Downloaded 43 times





![Agenda
• [Brief] MongoDB overview
• What is TokuMX?
• Getting started with TokuMX
• Maximizing performance
• Configuring compression
• Transactions
• Support
• Q+A](https://image.slidesharecdn.com/20140114-webinar-get-more-out-of-mongodb-with-tokumx-140319063324-phpapp02/85/Get-More-Out-of-MongoDB-with-TokuMX-5-320.jpg)


![installation
MongoDB
$ tar xzvf mongodb-linux-x86_64-2.4.9.tgz
$ ls */bin
[abbreviated]
mongo
mongod
mongodump
mongoexport
mongoimport
mongorestore
mongos
mongostat
TokuMX
$ tar xzvf mongodb-linux-x86_64-2.4.9.tgz
$ ls */bin
[abbreviated]
mongo
mongo2toku
mongod
mongodump
mongoexport
mongoimport
mongorestore
mongos
mongostat](https://image.slidesharecdn.com/20140114-webinar-get-more-out-of-mongodb-with-tokumx-140319063324-phpapp02/85/Get-More-Out-of-MongoDB-with-TokuMX-9-320.jpg)

![mongo2toku?
TokuMX
$ tar xzvf tokumx-1.3.3-linux-x86_64.tgz
$ ls */bin
[abbreviated]
mongo
mongo2toku
mongod
mongodump
mongoexport
mongoimport
mongorestore
mongos
mongostat
• mongo2toku is a utility that
enables a TokuMX server to
process replication traffic
from a MongoDB master.
• The oplog format of
MongoDB is incompatible
with TokuMX, so they
cannot co-exist in a replica
set.](https://image.slidesharecdn.com/20140114-webinar-get-more-out-of-mongodb-with-tokumx-140319063324-phpapp02/85/Get-More-Out-of-MongoDB-with-TokuMX-11-320.jpg)












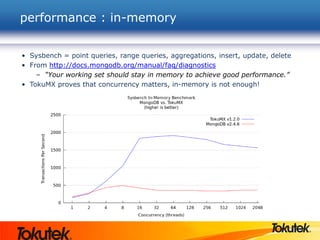
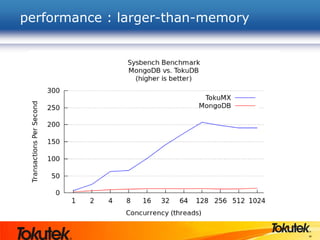
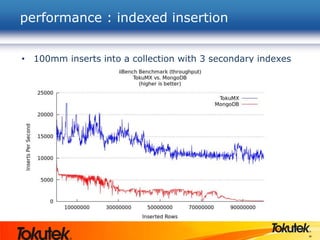







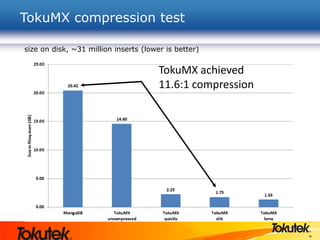
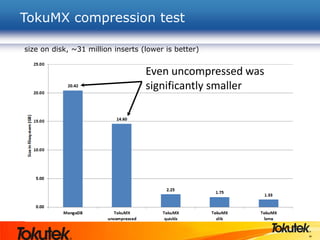
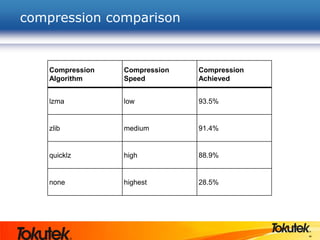








Tokutek, Inc. presents Tokumx, a high-performance version of MongoDB that enhances insertion speed by 20x and reduces storage requirements by up to 90% without requiring code rewrites. The webinar covers Tokumx's functionality, including improved replication, enhanced concurrency and indexing, built-in compression, and transactional support, distinguishing it from standard MongoDB. Tokumx is open source and aims to optimize database performance to meet big data demands.









































































