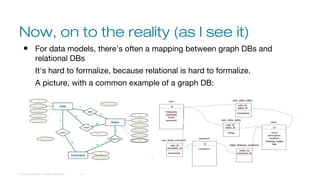
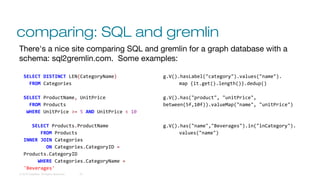
The document discusses the perspectives of Ben Krug, a technical support engineer from DataStax, on graph databases compared to traditional relational databases. It highlights the definitions, theories, and tools related to graph models, emphasizing the nuances and complexities between graph and relational database structures. The presentation also critiques common misconceptions about graph databases and discusses the mechanisms for data access, including comparisons between SQL and Gremlin.

















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)















