Downloaded 82 times




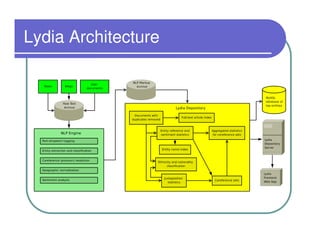
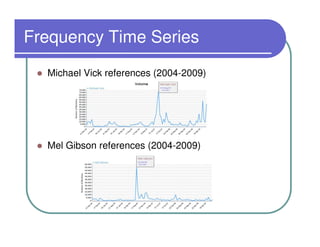
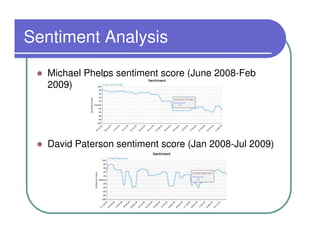
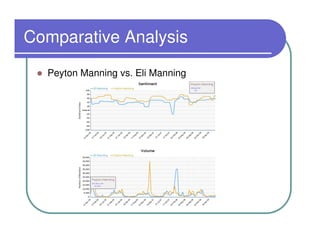
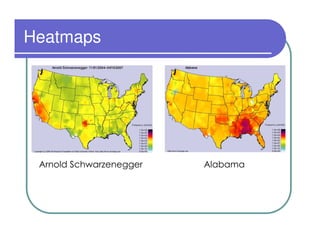


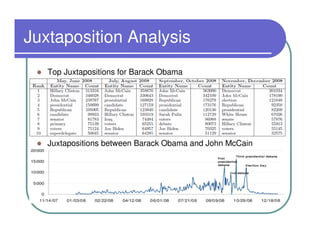


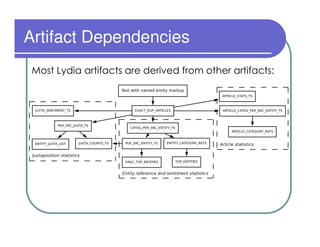

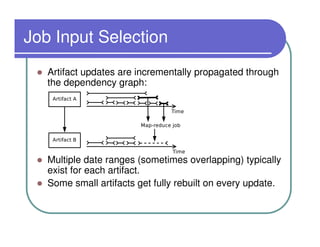
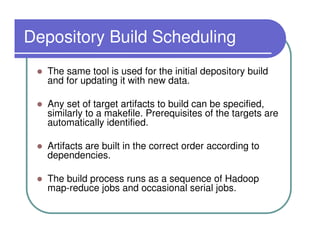


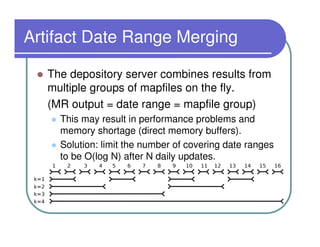


This document provides an overview of the Lydia news and blog analysis system. It discusses how Lydia performs named entity recognition and sentiment analysis on over 1,000 news sources and blogs daily. It also describes Lydia's use of Hadoop for distributed processing and Amazon EC2 for hosting its services. The document outlines Lydia's architecture, data workflow, access interfaces, and provides examples of different types of analysis it can perform.







































































































