Download to read offline






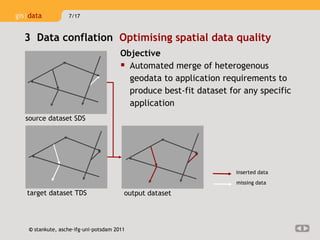



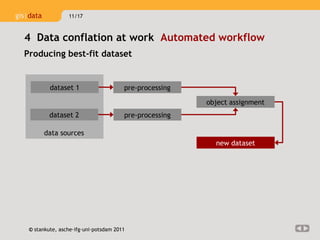







Data conflation is a process that optimizes spatial data quality by automatically merging heterogeneous geospatial datasets. It detects corresponding real-world features represented differently across datasets and combines their geometric and semantic information. For example, conflating datasets can identify a traffic roundabout modeled inconsistently and insert it accurately. By integrating multiple sources, conflation improves data completeness, positional accuracy, and temporal accuracy to produce an optimized dataset for applications.






























































































