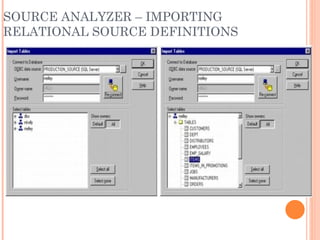
The document discusses key components of Informatica PowerCenter/PowerMart Designer including the designer workspace, tools, source analyzer, warehouse designer, and common transformations. The source analyzer can import relational and flat file sources. The warehouse designer creates and manages target definitions. Common transformations include expression, filter, joiner, lookup, and aggregator which can perform calculations, filtering, joining data, lookups, and aggregations respectively.





























































































































![chapter 2-DATABASE SYSTEM CONCEPTS AND architecture [Autosaved].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-databasesystemconceptsandarchitectureautosaved-230512145134-613f7180-thumbnail.jpg?width=640&height=640&fit=bounds)

































































