Download to read offline


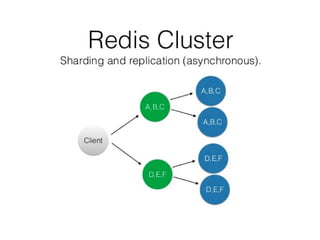




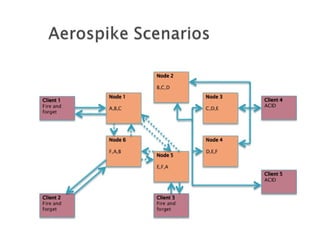
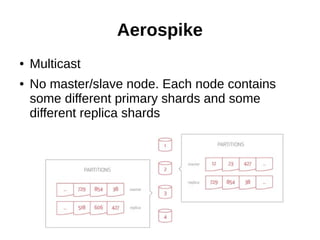


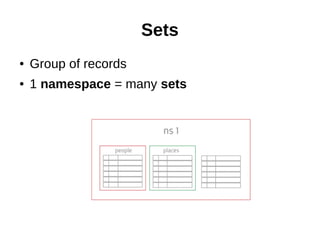








The document discusses problems with the existing Redis implementation and requirements for a new solution. It evaluates Aerospike and Apache Ignite as potential replacements. Aerospike is highlighted as a good fit due to its support for sharding, ACID compliance, and ability to store data on disk or RAM for high availability and reduced costs compared to RAM-only solutions.