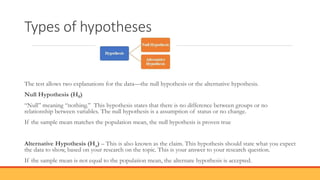
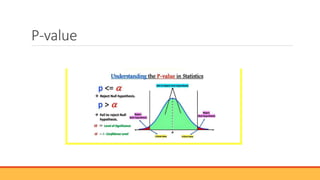
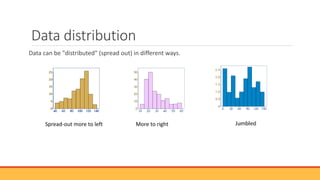
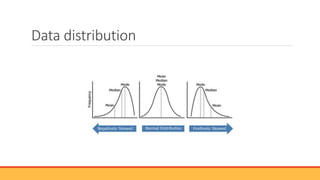
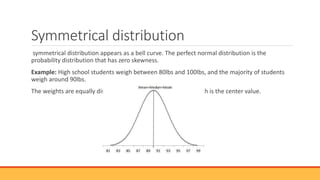
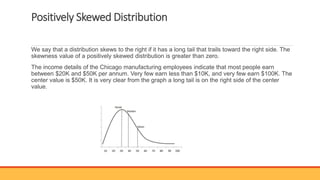
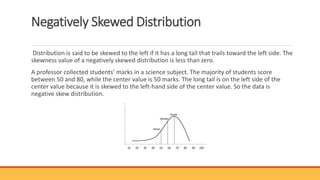
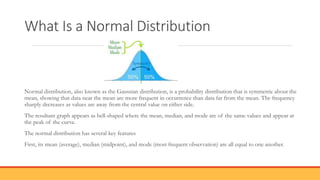
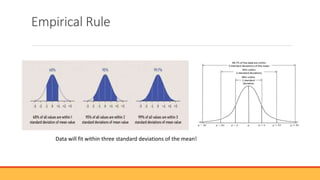
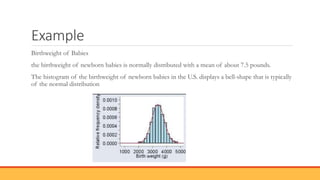
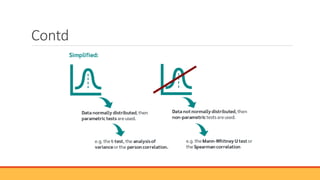
The document explains hypothesis testing in statistics, detailing concepts such as null and alternative hypotheses, significance levels, and p-values. It emphasizes the importance of testing assumptions against data to validate research claims across various fields, including healthcare and education. Additionally, it covers data distribution, correlation analysis, and various statistical tests used to analyze data relationships and differences among groups.