Download to read offline


















The document discusses how TimescaleDB 1.5 can reduce the total cost of ownership for databases by optimizing storage through features like native compression and data tiering. It highlights the importance of efficiently managing time-series data, allowing users to store more data while maintaining performance and reducing operational costs. Additionally, it provides use cases for manual and automatic compression policies, as well as strategies for moving data to cost-effective storage as it ages.
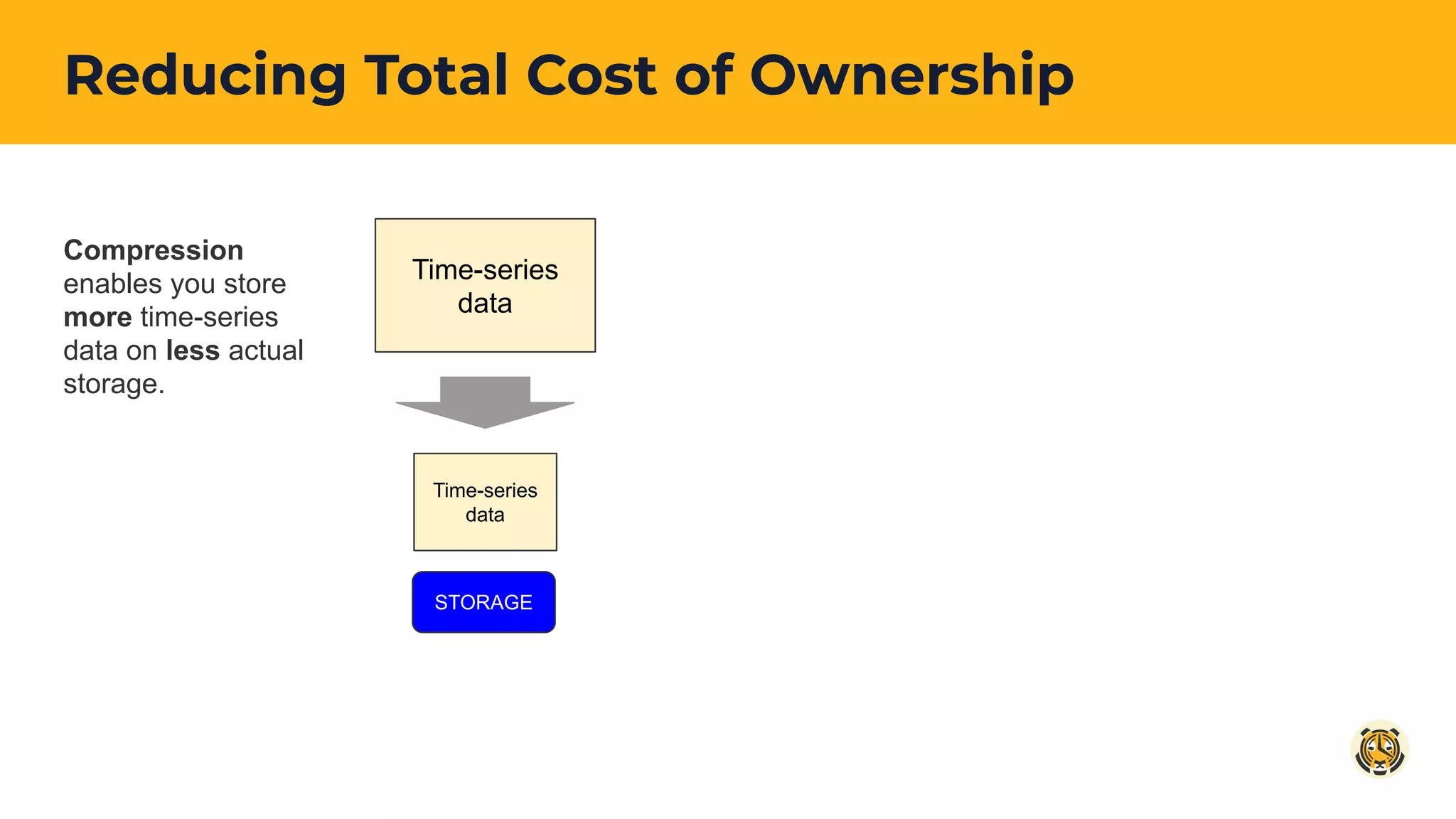
Introduction to reducing Total Cost of Ownership (TCO) using TimescaleDB features focusing on data storage and management.
Highlights new features in TimescaleDB 1.5: Native Compression for storage efficiency and Data Tiering for cost optimization.
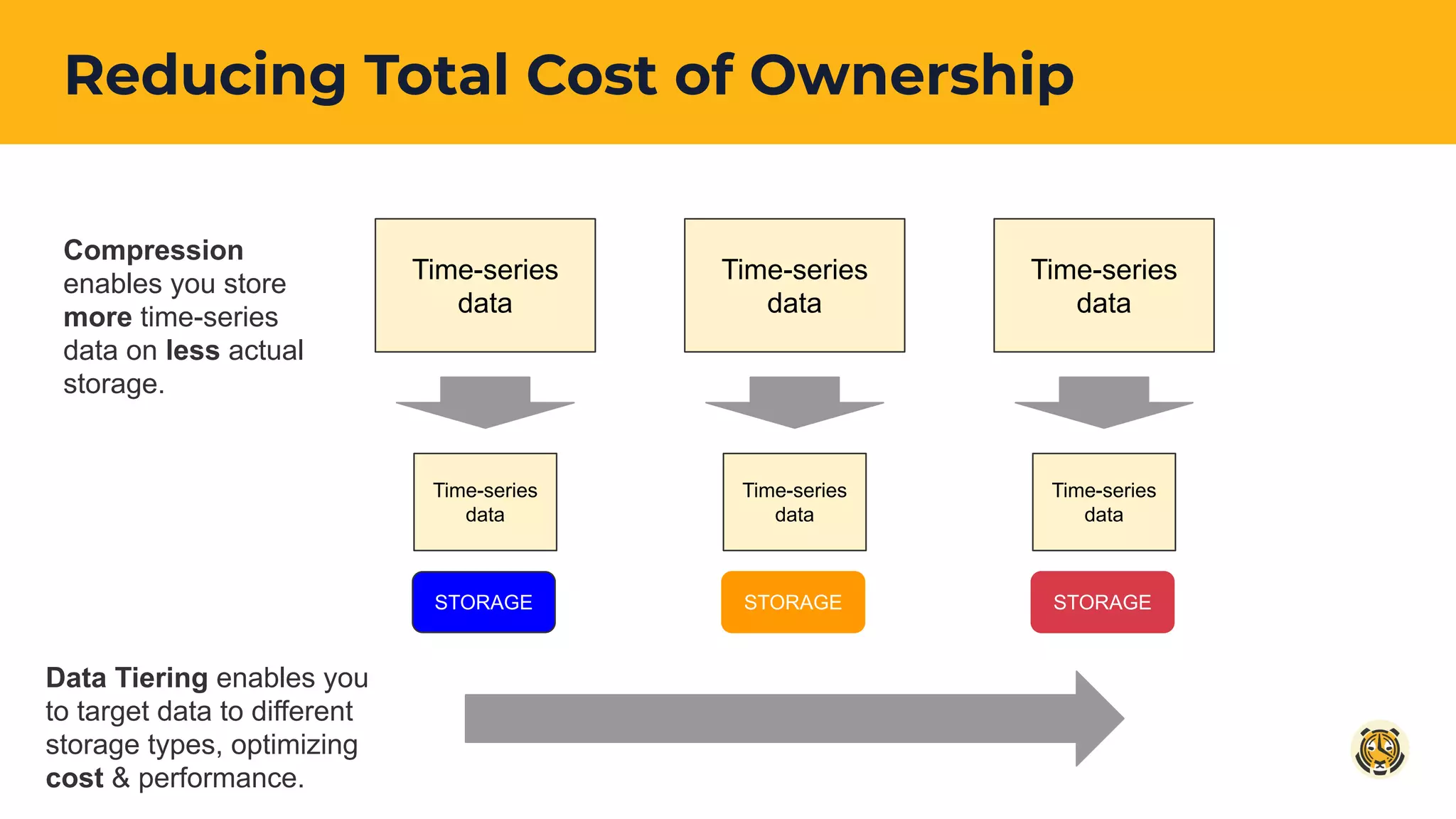
Discussion on how compression and data tiering are employed to maximize storage efficiency for time-series data.
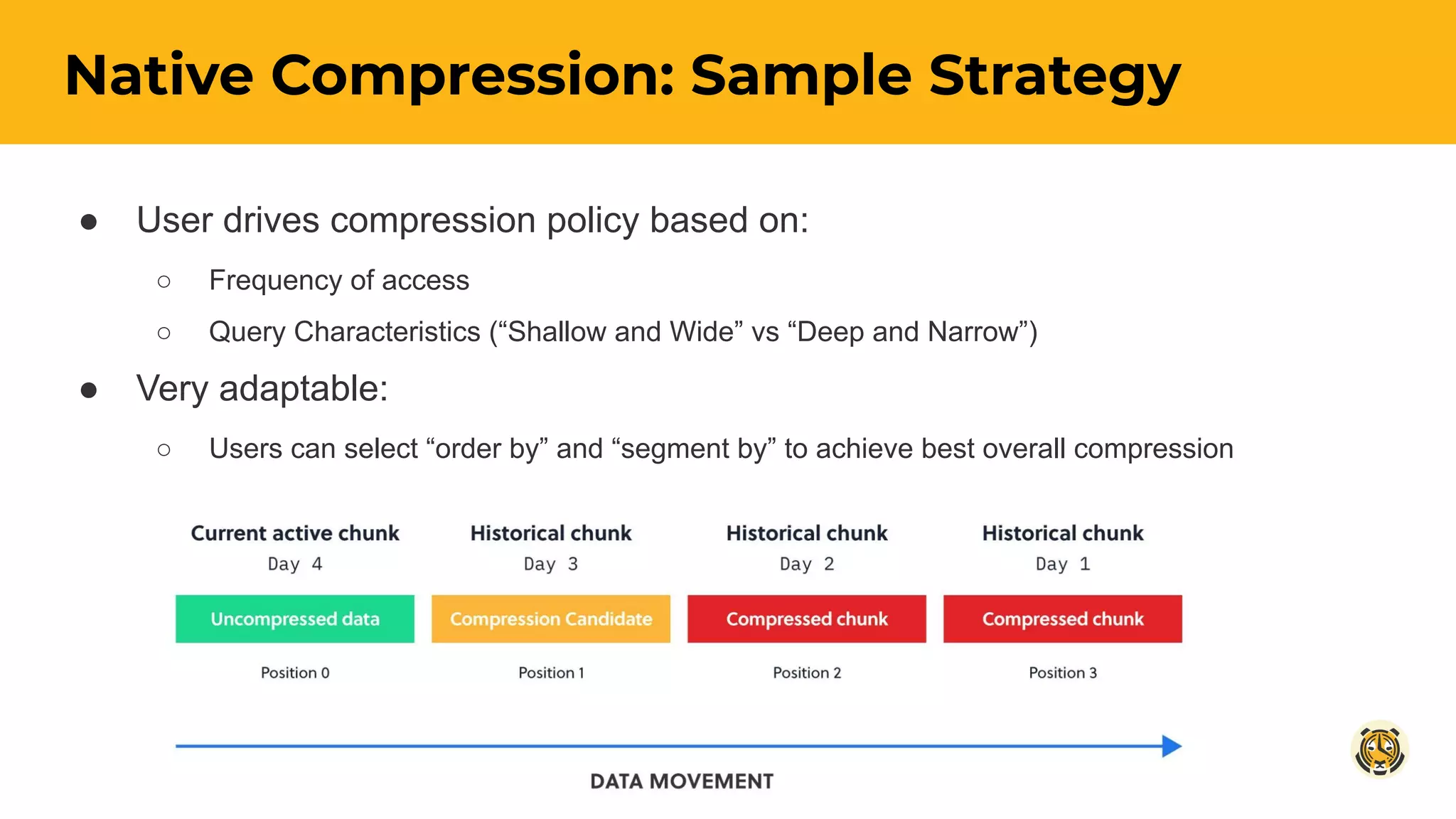
Overview of the Native Compression feature allowing users to reduce storage, driven by user-defined policies based on data access patterns.
Explanation of how data organization through 'order by' and 'segment by' enhances compressibility and performance.
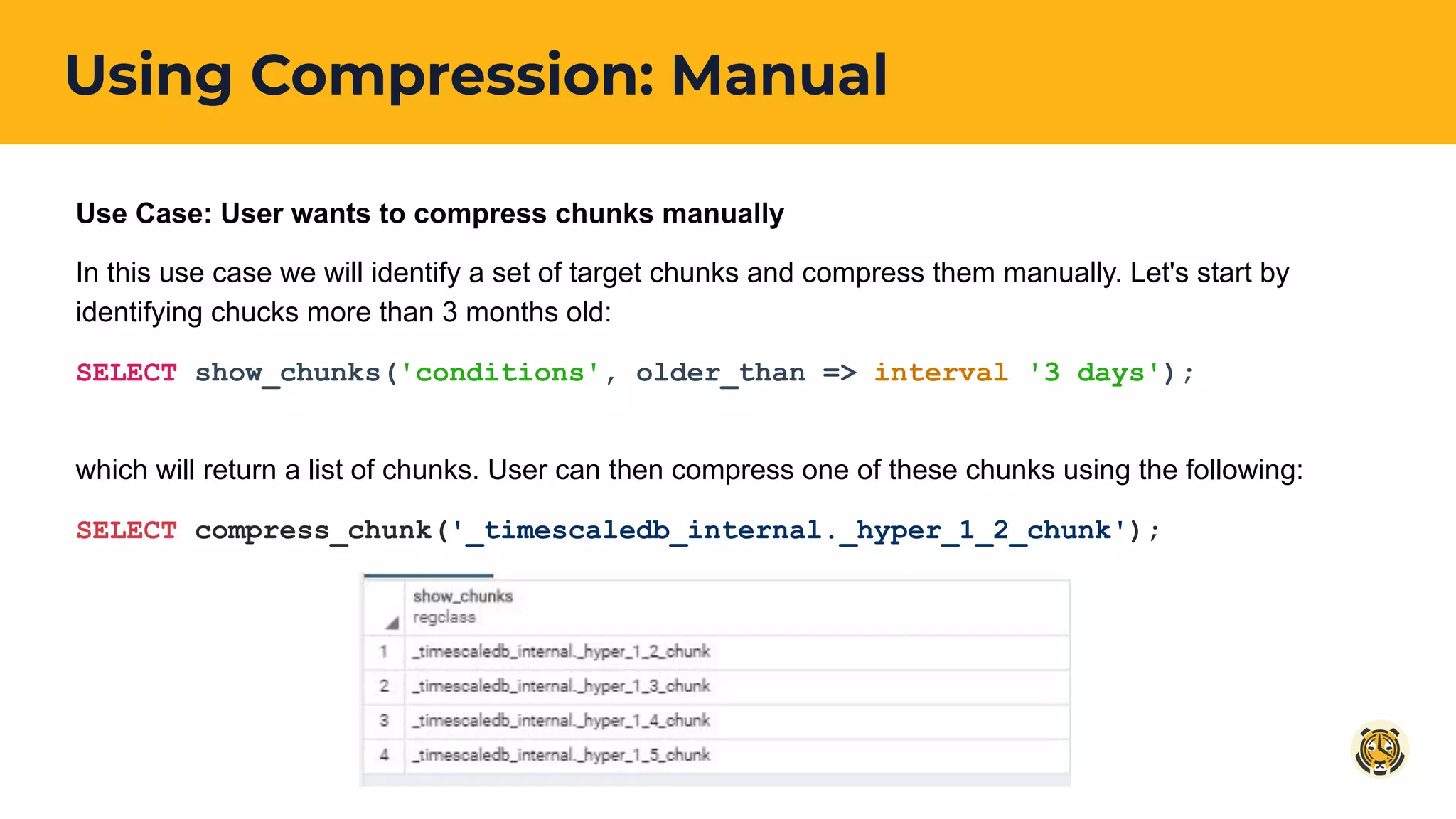
Instructions for manually compressing data chunks and automating compression based on chunk age to maintain storage efficiencies.
Introduction to Data Tiering in TimescaleDB for Enterprise Edition, emphasizing on efficient storage management by moving infrequently accessed data.
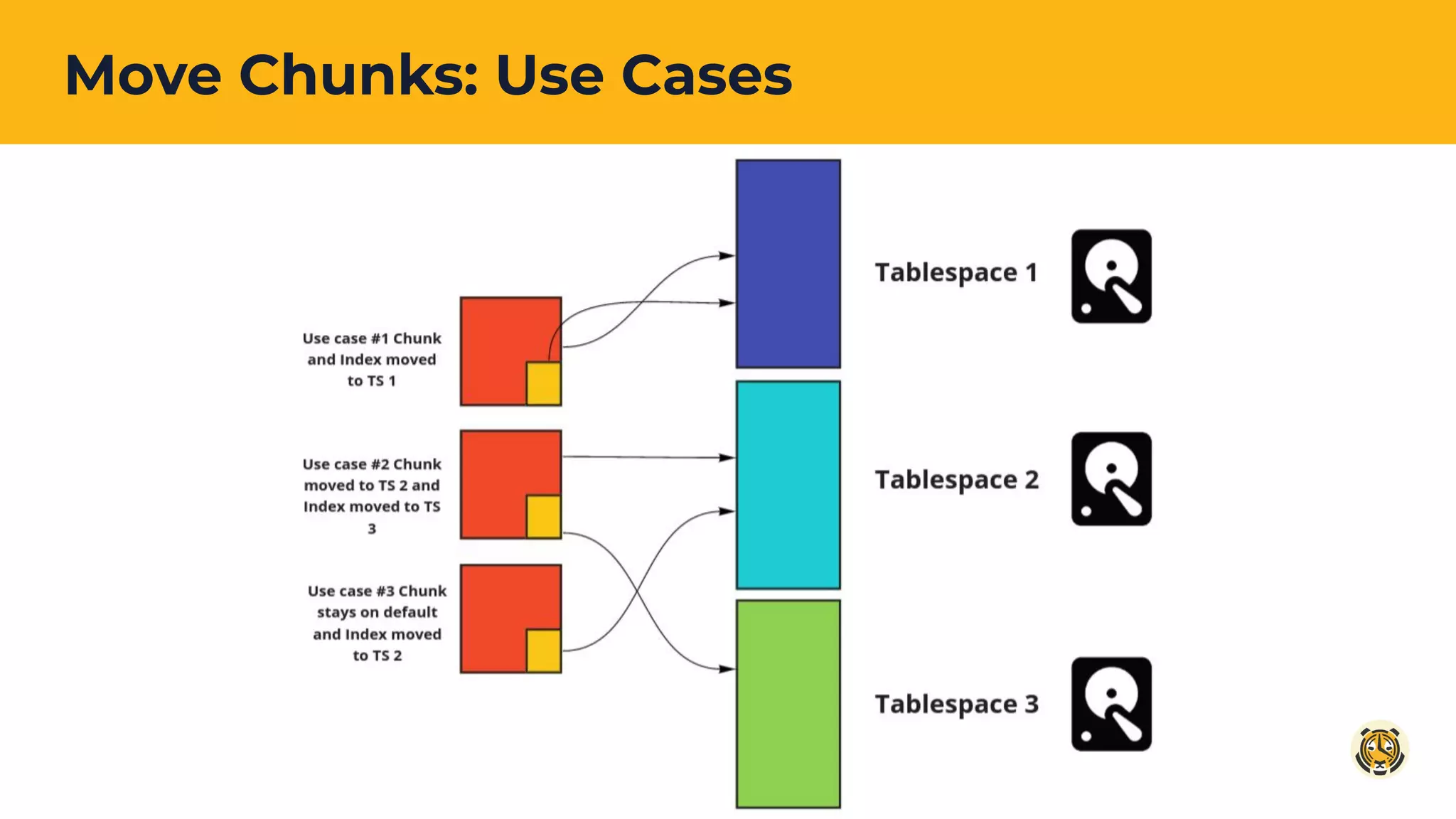
Case studies and strategies for moving chunks of data to optimize storage costs and improve operational efficiency.
Resources for further learning on TimescaleDB features and a Q&A session to engage with the community and address queries.


































































