Downloaded 291 times





















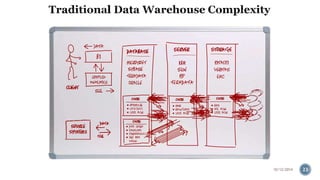






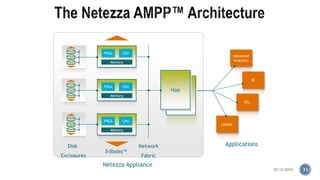
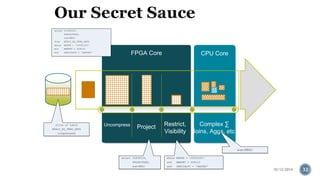
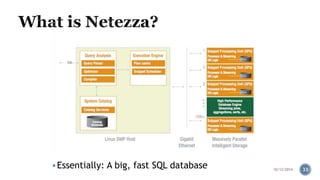







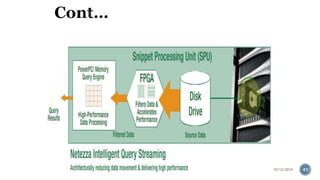

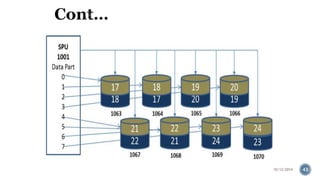


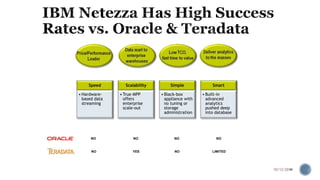




The document provides information about the IBM PureData System for Analytics (Netezza). It discusses the components and architecture of the IBM PureData System models, including the N1001 and N2001 models. It explains the key hardware components like snippet blades, hosts, and storage arrays and how they work together using Netezza's Asymmetric Massively Parallel Processing architecture to optimize analytics workloads.































































































