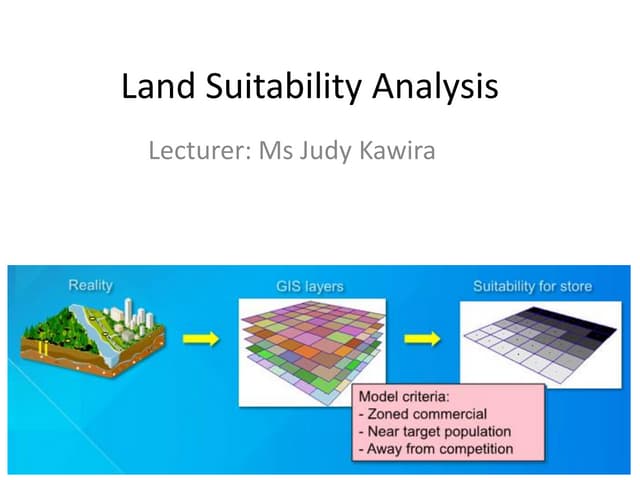
Introduction
GIS managesspatial and attribute data, but raw datasets often contain errors and
inconsistencies.
Data pre-processing ensures that datasets are accurate, standardised, and compatible
for analysis.
Without pre-processing, outputs from GIS analyses may be misleading or unreliable.
This stage is therefore critical for any scientific study or decision-making process.
3.
Why Pre-processing isImportant
Raw spatial datasets
may contain
geometric errors,
missing values, or
data noise.
01
Different sources
often provide data in
incompatible
formats and
projections.
02
Pre-processing
ensures consistency,
accuracy, and
comparability across
datasets.
03
It strengthens both
analytical reliability
and retrieval
efficiency in GIS.
04
4.
Types of
Spatial Data
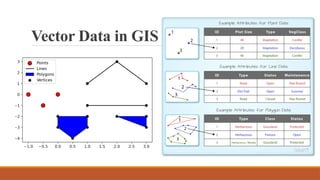
Vectordata represents discrete features such as
points, lines, and polygons.
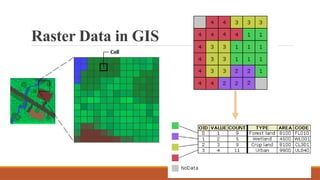
Raster data represents continuous phenomena
such as elevation or vegetation indices.
Attribute data provides descriptive details linked
to spatial features.
Metadata records dataset source, accuracy,
resolution, and standards.
Attribute Data andMetadata
Attribute data adds descriptive meaning to spatial features such as soil type or
vegetation cover.
Metadata explains the dataset source, accuracy, coordinate system, and resolution.
Metadata helps users evaluate dataset reliability and suitability for analysis.
International standards such as FGDC and ISO 19115 guide metadata documentation
9.
Common Sources ofSpatial Data
Remote sensing satellites
such as Landsat, Sentinel,
and MODIS provide
large-scale data.
Aerial surveys and
LiDAR deliver high-
resolution elevation and
canopy information.
GPS and GNSS systems
capture accurate field
locations for surveys and
sampling.
Open repositories such as
USGS Earth Explorer and
Copernicus Hub provide
free data access.
10.
Data Quality Issues
Positionalaccuracy measures how close mapped features are to true ground positions.
Attribute accuracy ensures the correctness and reliability of descriptive details.
Consistency checks ensure agreement between multiple datasets from different
sources.
Completeness verifies that all essential features are included in the dataset.
Resolution defines the adequacy of spatial, temporal, or spectral detail for analysis.
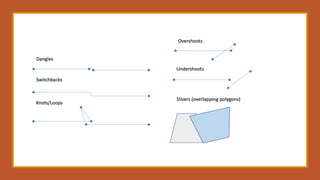
Objective 1: RemovingErrors
Geometric errors such as gaps, overlaps, or dangling nodes are corrected.
Duplicate or redundant features are removed to avoid bias in analysis.
Attribute inconsistencies like null values or typos are fixed during cleaning.
Raster datasets are filtered to reduce noise and improve accuracy.
14.
Objective 2: ConvertingData Formats
Datasets are converted between common vector formats such as SHP, KML, and GeoJSON.
Raster formats like GeoTIFF, IMG, and NetCDF are transformed for compatibility.
Coordinate reference systems are reprojected into a common framework.
Conversions ensure that datasets can be integrated across GIS platforms.
15.
Objective 3:
Improving
Efficiency
Vector geometriesare
generalised by reducing
unnecessary vertices.
Raster data is clipped to study
areas to minimise processing
loads.
Efficient formats such as
GeoPackage or compressed
GeoTIFF are used.
These methods reduce storage
needs and speed up computation.
16.
Objective 4: Multi-sourceIntegration
Data from different sources are harmonized in scale and resolution.
Coordinate systems are unified to allow seamless spatial overlay.
Attribute schemas are standardized to maintain consistency.
Integration supports combined analysis of satellite, survey, and statistical datasets.
17.
Objective 5: EnablingCorrect Analysis
Datasets are prepared to meet model and analytical tool requirements.
Attribute values and ranges are verified to avoid processing errors.
Extents and projections are aligned for accurate spatial operations.
Properly prepared data ensures reliable queries and database retrievals.
18.
Workflow
Overview
The pre-processing workflowfollows four main stages
before analysis.
Data acquisition involves collecting information from
diverse sources.
Data cleaning corrects errors in geometry, attributes,
and rasters.
Data transformation ensures format, resolution, and
projection compatibility.
Data reduction and generalization simplify datasets for
efficiency.
19.
Data Transformation
Coordinate systemsare converted to a unified projection such as UTM.
Data formats are transformed between raster and vector depending on use.
Raster datasets are resampled to achieve consistent resolution.
Scale and extent are matched to ensure compatibility across datasets.
20.
Data Reduction andGeneralization
Complex vector geometries are simplified while retaining spatial accuracy.
Polygons with shared attributes are dissolved to reduce data volume.
Multiple datasets are merged into a single integrated dataset.
Rasters and vectors are clipped to study areas to save processing time.
21.
Classification and Reclassification
Classificationassigns pixels or features into defined thematic categories.
Reclassification modifies raster values into new ranges for modeling.
Categories may be grouped into broader classes to simplify analysis.
These techniques support habitat models, risk assessments, and land cover studies
22.
Overlay Operations
Clip extractsfeatures within a defined spatial boundary.
Intersect retains only overlapping areas between multiple datasets.
Union combines all datasets while preserving full attribute information.
Erase removes features inside a selected boundary from the dataset.
23.
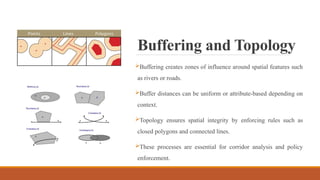
Buffering and Topology
Bufferingcreates zones of influence around spatial features such
as rivers or roads.
Buffer distances can be uniform or attribute-based depending on
context.
Topology ensures spatial integrity by enforcing rules such as
closed polygons and connected lines.
These processes are essential for corridor analysis and policy
enforcement.
24.
Interpolation and RasterPre-
processing
Interpolation predicts values at unsampled locations using IDW, Kriging, or Spline.
It is commonly used to create continuous surfaces such as rainfall or temperature maps.
Raster pre-processing involves radiometric, geometric, and atmospheric corrections.
Steps like mosaicking, cloud masking, and subsetting prepare rasters for analysis.
25.
Data Standardization andNormalization
Standardization converts attributes to a consistent scale for comparison.
Normalization ensures diverse datasets are transformed into compatible
formats.
These steps are critical for multi-criteria decision analysis.
26.
Data Format Conversion
Vectorformats such as SHP, GeoJSON, and GPKG are widely used for exchange.
Raster formats include GeoTIFF, IMG, HDF, and NetCDF for analysis.
CAD drawings in DWG or DXF can be integrated by converting to GIS formats.
OGC standards such as WMS, WFS, and GML enhance interoperability.
27.
Metadata and Retrieval
Metadataprovides information about dataset source, accuracy, and standards.
It helps researchers evaluate quality and select appropriate data for analysis.
Pre-processing organizes datasets into structured formats for easy access.
Spatial indexing techniques improve retrieval speed from large databases.
28.
Tools for Pre-processing
ArcGIS,QGIS, and GRASS GIS are widely used desktop pre-processing tools.
ERDAS Imagine, ENVI, and SNAP specialize in remote sensing raster corrections.
GDAL/OGR, Rasterio, and PyProj provide powerful command-line capabilities.
Automation is supported through ArcPy, PyQGIS, and R spatial packages
29.
Challenges in Pre-processing
Datasetsfrom different sources vary in quality and require harmonization.
Projection transformations may introduce distortions or mismatches.
Metadata is often incomplete, limiting reliability and usability.
Large datasets demand high storage capacity and computational resources.
Proprietary software tools may restrict access for some users.
References
Burrough, P. A.,& McDonnell, R. A. (1998). Principles of
geographical information systems. Oxford University Press.
Longley, P. A., Goodchild, M. F., Maguire, D. J., & Rhind, D. W.
(2011). Geographic information systems and science (3rd ed.). Wiley.
Heywood, I., Cornelius, S., & Carver, S. (2011). An introduction to
geographical information systems (4th ed.). Pearson Education.
Goodchild, M. F. (2010). Twenty years of progress: GIScience in
2010. Journal of Spatial Information Science, 1(1), 3–20.
Tomlinson, R. (2011). Thinking about GIS: Geographic information
system planning for managers (5th ed.). ESRI Press.
Foody, G. M., & Atkinson, P. M. (2002). Uncertainty in remote
sensing and GIS. Wiley.
GDAL/OGR contributors. (2023). GDAL/OGR geospatial data
abstraction library: Version 3.8.0. Open Source Geospatial Foundation.































![Spatial_Data_Analysis_with_open_source_softwares[1]](https://cdn.slidesharecdn.com/ss_thumbnails/8db4d971-8e8c-4fd8-8682-b20e5d6cd65f-161221072847-thumbnail.jpg?width=640&height=640&fit=bounds)