Downloaded 29 times





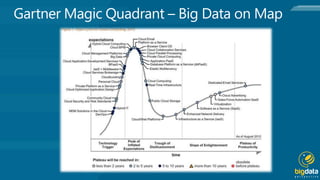

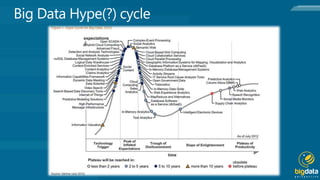






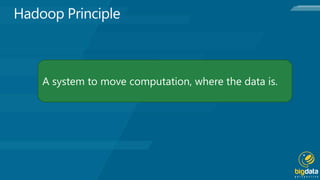






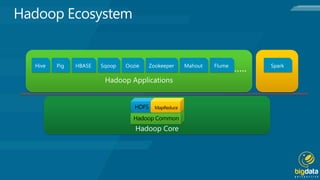
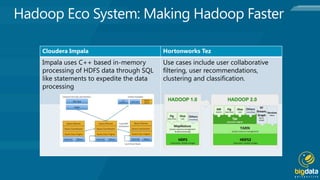






Hadoop is an open source platform for storing and processing large amounts of unstructured data across clusters of commodity hardware. It provides flexibility in storing various data types without schemas, and scales out workload by distributing data and processing across nodes. Hadoop is also fault tolerant, continuing operations even if nodes fail, and moves computation to where the data resides for efficiency. Key components include Hadoop Common, HDFS for storage, and MapReduce for distributed processing.


























































































