
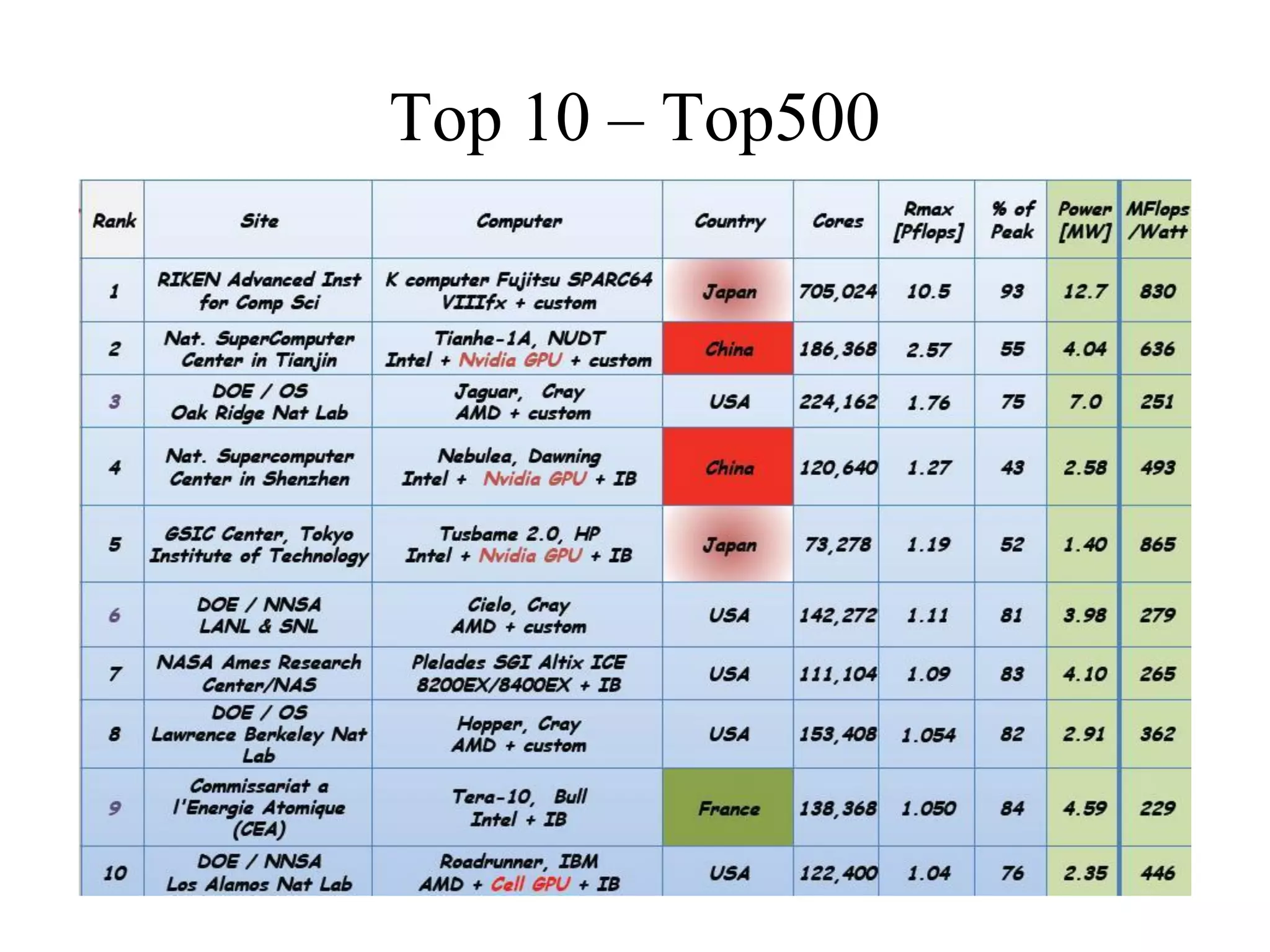
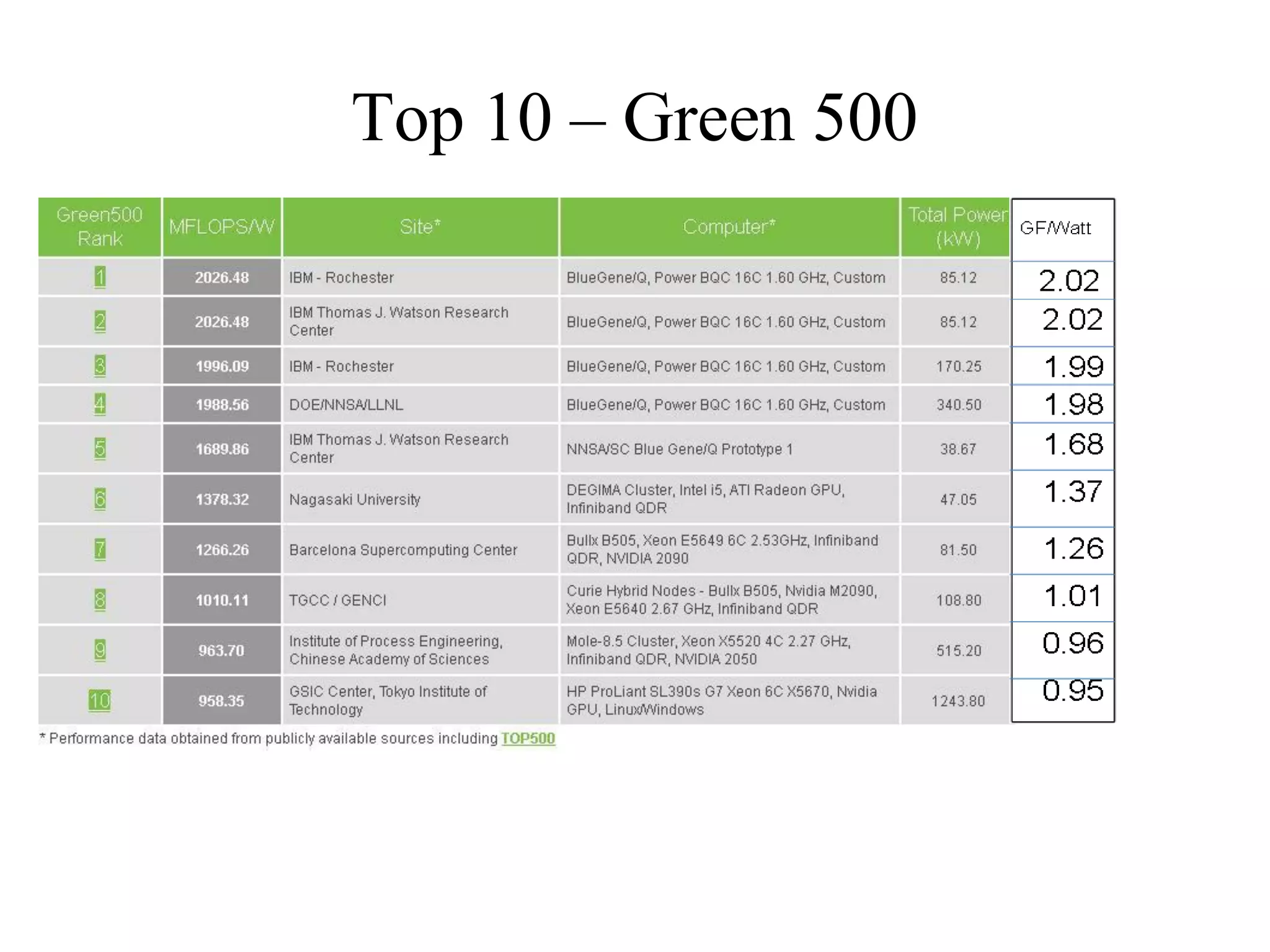
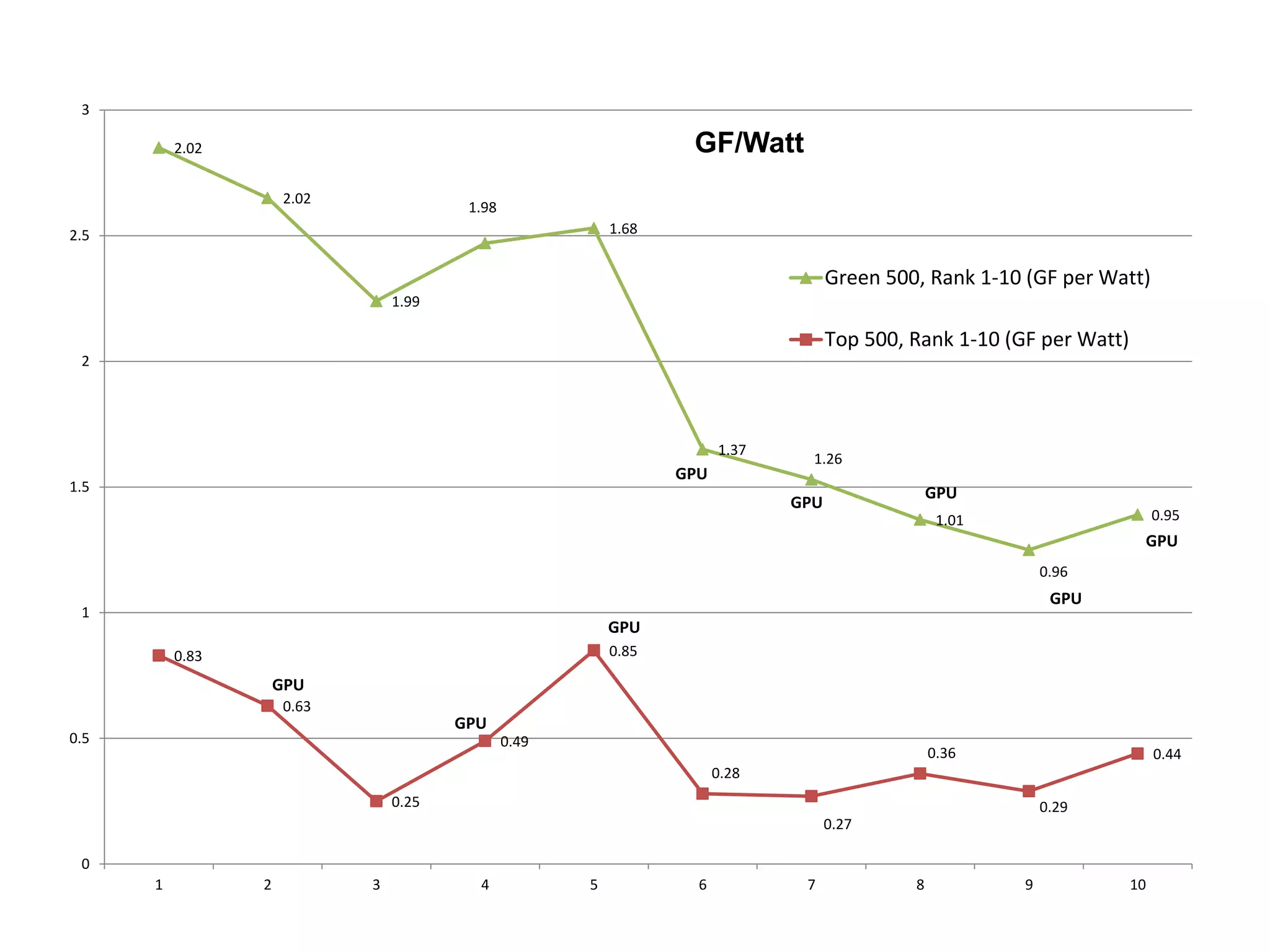




](https://image.slidesharecdn.com/iitk-symposium-121010055011-phpapp01/75/Symposium-on-HPC-Applications-IIT-Kanpur-9-2048.jpg)


C. Hsu & W. Feng - Proc. of the 2005 ACM/IEEE conference on Supercomputing](https://image.slidesharecdn.com/iitk-symposium-121010055011-phpapp01/75/Symposium-on-HPC-Applications-IIT-Kanpur-11-2048.jpg)

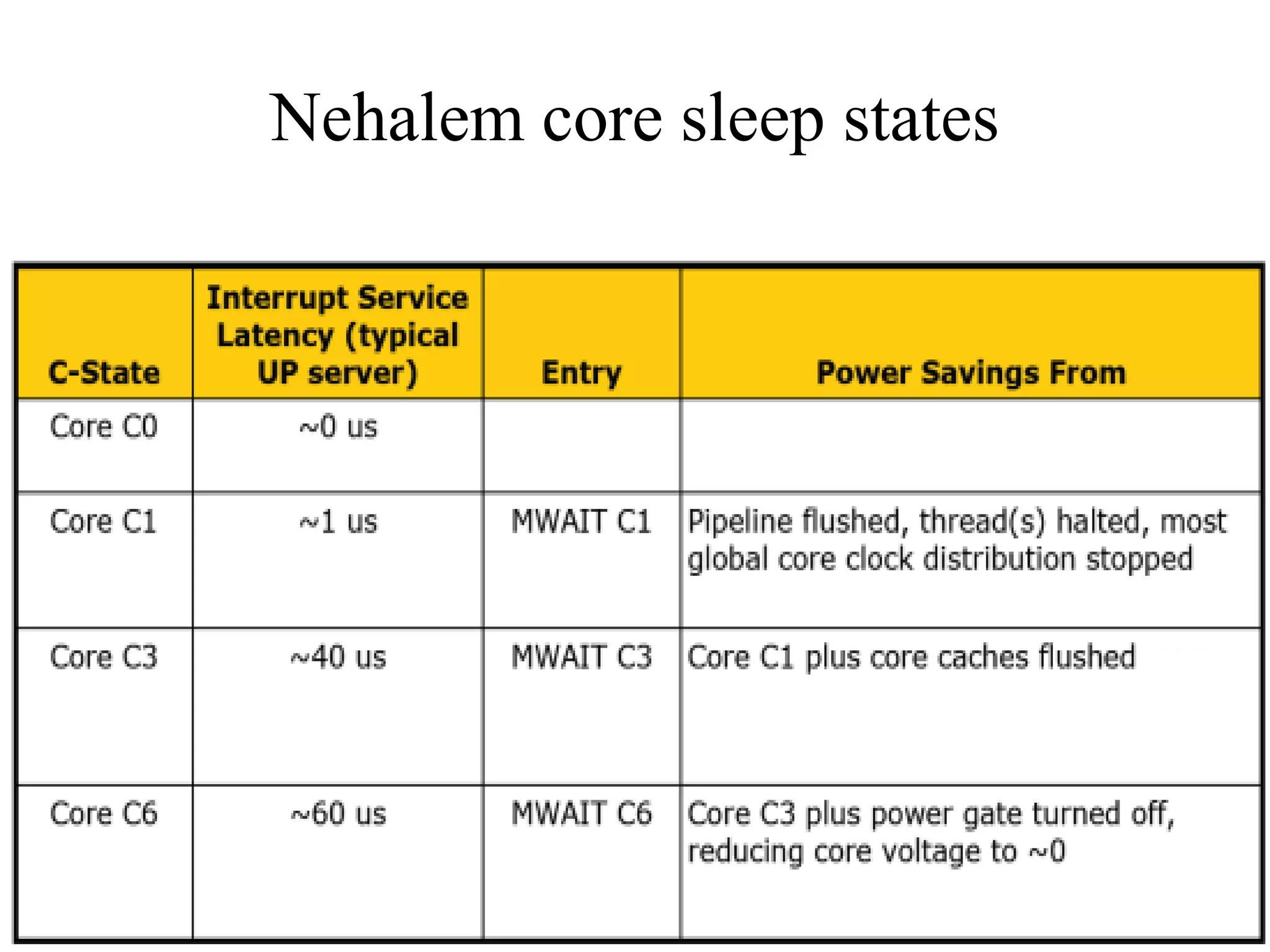
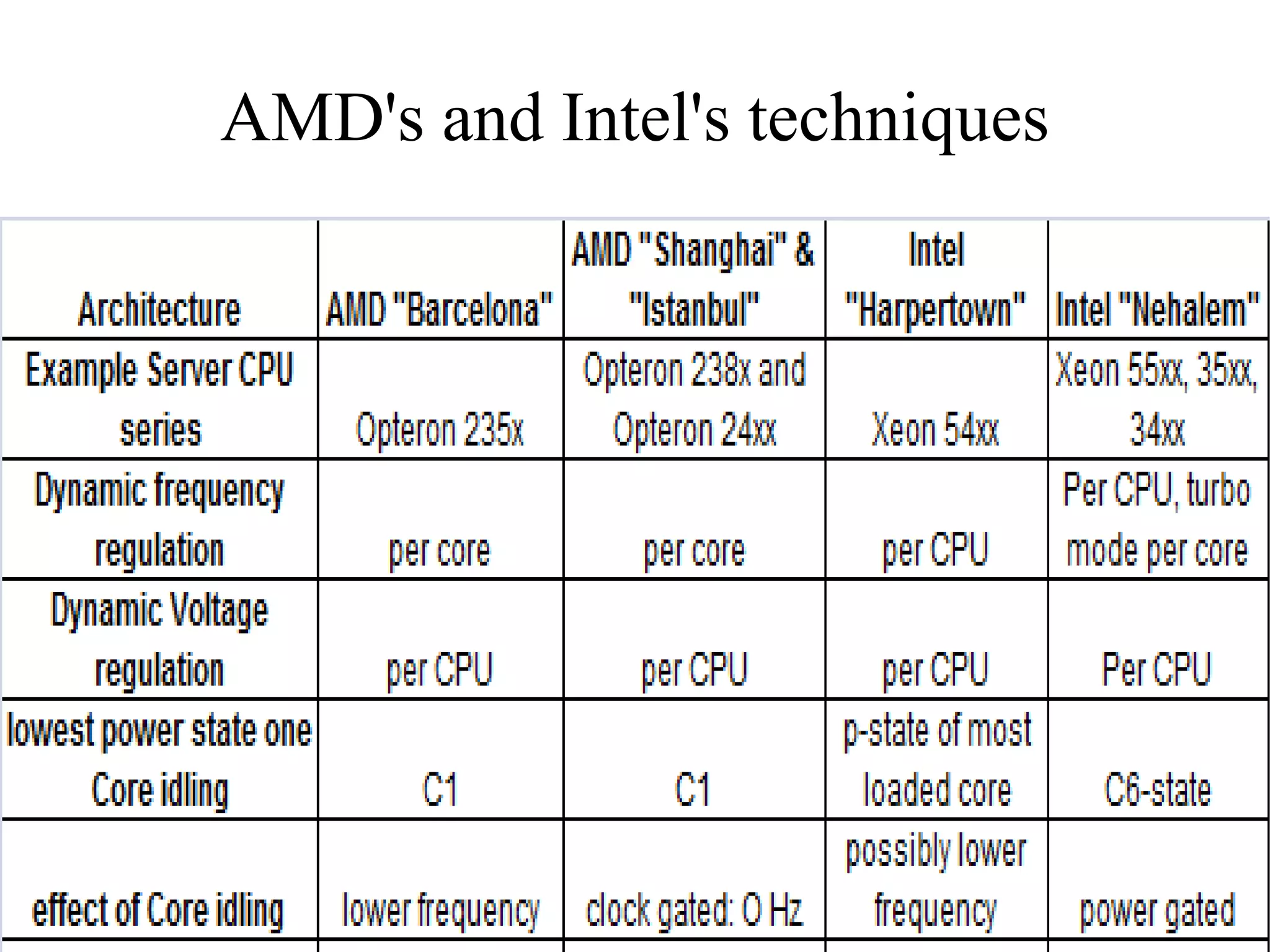
![Enhancements in DVFS
Clock gating
Clock disabled sleep state (AMD-C1,E1, Intel-
C[0,1,3,6])
At the CPU block level
At the core level
Reduces dynamic power
Power Gating
Power to CPU/core cut off (~0V)
Reduces both dynamic and static(leakage) power](https://image.slidesharecdn.com/iitk-symposium-121010055011-phpapp01/75/Symposium-on-HPC-Applications-IIT-Kanpur-13-2048.jpg)


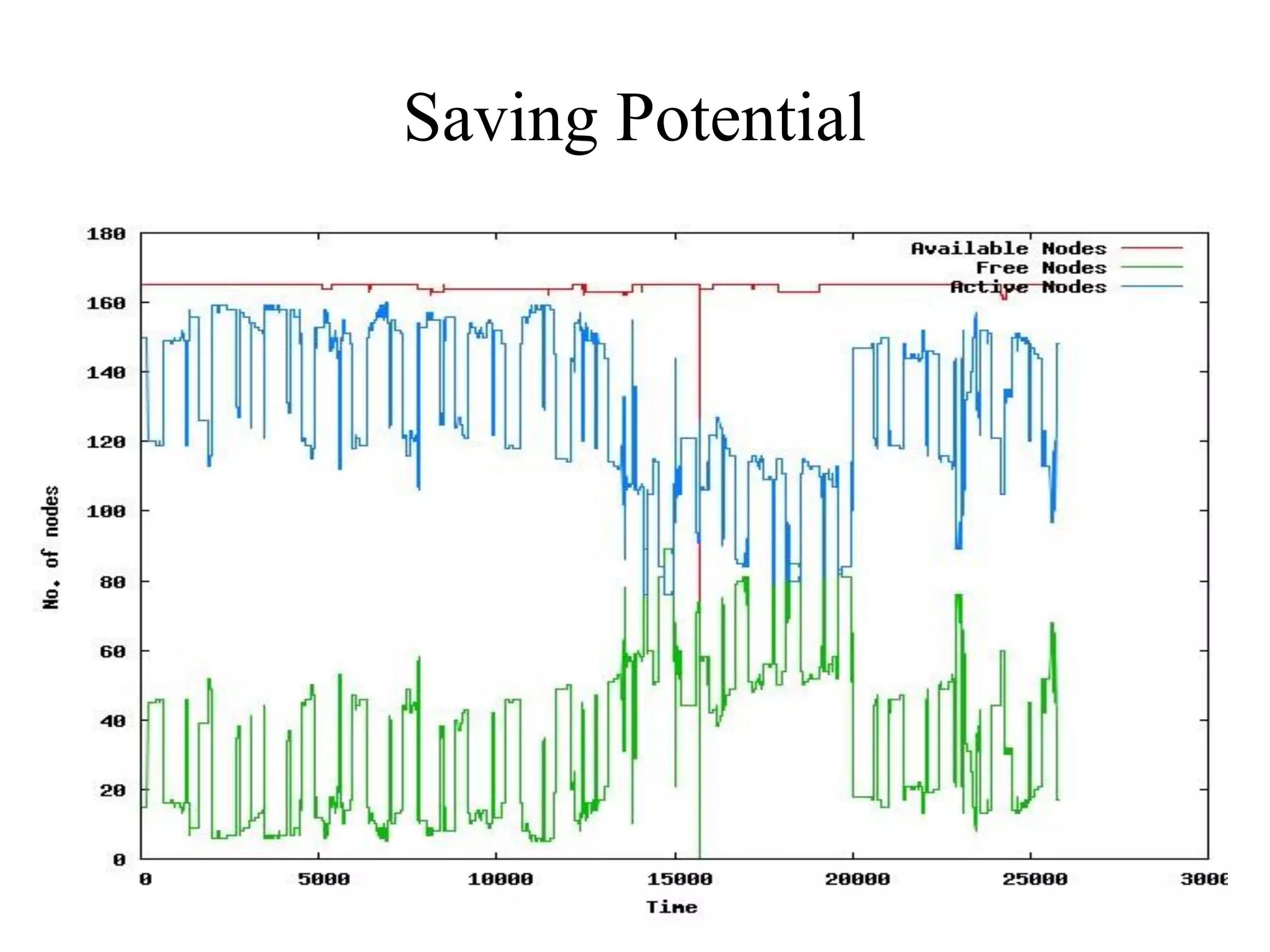
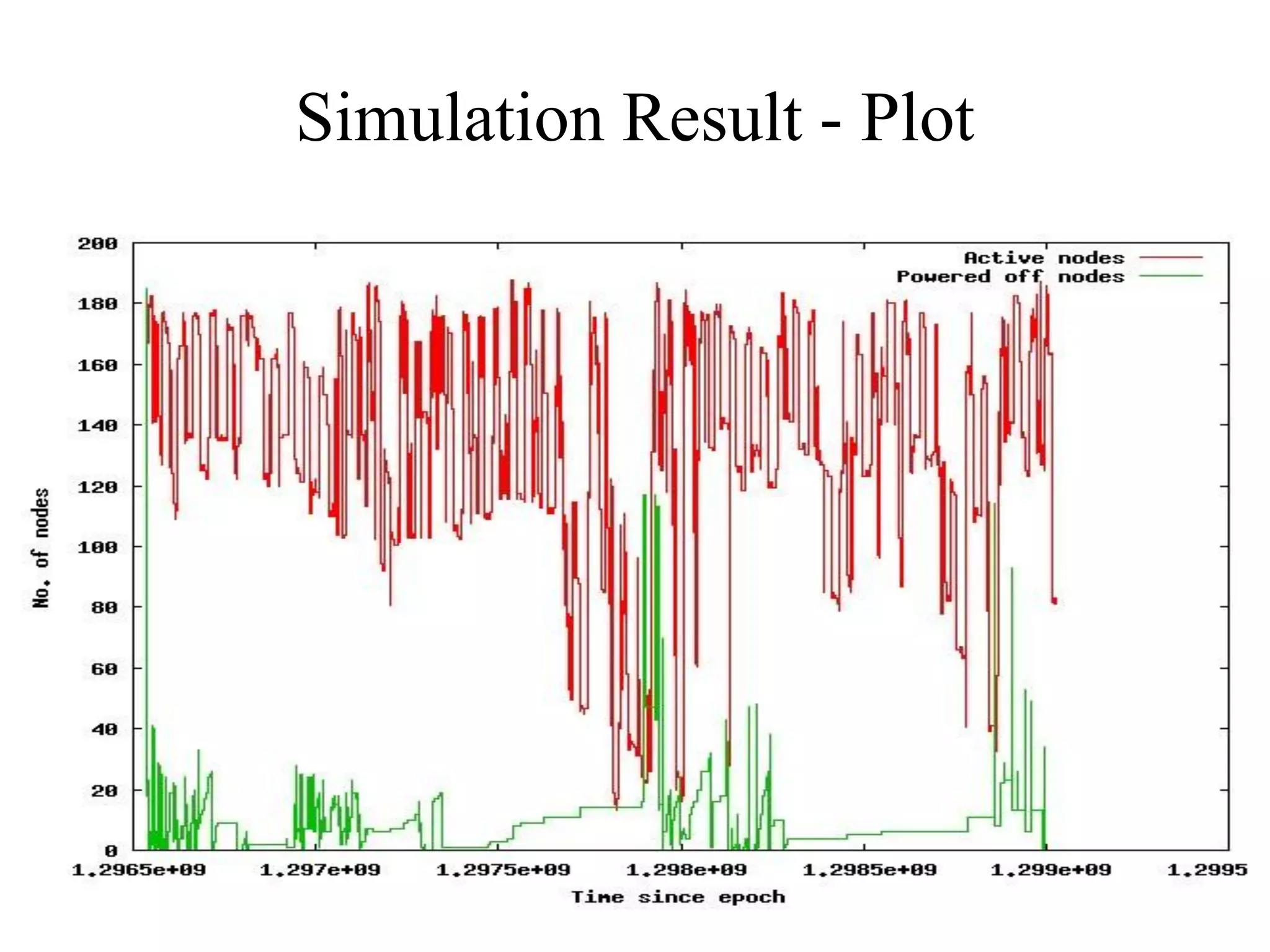
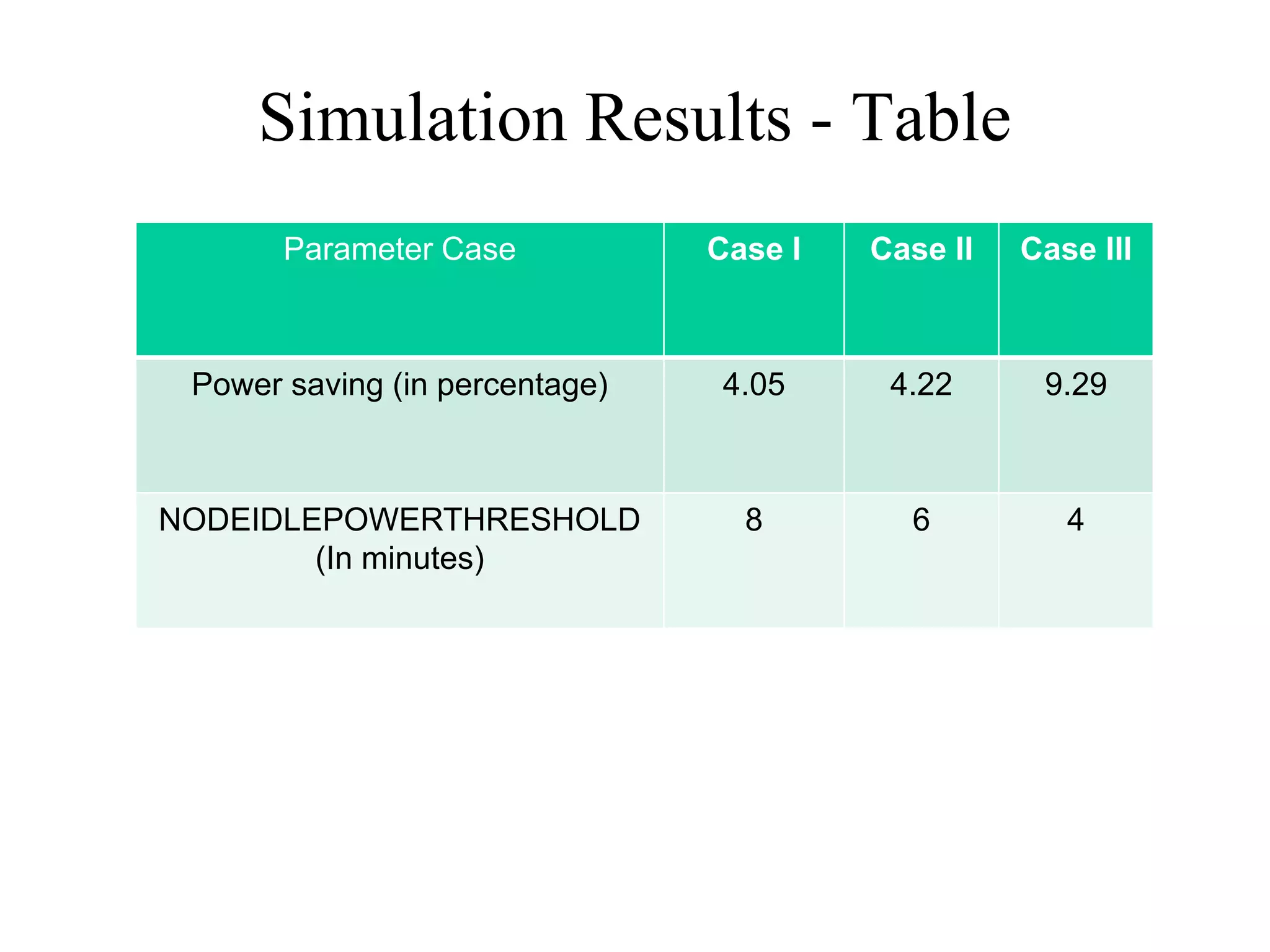

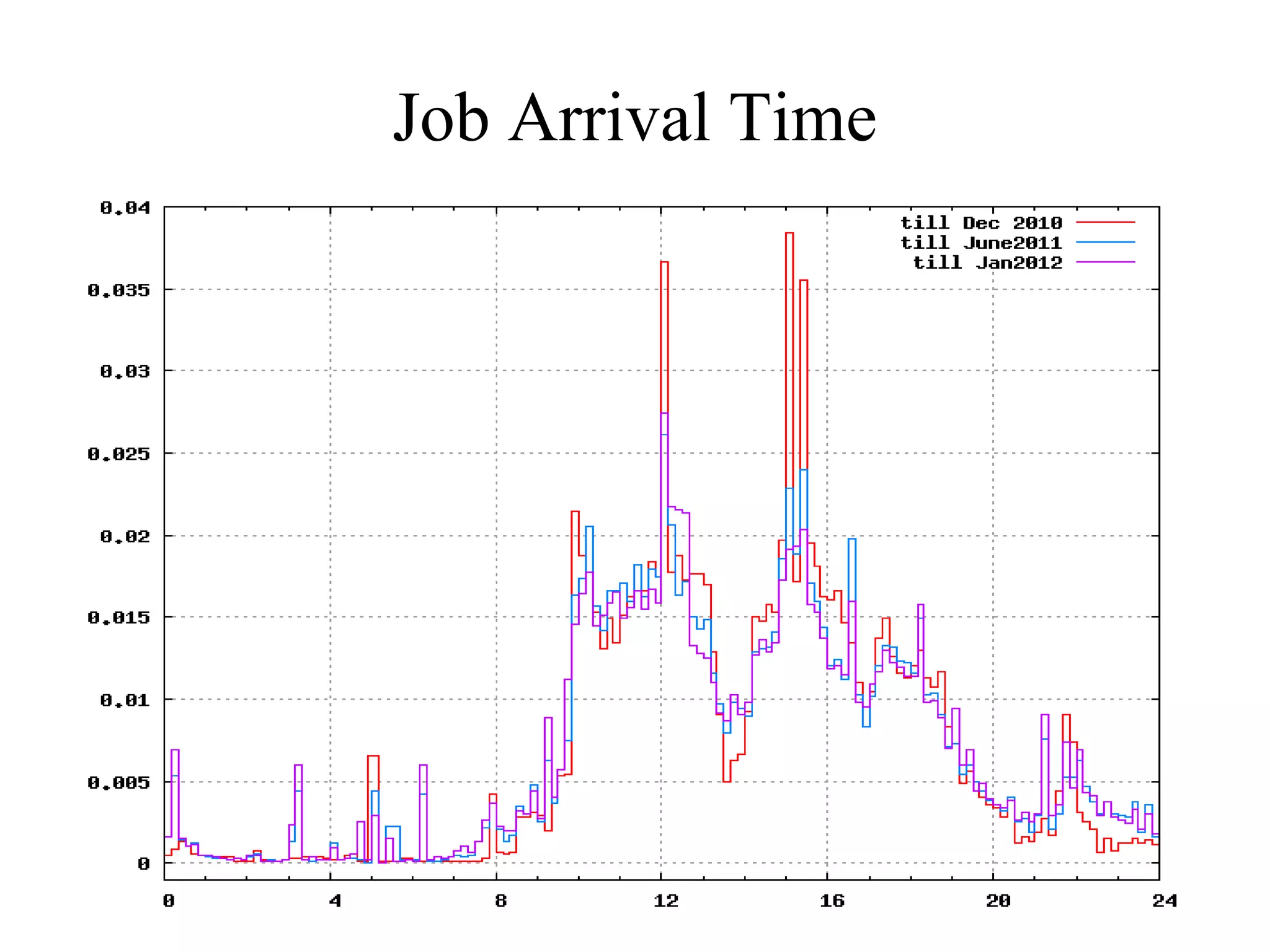



This document discusses power and energy consumption optimization techniques for high-performance computing (HPC) systems. It begins by showing graphs comparing the top 10 systems by performance on the Top500 and Green500 lists. It then discusses trends for exascale systems, including the need for higher performance per watt. The rest of the document outlines various dynamic power management techniques like dynamic voltage and frequency scaling (DVFS) and how they have been implemented on HPC systems to reduce energy usage without significantly impacting performance. It concludes by discussing NPSF's use of power optimization techniques like workload scheduling, node packing, and a feedback-driven policy engine.



















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
