Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
N.Nakasato
754 views
Hpc148
第148回HPC研究会の発表スライド
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 18
2
/ 18
3
/ 18
4
/ 18
5
/ 18
6
/ 18
7
/ 18
8
/ 18
9
/ 18
10
/ 18
11
/ 18
12
/ 18
13
/ 18
14
/ 18
15
/ 18
16
/ 18
17
/ 18
18
/ 18
More Related Content
PDF
2015年度先端GPGPUシミュレーション工学特論 第13回 数値流体力学への応用 (高度な最適化)
by
智啓 出川
PDF
El text.tokuron a(2019).watanabe190613
by
RCCSRENKEI
PDF
2015年度GPGPU実践プログラミング 第7回 総和計算
by
智啓 出川
PDF
El text.tokuron a(2019).watanabe190606
by
RCCSRENKEI
PDF
GPGPU Seminar (GPU Accelerated Libraries, 2 of 3, cuSPARSE)
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第12回 偏微分方程式の差分計算
by
智啓 出川
PDF
2015年度先端GPGPUシミュレーション工学特論 第5回 GPUのメモリ階層の詳細 (様々なメモリの利用)
by
智啓 出川
PDF
2015年度先端GPGPUシミュレーション工学特論 第1回 先端シミュレーションおよび産業界におけるGPUの役割
by
智啓 出川
2015年度先端GPGPUシミュレーション工学特論 第13回 数値流体力学への応用 (高度な最適化)
by
智啓 出川
El text.tokuron a(2019).watanabe190613
by
RCCSRENKEI
2015年度GPGPU実践プログラミング 第7回 総和計算
by
智啓 出川
El text.tokuron a(2019).watanabe190606
by
RCCSRENKEI
GPGPU Seminar (GPU Accelerated Libraries, 2 of 3, cuSPARSE)
by
智啓 出川
2015年度GPGPU実践プログラミング 第12回 偏微分方程式の差分計算
by
智啓 出川
2015年度先端GPGPUシミュレーション工学特論 第5回 GPUのメモリ階層の詳細 (様々なメモリの利用)
by
智啓 出川
2015年度先端GPGPUシミュレーション工学特論 第1回 先端シミュレーションおよび産業界におけるGPUの役割
by
智啓 出川
What's hot
PDF
2015年度GPGPU実践プログラミング 第8回 総和計算(高度な最適化)
by
智啓 出川
PDF
GPGPU Seminar (GPU Accelerated Libraries, 3 of 3, Thrust)
by
智啓 出川
PDF
2015年度GPGPU実践基礎工学 第1回 学際的分野における先端シミュレーション技術の歴史
by
智啓 出川
PDF
2015年度先端GPGPUシミュレーション工学特論 第8回 偏微分方程式の差分計算 (拡散方程式)
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第10回 行列計算(行列-行列積の高度な最適化)
by
智啓 出川
PDF
GPGPU Seminar (PyCUDA)
by
智啓 出川
PDF
El text.tokuron a(2019).ishimura190725
by
RCCSRENKEI
PDF
El text.tokuron a(2019).katagiri190509
by
RCCSRENKEI
PDF
NumPy闇入門
by
Ryosuke Okuta
PDF
El text.tokuron a(2019).katagiri190425
by
RCCSRENKEI
PDF
200528material takahashi
by
RCCSRENKEI
PDF
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
PDF
Very helpful python code to find coefficients of the finite difference method
by
智啓 出川
PDF
El text.tokuron a(2019).yoshii190704
by
RCCSRENKEI
PDF
Intel GoldmontとMPXとゆるふわなごや
by
Masaki Ota
PDF
More modern gpu
by
Preferred Networks
PDF
2015年度先端GPGPUシミュレーション工学特論 第9回 偏微分方程式の差分計算 (移流方程式)
by
智啓 出川
PDF
200521material takahashi
by
RCCSRENKEI
PDF
2015年度GPGPU実践プログラミング 第9回 行列計算(行列-行列積)
by
智啓 出川
PDF
2015年度GPGPU実践プログラミング 第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
by
智啓 出川
2015年度GPGPU実践プログラミング 第8回 総和計算(高度な最適化)
by
智啓 出川
GPGPU Seminar (GPU Accelerated Libraries, 3 of 3, Thrust)
by
智啓 出川
2015年度GPGPU実践基礎工学 第1回 学際的分野における先端シミュレーション技術の歴史
by
智啓 出川
2015年度先端GPGPUシミュレーション工学特論 第8回 偏微分方程式の差分計算 (拡散方程式)
by
智啓 出川
2015年度GPGPU実践プログラミング 第10回 行列計算(行列-行列積の高度な最適化)
by
智啓 出川
GPGPU Seminar (PyCUDA)
by
智啓 出川
El text.tokuron a(2019).ishimura190725
by
RCCSRENKEI
El text.tokuron a(2019).katagiri190509
by
RCCSRENKEI
NumPy闇入門
by
Ryosuke Okuta
El text.tokuron a(2019).katagiri190425
by
RCCSRENKEI
200528material takahashi
by
RCCSRENKEI
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
Very helpful python code to find coefficients of the finite difference method
by
智啓 出川
El text.tokuron a(2019).yoshii190704
by
RCCSRENKEI
Intel GoldmontとMPXとゆるふわなごや
by
Masaki Ota
More modern gpu
by
Preferred Networks
2015年度先端GPGPUシミュレーション工学特論 第9回 偏微分方程式の差分計算 (移流方程式)
by
智啓 出川
200521material takahashi
by
RCCSRENKEI
2015年度GPGPU実践プログラミング 第9回 行列計算(行列-行列積)
by
智啓 出川
2015年度GPGPU実践プログラミング 第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
by
智啓 出川
Similar to Hpc148
PDF
optimal Ate pairing
by
MITSUNARI Shigeo
PDF
機械学習とこれを支える並列計算 : 並列計算の現状と産業応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
PDF
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
by
MITSUNARI Shigeo
PDF
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
PPTX
GPUによる多倍長整数乗算の高速化手法の提案
by
Koji Kitano
PPTX
Cvim saisentan 半精度浮動小数点数 half
by
tomoaki0705
PPTX
Myoshimi extreme
by
Masato Yoshimi
PDF
動的計画法の並列化
by
Proktmr
PDF
暗号技術の実装と数学
by
MITSUNARI Shigeo
PPT
第6回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
PPT
20030203 doctor thesis_presentation_makotoshuto
by
Makoto Shuto
PDF
HPC Phys-20201203
by
MITSUNARI Shigeo
PDF
CMSI計算科学技術特論B(6) 大規模系での高速フーリエ変換1
by
Computational Materials Science Initiative
PDF
フラグを愛でる
by
MITSUNARI Shigeo
PDF
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
PDF
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
PDF
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10)
by
Ryuuta Tsunashima
PDF
2015年度先端GPGPUシミュレーション工学特論 第6回 プログラムの性能評価指針 (Flop/Byte,計算律速,メモリ律速)
by
智啓 出川
PPTX
8 並列計算に向けた pcセッティング
by
Takeshi Takaishi
PPTX
DIC-PCGソルバーのpimpleFoamに対する時間計測と高速化
by
Fixstars Corporation
optimal Ate pairing
by
MITSUNARI Shigeo
機械学習とこれを支える並列計算 : 並列計算の現状と産業応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
by
MITSUNARI Shigeo
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
GPUによる多倍長整数乗算の高速化手法の提案
by
Koji Kitano
Cvim saisentan 半精度浮動小数点数 half
by
tomoaki0705
Myoshimi extreme
by
Masato Yoshimi
動的計画法の並列化
by
Proktmr
暗号技術の実装と数学
by
MITSUNARI Shigeo
第6回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
20030203 doctor thesis_presentation_makotoshuto
by
Makoto Shuto
HPC Phys-20201203
by
MITSUNARI Shigeo
CMSI計算科学技術特論B(6) 大規模系での高速フーリエ変換1
by
Computational Materials Science Initiative
フラグを愛でる
by
MITSUNARI Shigeo
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10)
by
Ryuuta Tsunashima
2015年度先端GPGPUシミュレーション工学特論 第6回 プログラムの性能評価指針 (Flop/Byte,計算律速,メモリ律速)
by
智啓 出川
8 並列計算に向けた pcセッティング
by
Takeshi Takaishi
DIC-PCGソルバーのpimpleFoamに対する時間計測と高速化
by
Fixstars Corporation
Hpc148
1.
整数演算による多倍長浮動小数点演算 エミュレーションのGPUでの性能評価 中里直人(会津大学) 2015年3月2-3日 第148回HPC研究発表会 花菱ホテル@別府温泉
2.
多倍長浮動小数点演算の必要性 • 数値不安定なアルゴリズム • 情報落ち,
桁落ちの問題 • ファインマン・ダイアグラムの直接計算 • 本質的に数値誤差が問題になる場合 • 丸め誤差の蓄積 • 演算性能が向上するとよりシビアに
3.
問題例:Henon Map Searching for
sinks of Henon map using a multiple-precision GPU arithmetic library M. Joldes, V. Popescu, W. Tucker, HEART2014 ha,b(x1, x2) = (1 + x2 ax2 1, bx1) ns: hi+1 a,b := ha,b hi a,b, i 2 N⇤ . parameter values a = 1.4, b = 0.3 one observes the so-called H´enon iterating hn a,b, n ! 1: 1 / 23 H´enon attractor H´enon Map ha,b(x1, x2) = (1 + x2 ax2 1, bx1) Map iterations: hi+1 a,b := ha,b hi a,b, i 2 N⇤ . For classical parameter values a = 1.4, b = 0.3 one observes the so-called H´enon attractor by iterating hn a,b, n ! 1: 1 / 23 異なるa,bや初期位置からの計算 を繰り返して、興味のある場合 を発見する問題。 ! 繰り返し計算による丸め誤差の 蓄積が問題となる。 誤差の軌道への影響は指数関数的
4.
多倍長精度FP演算手法(1) エラーフリー変換に基づく手法 (FP方式) • 変数を複数のFP変数の組み合わせで表現する •
プロセッサのFP演算器を援用可能 • 演算密度が高いアルゴリズム • 欠点:指数部(Nexp)がnativeなFPフォーマットに依存する • エラーフリー変換・総和アルゴリズム • 加算 Knuth(1967), 乗算 Dekker(1971) • 任意の場合のアルゴリズム Shewchuk(1996) • QD library (Hida etal. 2001) • GPUでの実装がいくつかある。GEMM,BLASは高性能
5.
多倍長精度FP演算手法(2) 整数演算によるエミュレーション手法(Int方式) • GNU Multiple
Precision Arithmetic Library (GMP) • FPを含めて様々な多倍長精度演算アルゴリズムを実装 • FPについては基本演算と簡単な関数のみ • GNU MPFR (Fousse etal. 2007) • GMPをベースにより汎用的なFP演算の実装 • 一般的な数学関数含む • CUMP (Nakayama & Takahashi 2011) • GMPの一部(加算・乗算)をCUDAカーネルとして移植 • C++ templateを利用しているためOpenCL化難しい
6.
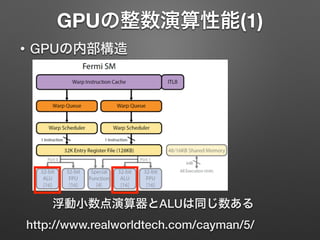
GPUの整数演算性能(1) • GPUの内部構造 ! ! ! ! ! http://www.realworldtech.com/cayman/5/ 浮動小数点演算器とALUは同じ数ある
7.
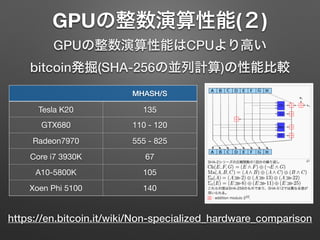
GPUの整数演算性能(2) GPUの整数演算性能はCPUより高い bitcoin発掘(SHA-256の並列計算)の性能比較 MHASH/S Tesla K20 135 GTX680
110 - 120 Radeon7970 555 - 825 Core i7 3930K 67 A10-5800K 105 Xoen Phi 5100 140 https://en.bitcoin.it/wiki/Non-specialized_hardware_comparison
8.
本研究の目的 • 多倍長精度浮動小数点演算をOpenCLにより 高速化する手法を性能評価する • GPUの整数演算性能を有効に利用することを想定 •
GPU, CPU, MIC, FPGAなどで同様のアルゴリズムが実行可能 • GRAPE-MP/MPXと対応する実装 • 独自設計によるFP演算器と同じアルゴリズムを採用 • 他の実装(QD, MPFR)との比較
9.
データ構造報処理学会研究報告 SJ SIG Technical
Report FP 演算における主たる処理は仮数部同士の演算であ 上記 (b) の手法は, 整数演算により複数語からなる仮 部の演算を, 四則演算それぞれの場合ついて筆算と同様 アルゴリズムでおこなう (例えば”The Art of Computer ogramming Volume 2”[8](TACP Vol.2) Section 4.3 参 ). ただし, 乗算 [9] と除算 [6] について, 筆算と同様の基 アルゴリズムよりも演算数を削減することのできるア ゴリズムが提案されている. この FP 演算のエミュレー ョンによる多倍長演算手法では, 原理的には指数部, 仮数 ともに任意のビット長を利用することができる. よって, 記ファインマン・ダイアグラムの直接計算の場合におけ 指数部サイズの制限の問題の解決策となる. 本論文では, (b) の手法による FP 演算を C 言語により 計・実装し, それを OpenCL カーネルとして利用可能と ることで, OpenCL でプログラム可能なマルチコア・メ typedef uint32_t u32; const u32 NC = 7; struct my_fp { u32 e; u32 m[NC]; }; typedef struct my_fp FP[1]; 図 1 本論文における多倍長精 めす. この構造体 FP では, FP- する. FP->e の最上位の 1 ビッ 30 ビットに指数部を保持する仕 754 規格にならって, バイアス とした. nexp = 30 より, この場 0x3fffffff となる. FP->m[] は仮 指数部と同様に符号なし 2 進数 • 符号なし整数の配列に格納 • 指数部に1語。bias方式 • 符号は指数部に格納する • 仮数部にn語 • 仮数部は1語当たり30 bitに分割。n = 7, 210 bit • hidden bitはなし ! • 32 bit vs. 64 bitの選択 • GPUの演算器は32 bitのはず。より冗長。今回はこちらを採用 • CPU(x86-64)は64 bit演算のほうが効率よい。GMPはこれ 指数部 仮数部[0] 仮数部[1] 仮数部[2] 符号 仮数部[3]
10.
アルゴリズムの概要(1) • C言語で実装テストし、OpenCLカーネル化 • ソースは共通化可能 •
加算・減算 • uint32の加算, マスク演算, シフト演算の組み合わせ • IEEE 754と同様のアルゴリズムだが丸めはforce-1 • 減算は加算の前に符号反転で実装 • 乗算 • TACP Vol.2のアルゴリズムと同様 • 仮数部同士の乗算は省略なし(49個の部分積の和をとる) • 32 x 32 の符号なし乗算
11.
アルゴリズムの概要(2) • 除算は3パターンを実装し比較 • 仮数部を直接計算 •
Huang etal.の高速アルゴリズムで仮数部の除算を計算 • TACPのアルゴリズムより平均的に3倍高速 • ニュートン法 • ニュートン法で逆数を求めてから乗算 • 初期値は単精度(SP)または倍精度(DP)で計算 • SPの場合3回, DPの場合2回のニュートンループ
12.
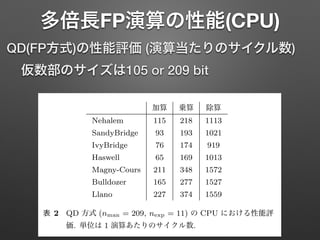
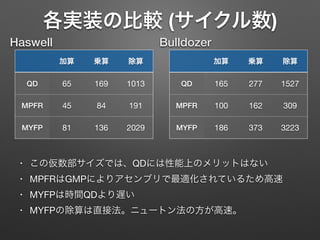
多倍長FP演算の性能(CPU) QD(FP方式)の性能評価 (演算当たりのサイクル数) 仮数部のサイズは105 or
209 bit IvyBridge 51 85 185 Haswell 45 84 191 Magny-Cours 92 145 332 Bulldozer 100 162 309 Llano 115 156 344 表 1 MPFR 方式 (nman = 210, nexp = 64) の CPU における性 能評価. 単位は 1 演算あたりのサイクル数. 加算 乗算 除算 Nehalem 115 218 1113 SandyBridge 93 193 1021 IvyBridge 76 174 919 Haswell 65 169 1013 Magny-Cours 211 348 1572 Bulldozer 165 277 1527 Llano 227 374 1559 表 2 QD 方式 (nman = 209, nexp = 11) の CPU における性能評 価. 単位は 1 演算あたりのサイクル数. 表では してい Stamp た. ど に RD 回数で 定した QD 方式は されて およそ 倍のサ 本表 IvyBri され, 演 進歩を が, ほと
13.
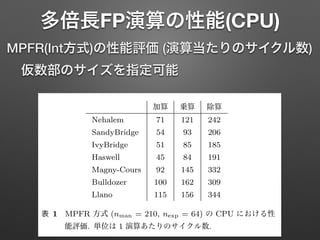
多倍長FP演算の性能(CPU) 情報処理学会研究報告 IPSJ SIG Technical
Report 加算 乗算 除算 Nehalem 71 121 242 SandyBridge 54 93 206 IvyBridge 51 85 185 Haswell 45 84 191 Magny-Cours 92 145 332 Bulldozer 100 162 309 Llano 115 156 344 表 1 MPFR 方式 (nman = 210, nexp = 64) の CPU における性 能評価. 単位は 1 演算あたりのサイクル数. QD L 5.1.3, 価で利 表では してい Stamp た. ど に RD 回数で 定した MPFR(Int方式)の性能評価 (演算当たりのサイクル数) 仮数部のサイズを指定可能
14.
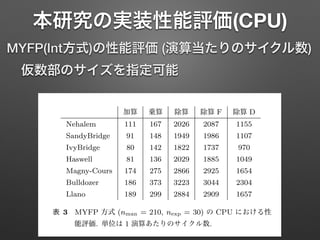
本研究の実装性能評価(CPU) MYFP(Int方式)の性能評価 (演算当たりのサイクル数) 仮数部のサイズを指定可能 情報処理学会研究報告 IPSJ SIG
Technical Report 加算 乗算 除算 除算 F 除算 D Nehalem 111 167 2026 2087 1155 SandyBridge 91 148 1949 1986 1107 IvyBridge 80 142 1822 1737 970 Haswell 81 136 2029 1885 1049 Magny-Cours 174 275 2866 2925 1654 Bulldozer 186 373 3223 3044 2304 Llano 189 299 2884 2909 1657 表 3 MYFP 方式 (nman = 210, nexp = 30) の CPU における性 能評価. 単位は 1 演算あたりのサイクル数. 性能が高 かる. G ないが, ト ALU れる. た る場合が のマイク る同一の ドのバー 傾向は,
15.
各実装の比較 (サイクル数) 加算 乗算
除算 QD 65 169 1013 MPFR 45 84 191 MYFP 81 136 2029 加算 乗算 除算 QD 165 277 1527 MPFR 100 162 309 MYFP 186 373 3223 Haswell Bulldozer • この仮数部サイズでは、QDには性能上のメリットはない • MPFRはGMPによりアセンブリで最適化されているため高速 • MYFPは時間QDより遅い • MYFPの除算は直接法。ニュートン法の方が高速。
16.
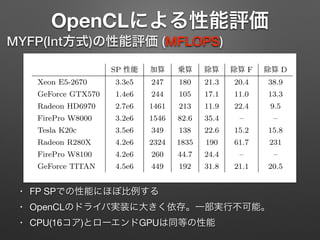
OpenCLによる性能評価 MYFP(Int方式)の性能評価 (MFLOPS) 告 Report SP 性能
加算 乗算 除算 除算 F 除算 D Xeon E5-2670 3.3e5 247 180 21.3 20.4 38.9 GeForce GTX570 1.4e6 244 105 17.1 11.0 13.3 Radeon HD6970 2.7e6 1461 213 11.9 22.4 9.5 FirePro W8000 3.2e6 1546 82.6 35.4 – – Tesla K20c 3.5e6 349 138 22.6 15.2 15.8 Radeon R280X 4.2e6 2324 1835 190 61.7 231 FirePro W8100 4.2e6 260 44.7 24.4 – – GeForce TITAN 4.5e6 449 192 31.8 21.1 20.5 表 4 MYFP 方式 (nman = 210, nexp = 30) の CPU における性能評価. 単位は MPFLOS. sium on Computer Architecture, pp. 287– n Software Directory: . • FP SPでの性能にほぼ比例する • OpenCLのドライバ実装に大きく依存。一部実行不可能。 • CPU(16コア)とローエンドGPUは同等の性能
17.
応用例 1 4 Sample)code:)) 20# #pragma#goose#parallel#for#loopcounter(ixy,#iz)# #for(ixy#=#0;#ixy#<#ni;#ixy++)#{# #####sumzG[ixy]#=#0.0;# #####for#(iz#=#0;#iz#<#nj;#iz++)#{# ###########xx#=#dev_xx[ixy];# ###########yy#=#dev_yy[ixy];# ###########zz#=#x30_1[iz]#*#dev_cnt4[ixy];# ######d#=#K#xx#*#yy#*#s# #########L#*#zz#*#(one#K#xx#K#yy#K#zz)#+# #########(xx#+#yy)#*#lambda2#+# #########(one#K#xx#K#yy#K#zz)#*#(one#K#xx#K#yy)#*#fme2+# #########zz#*#(one#K#xx#K#yy)#*#fmf2#;# #########sumzG[ixy]#+=#gw30[iz]#/#(d#*#d);# #####}# #}# •
Gooseの拡張を実装 • pragma文からループをOpenCL API呼び出しに変換する • ループ本体は直接OpenCLカーネルへ変換 • 各種OpenCL実装での動作、性能評価をしている
18.
まとめ • 多倍長精度浮動小数点演算をOpenCLにより 実装し性能評価した • 様々なOpenCLデバイスで動作可能 •
GPUでの整数演算性能が有効に利用できる • GPU(Radeon R280X)はCPU(16コア)より10倍以上高速 • QD, MPFRの性能評価と比較 • 八倍精度相当ではMPFRのCPUでの性能は非常によい • QDには性能上のメリットはない • MYFPはMPFRの半分位の性能。除算の低速。 • 条件文を削減するなどの最適化が必要
Download







 Section 4.3 参
). ただし, 乗算 [9] と除算 [6] について, 筆算と同様の基
アルゴリズムよりも演算数を削減することのできるア
ゴリズムが提案されている. この FP 演算のエミュレー
ョンによる多倍長演算手法では, 原理的には指数部, 仮数
ともに任意のビット長を利用することができる. よって,
記ファインマン・ダイアグラムの直接計算の場合におけ
指数部サイズの制限の問題の解決策となる.
本論文では, (b) の手法による FP 演算を C 言語により
計・実装し, それを OpenCL カーネルとして利用可能と
ることで, OpenCL でプログラム可能なマルチコア・メ
typedef uint32_t u32;
const u32 NC = 7;
struct my_fp {
u32 e;
u32 m[NC];
};
typedef struct my_fp FP[1];
図 1 本論文における多倍長精
めす. この構造体 FP では, FP-
する. FP->e の最上位の 1 ビッ
30 ビットに指数部を保持する仕
754 規格にならって, バイアス
とした. nexp = 30 より, この場
0x3fffffff となる. FP->m[] は仮
指数部と同様に符号なし 2 進数
• 符号なし整数の配列に格納
• 指数部に1語。bias方式
• 符号は指数部に格納する
• 仮数部にn語
• 仮数部は1語当たり30 bitに分割。n = 7, 210 bit
• hidden bitはなし
!
• 32 bit vs. 64 bitの選択
• GPUの演算器は32 bitのはず。より冗長。今回はこちらを採用
• CPU(x86-64)は64 bit演算のほうが効率よい。GMPはこれ
指数部 仮数部[0] 仮数部[1] 仮数部[2]
符号
仮数部[3]](https://image.slidesharecdn.com/uuyh0ifr6rdgdgo8jp4g-signature-8405f8ac042c7239865e58ec73be0cc6ec475f2fb877abdcf82bc1dcc62f91cb-poli-150306004234-conversion-gate01/85/Hpc148-9-320.jpg)


![応用例
1 4 Sample)code:))
20#
#pragma#goose#parallel#for#loopcounter(ixy,#iz)#
#for(ixy#=#0;#ixy#<#ni;#ixy++)#{#
#####sumzG[ixy]#=#0.0;#
#####for#(iz#=#0;#iz#<#nj;#iz++)#{#
###########xx#=#dev_xx[ixy];#
###########yy#=#dev_yy[ixy];#
###########zz#=#x30_1[iz]#*#dev_cnt4[ixy];#
######d#=#K#xx#*#yy#*#s#
#########L#*#zz#*#(one#K#xx#K#yy#K#zz)#+#
#########(xx#+#yy)#*#lambda2#+#
#########(one#K#xx#K#yy#K#zz)#*#(one#K#xx#K#yy)#*#fme2+#
#########zz#*#(one#K#xx#K#yy)#*#fmf2#;#
#########sumzG[ixy]#+=#gw30[iz]#/#(d#*#d);#
#####}#
#}#
• Gooseの拡張を実装
• pragma文からループをOpenCL API呼び出しに変換する
• ループ本体は直接OpenCLカーネルへ変換
• 各種OpenCL実装での動作、性能評価をしている](https://image.slidesharecdn.com/uuyh0ifr6rdgdgo8jp4g-signature-8405f8ac042c7239865e58ec73be0cc6ec475f2fb877abdcf82bc1dcc62f91cb-poli-150306004234-conversion-gate01/85/Hpc148-17-320.jpg)
















































