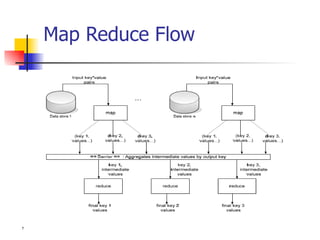
Apache Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It provides reliable storage through its distributed file system HDFS and scalable processing of large datasets through its MapReduce programming model. Hadoop has a master/slave architecture with a single NameNode master and multiple DataNode slaves. The NameNode manages the file system namespace and regulates access to files by clients. DataNodes store file system blocks and service read/write requests. MapReduce allows programmers to write distributed applications by implementing map and reduce functions. It automatically parallelizes tasks across clusters and handles failures. Hadoop is widely used by companies like Yahoo and Amazon to process massive amounts of data.