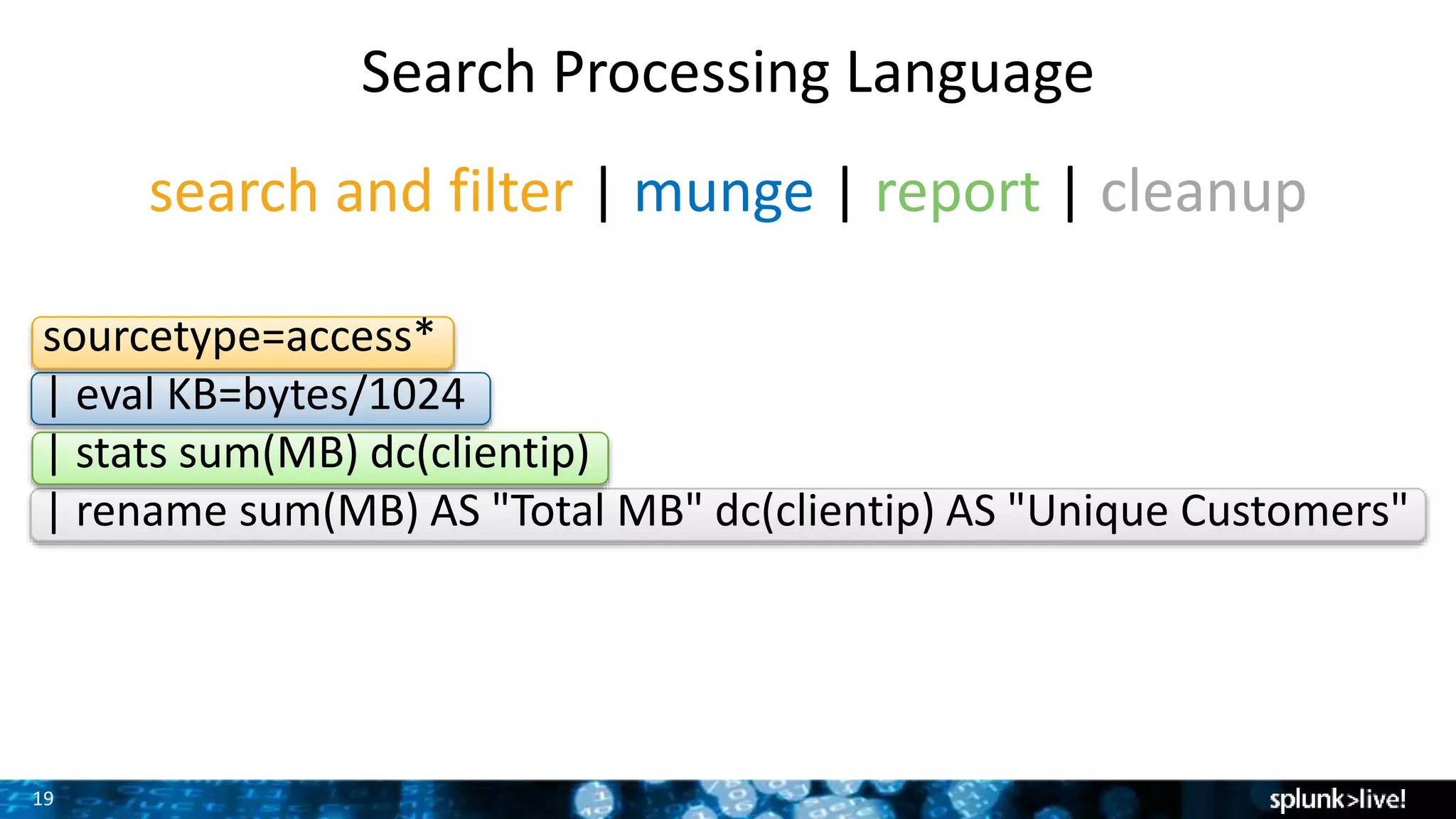

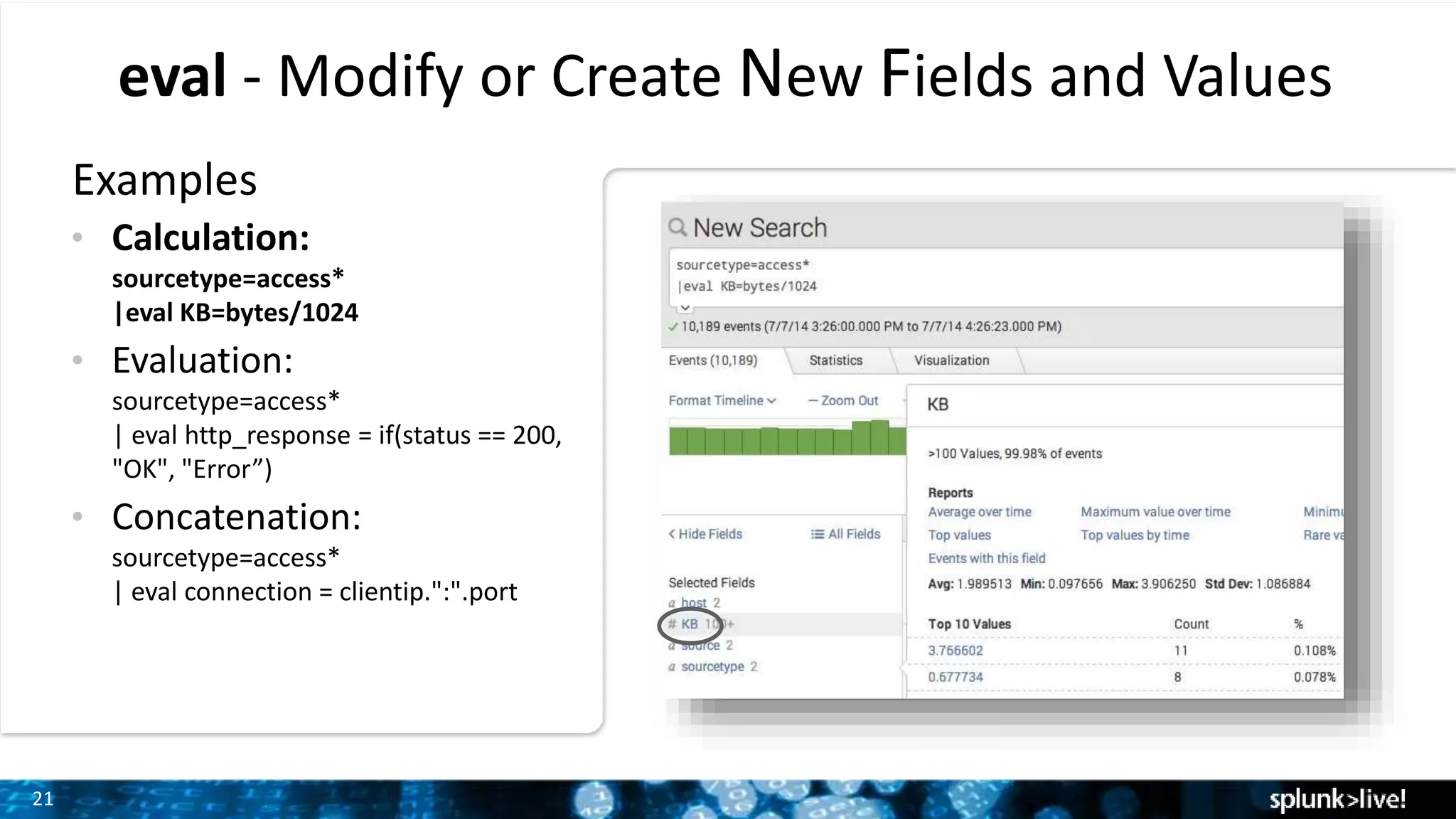
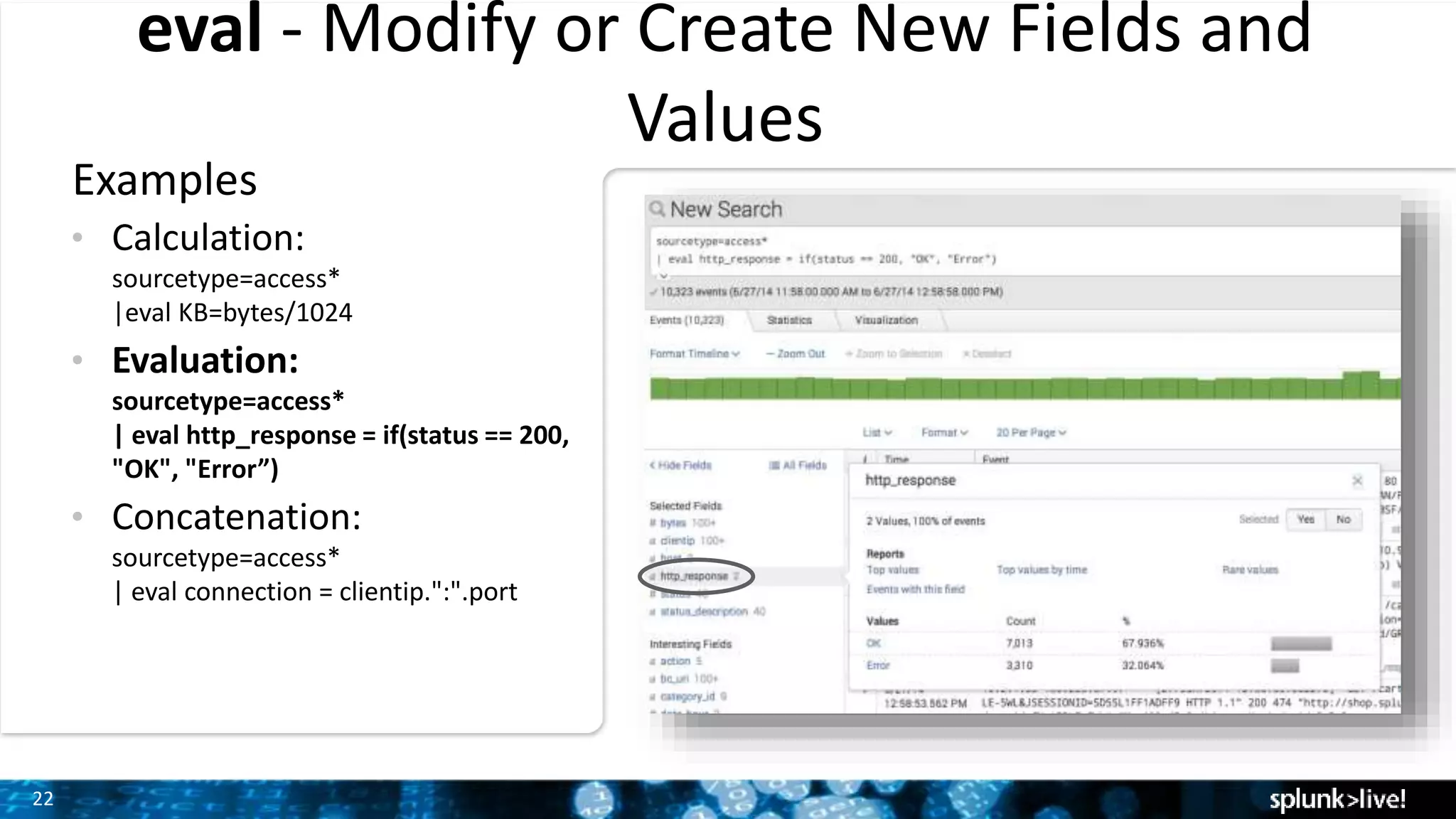
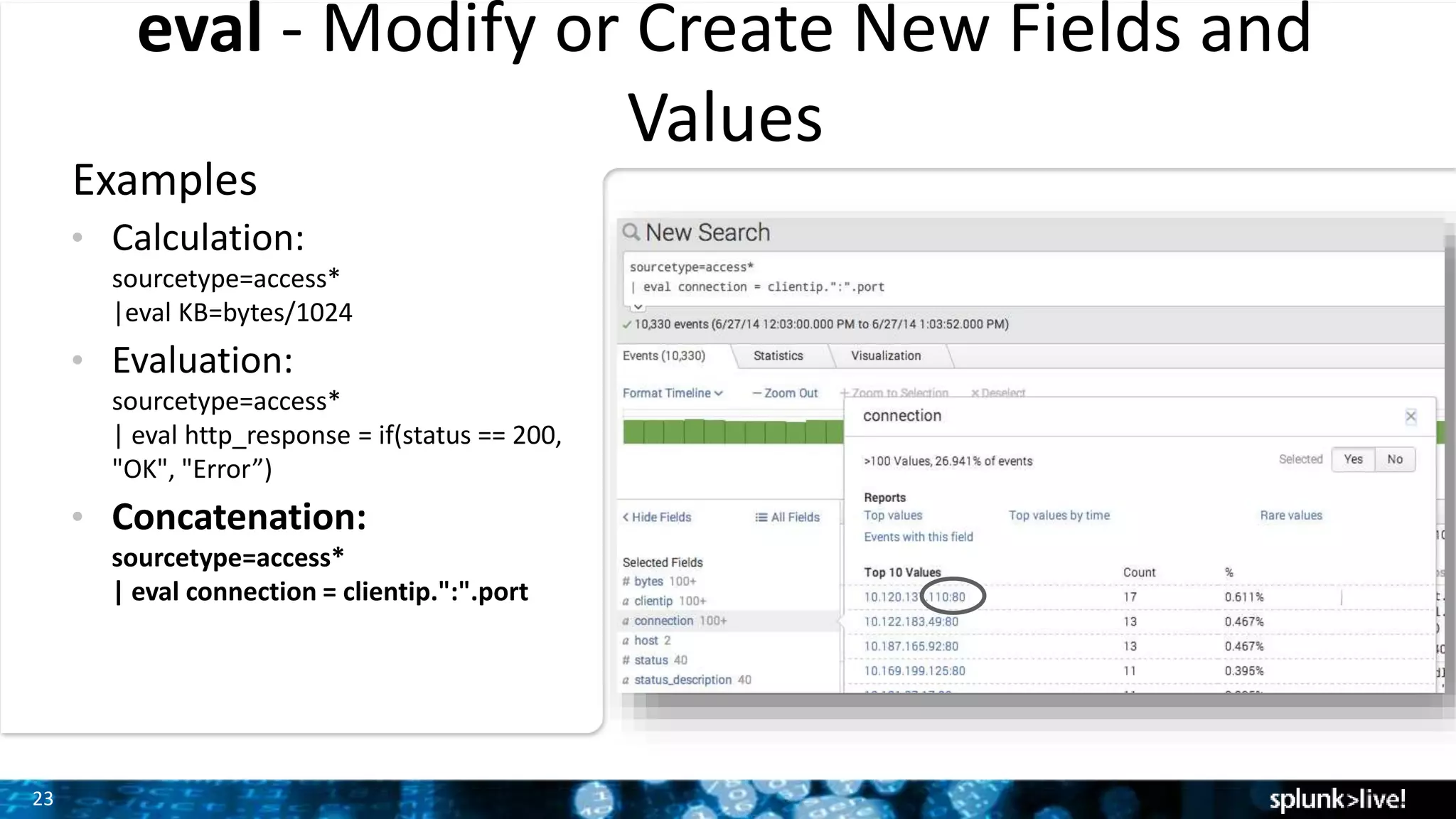
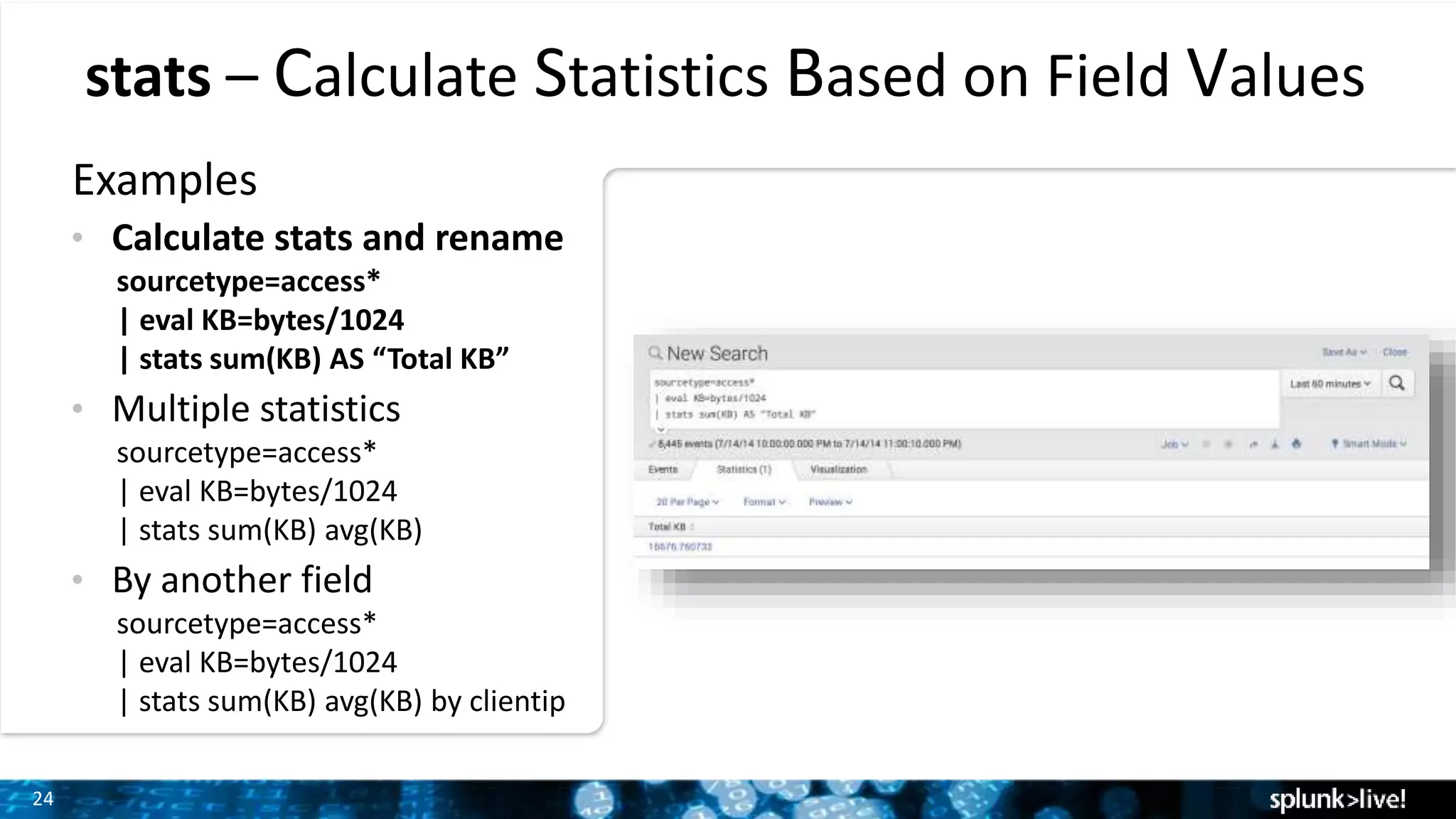
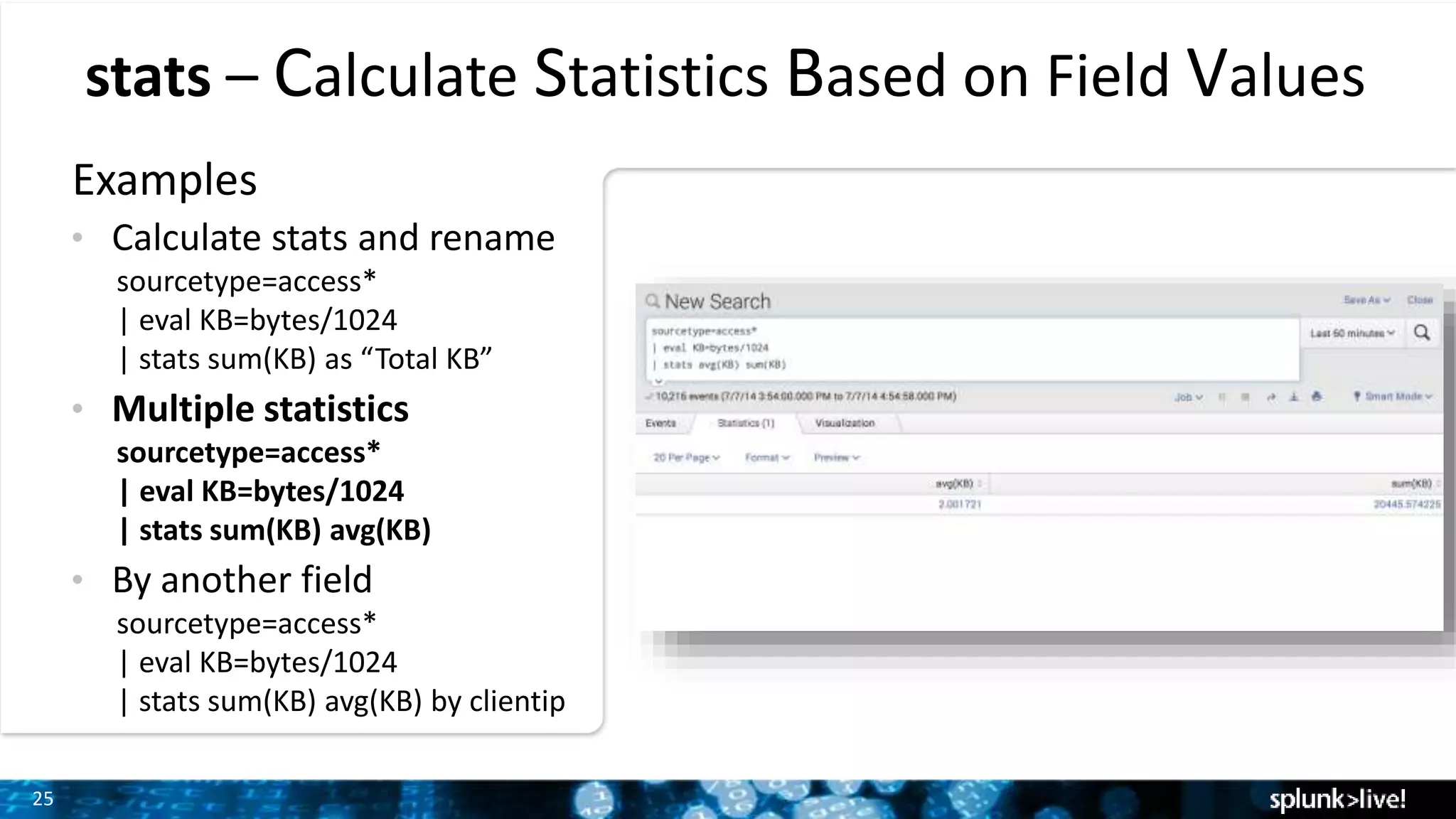
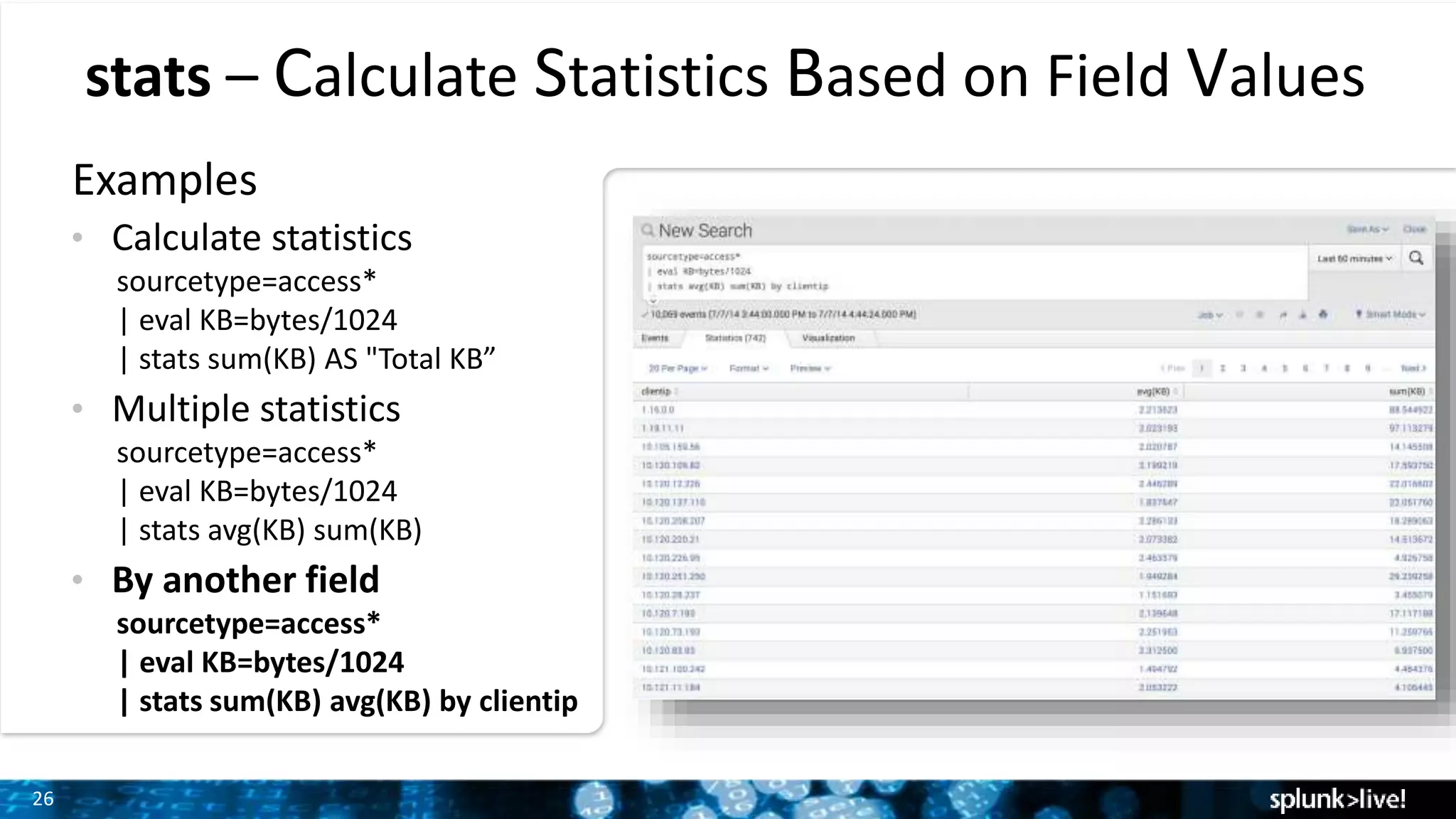

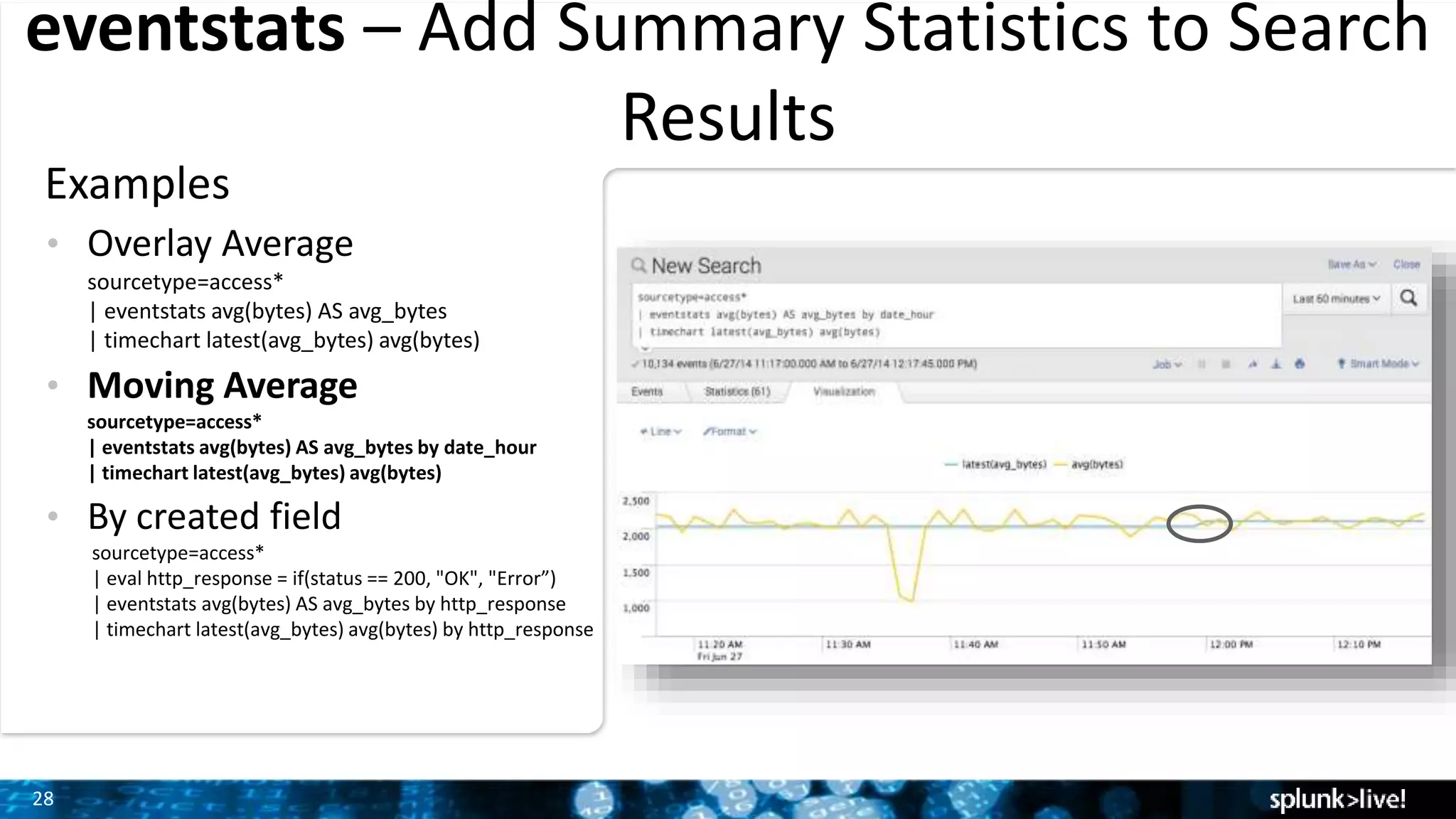

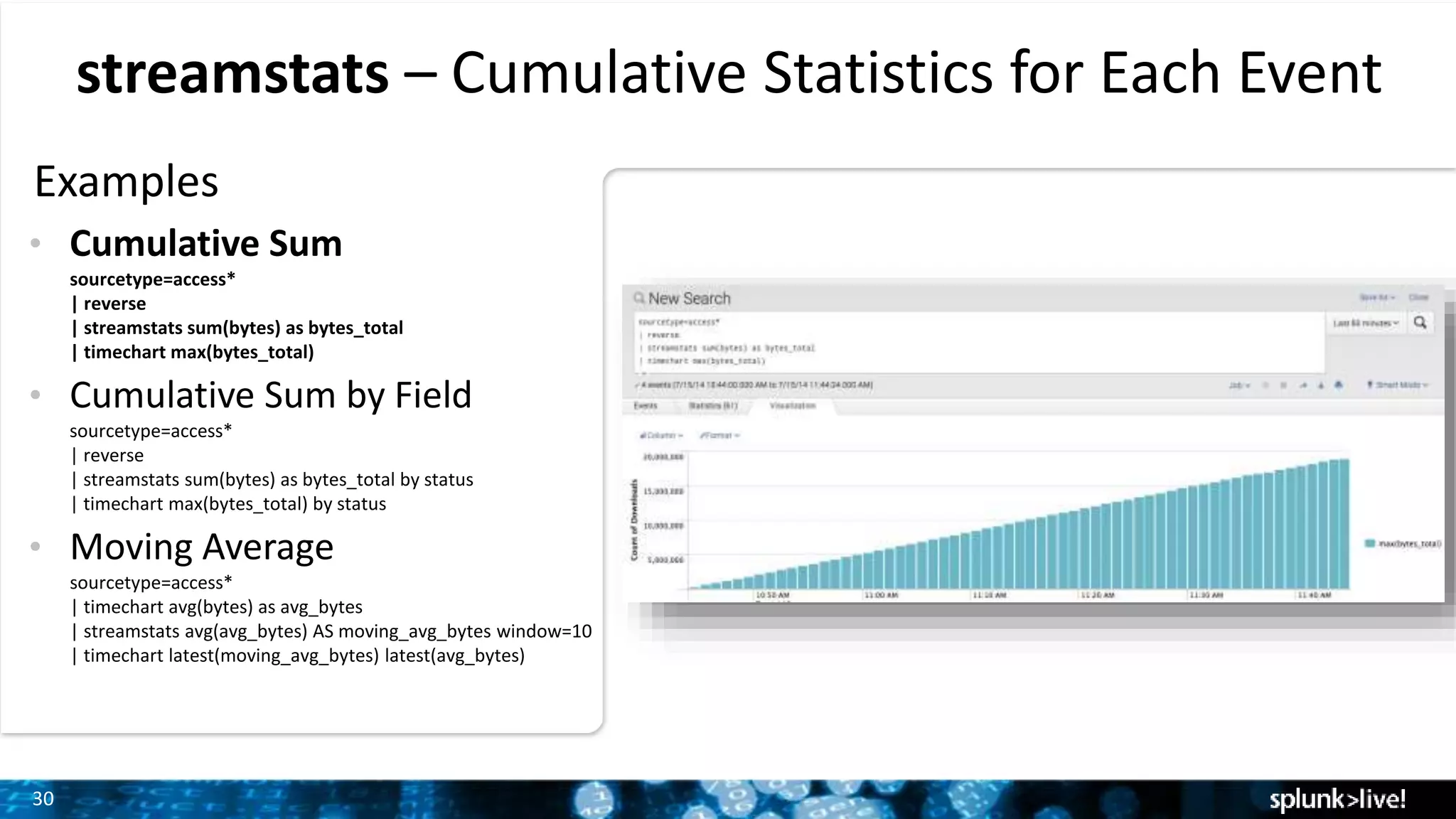
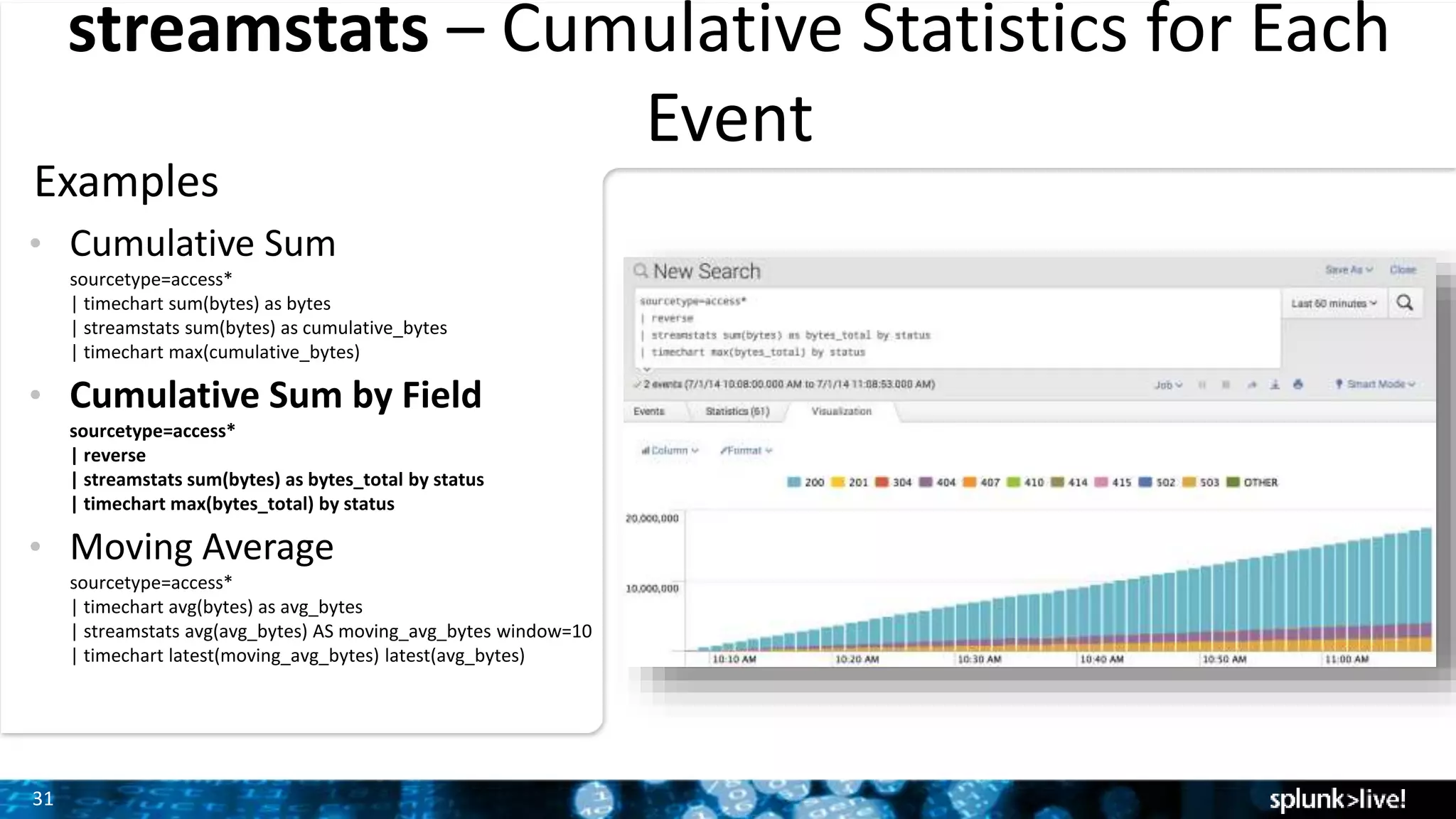
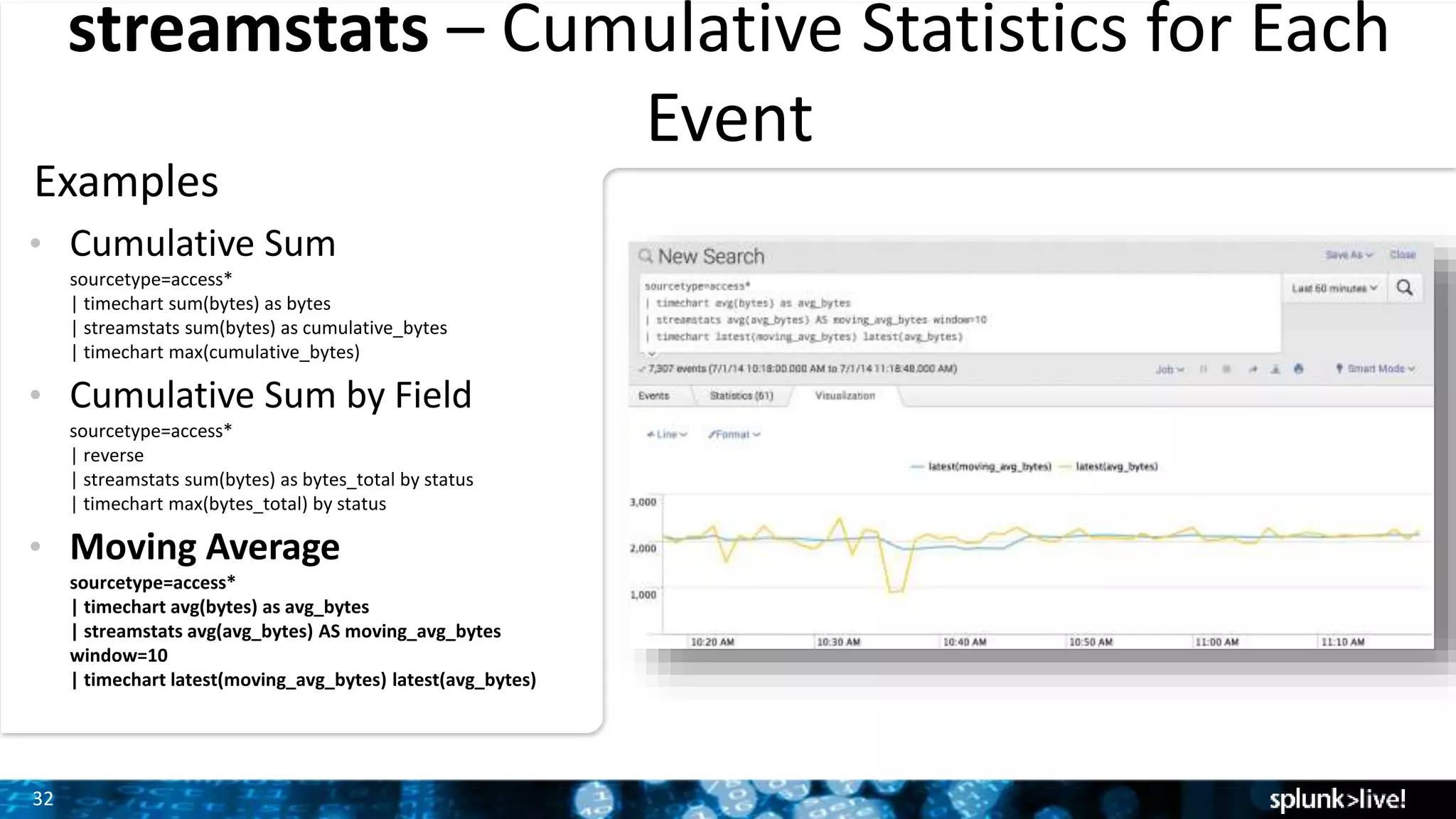
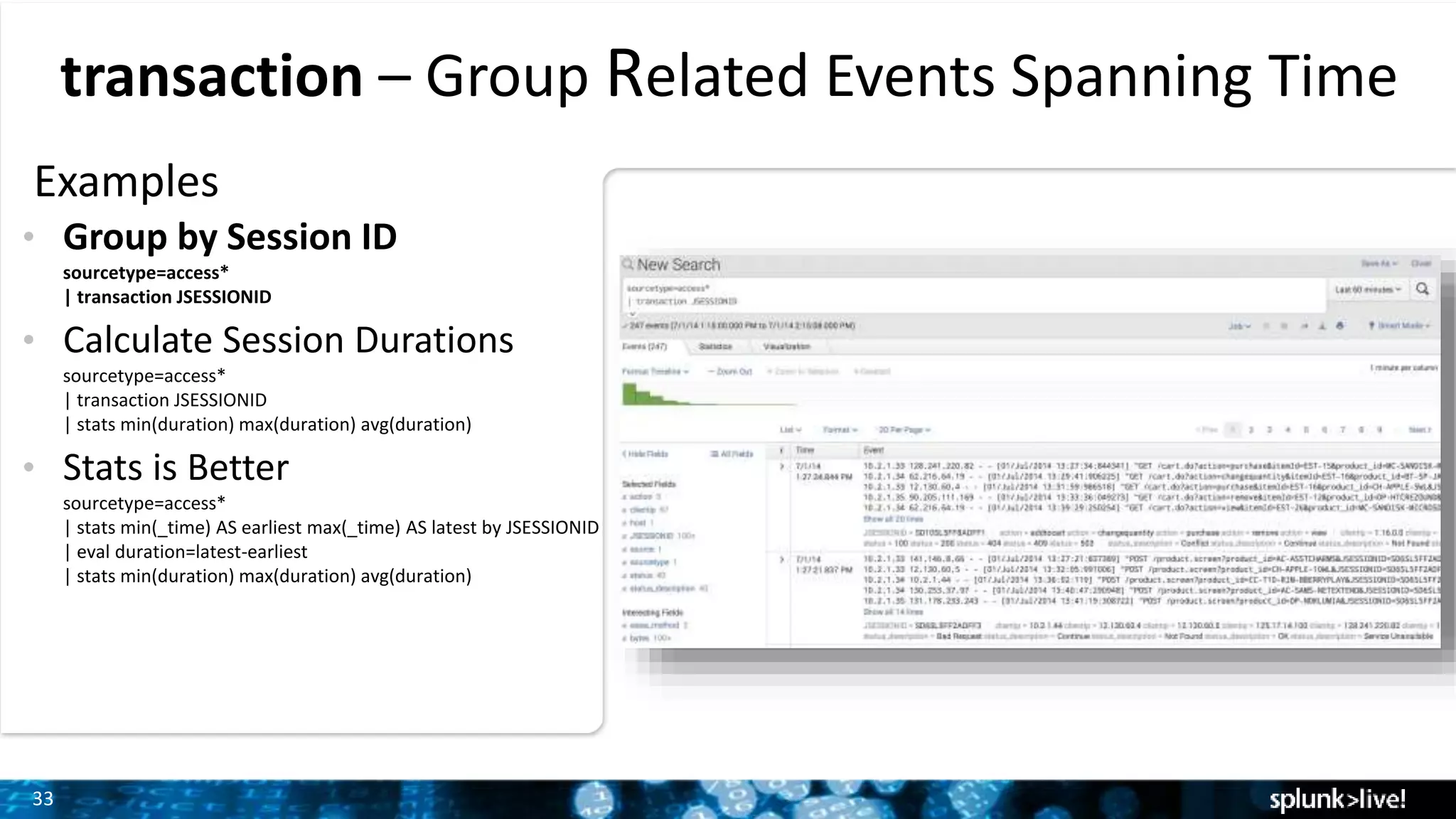
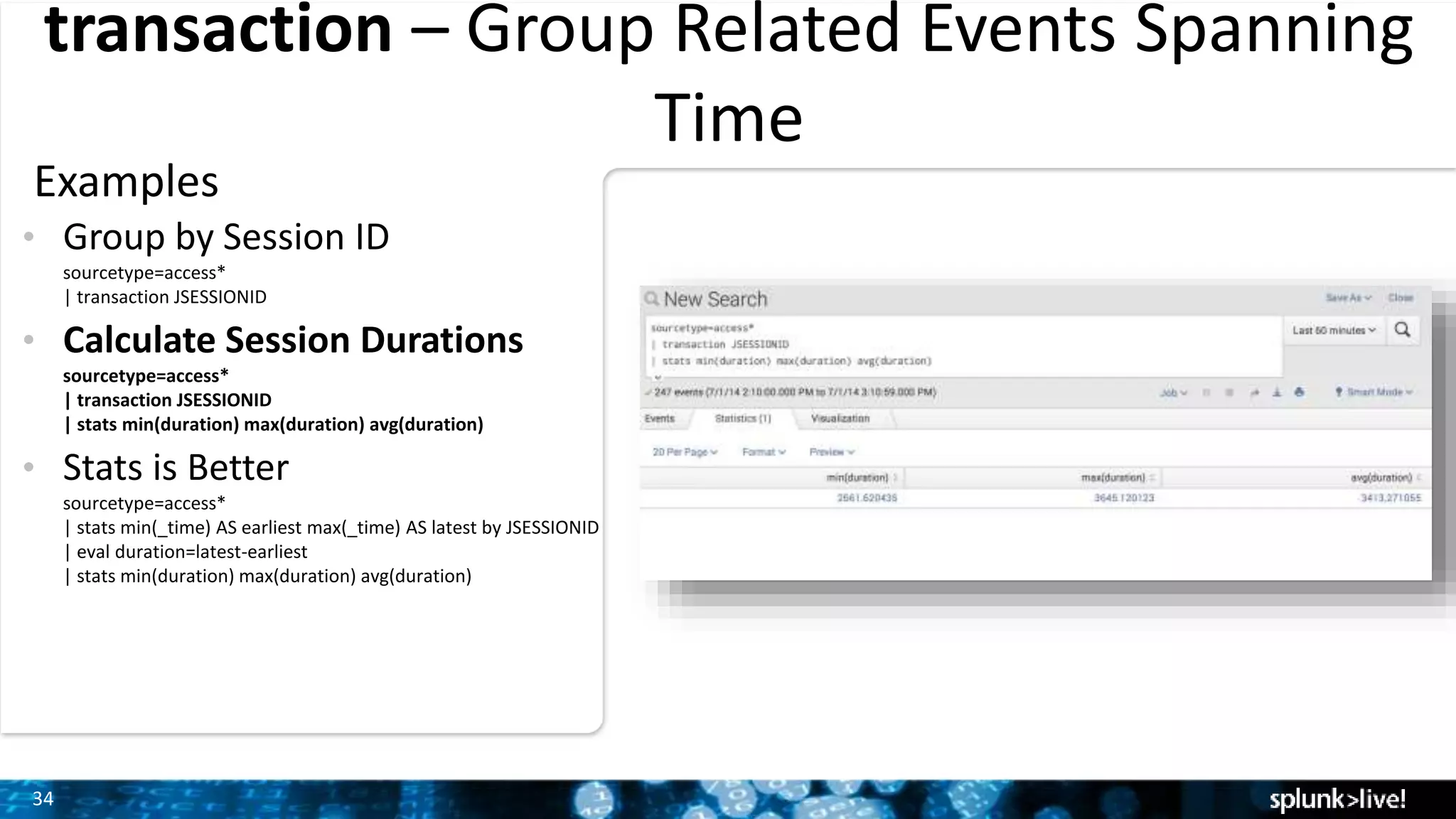
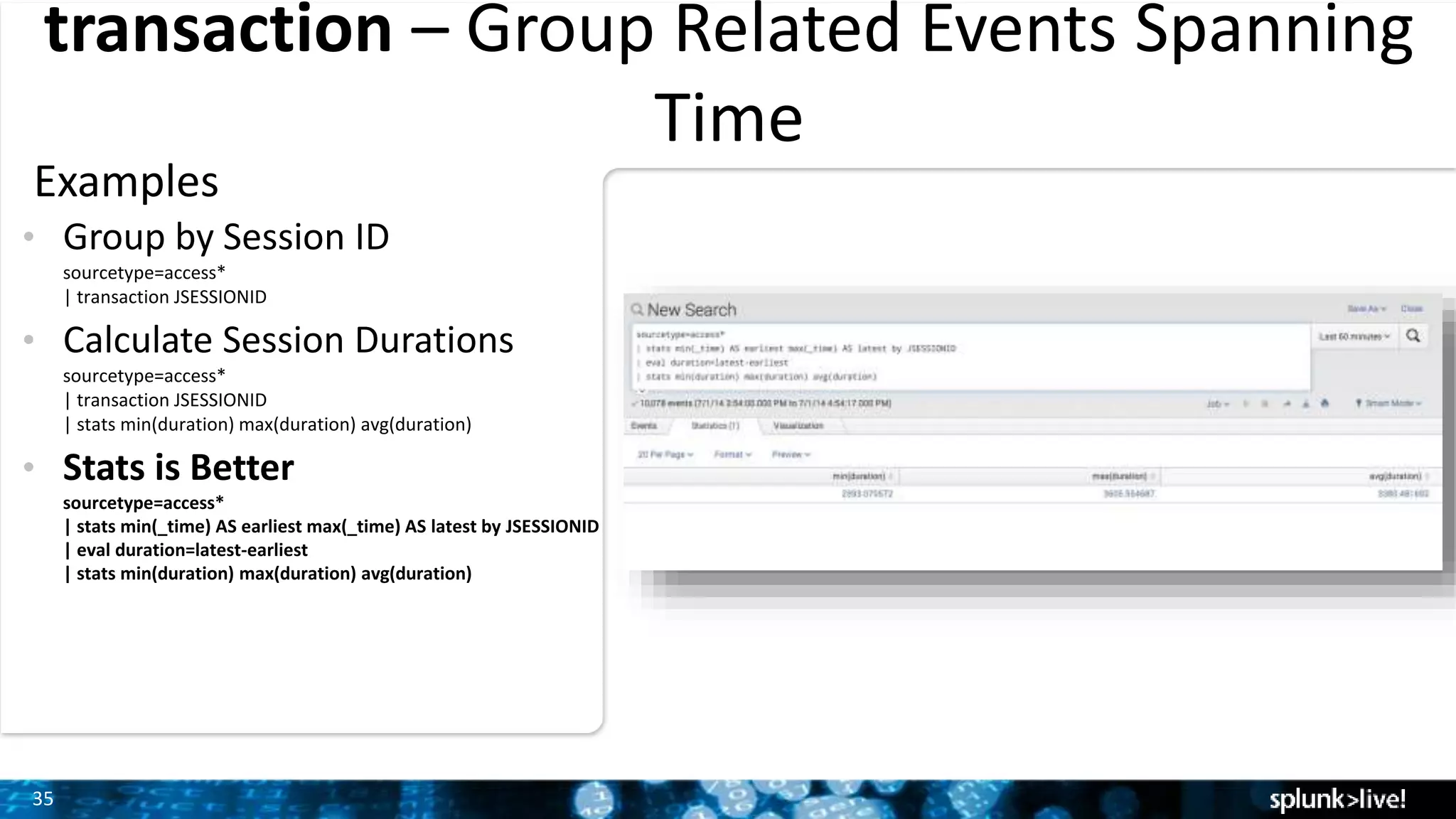




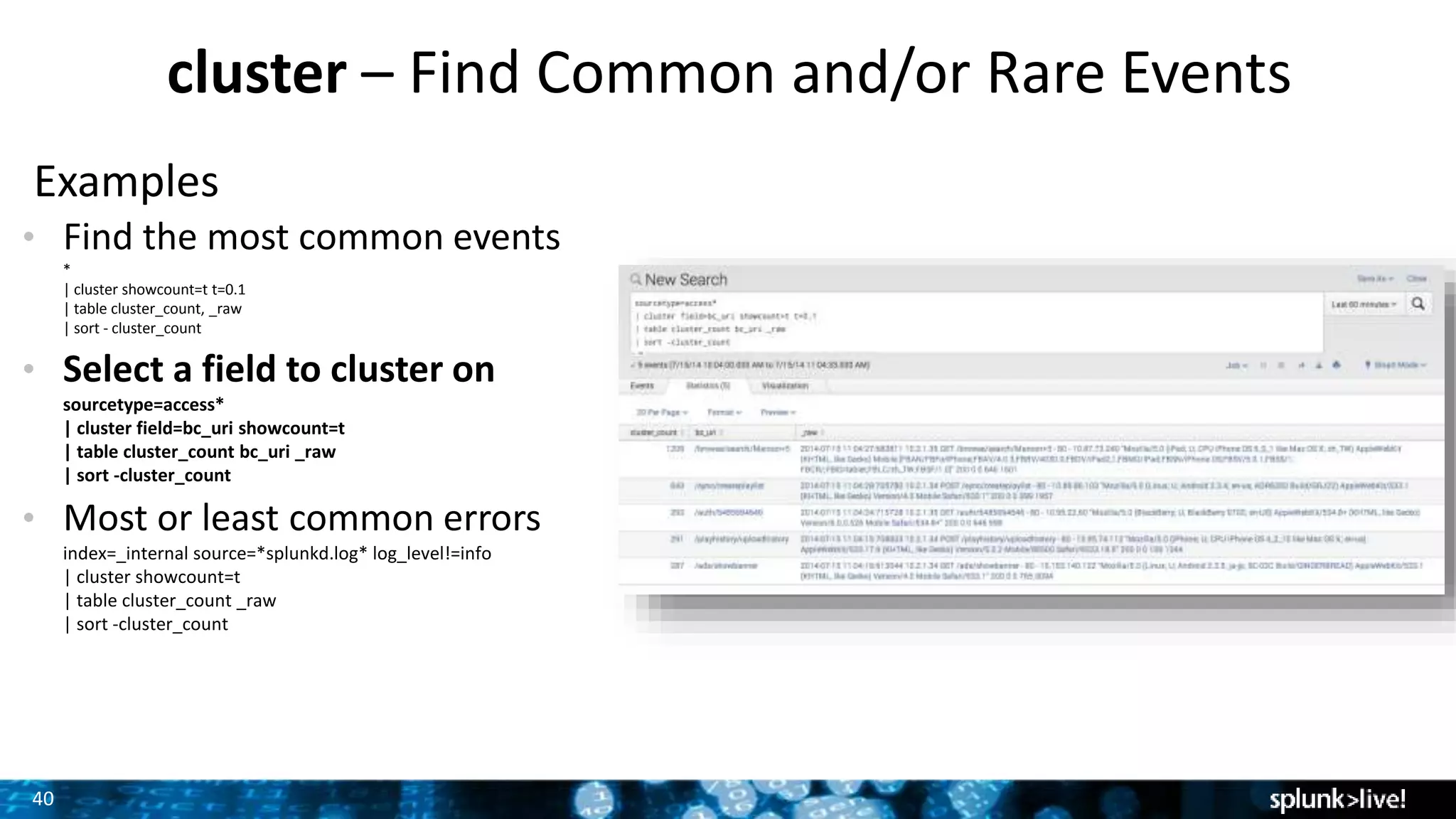
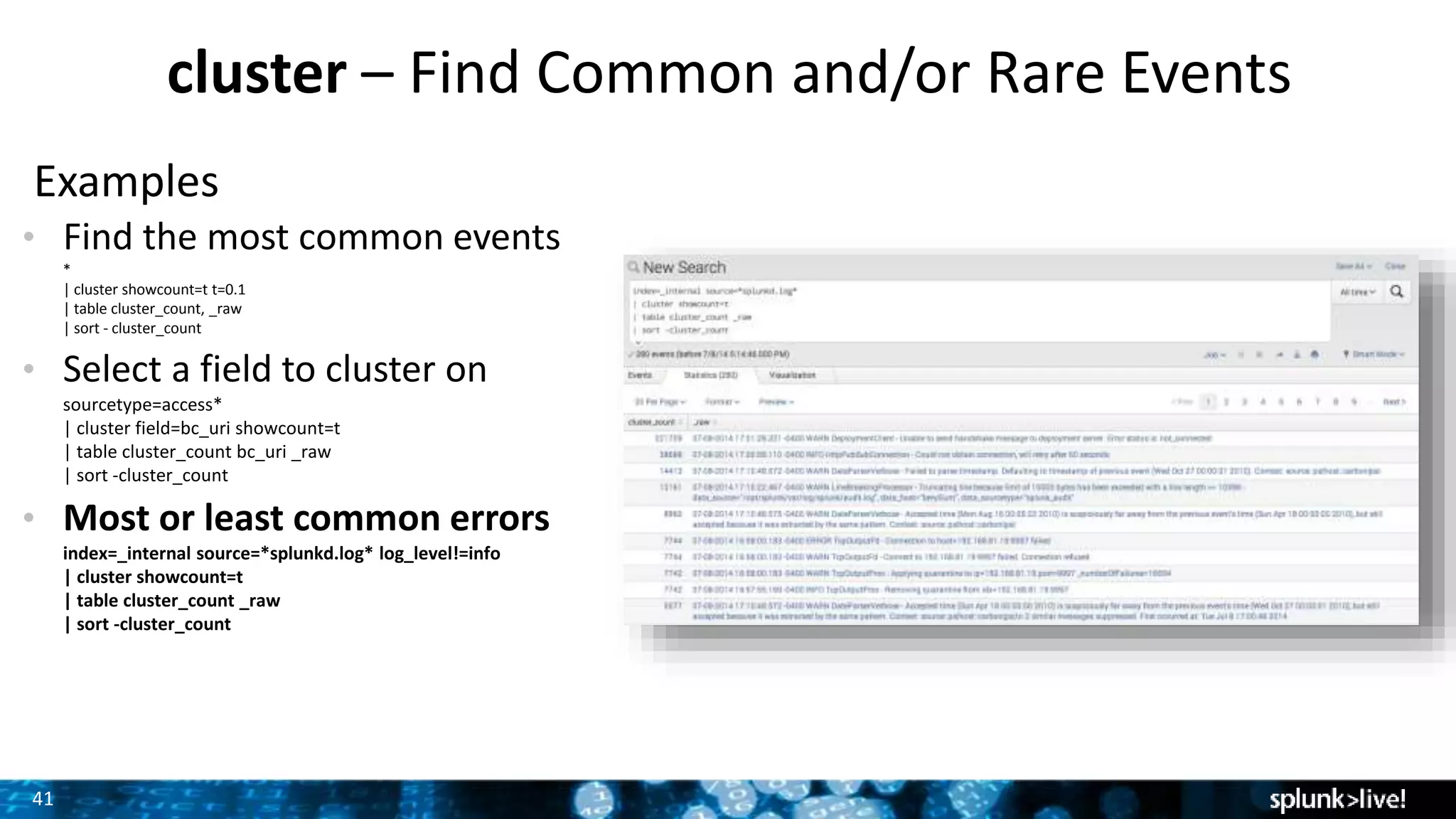


The document outlines the new features introduced in Splunk Enterprise 6.2, highlighting advancements in data management, analytics, and user interface enhancements. Key functionalities include an advanced field extractor, instant pivot capabilities, and the introduction of data models for streamlined reporting. The presentation also emphasizes the use of essential search commands and tools to enhance data analysis and operational intelligence.































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











