

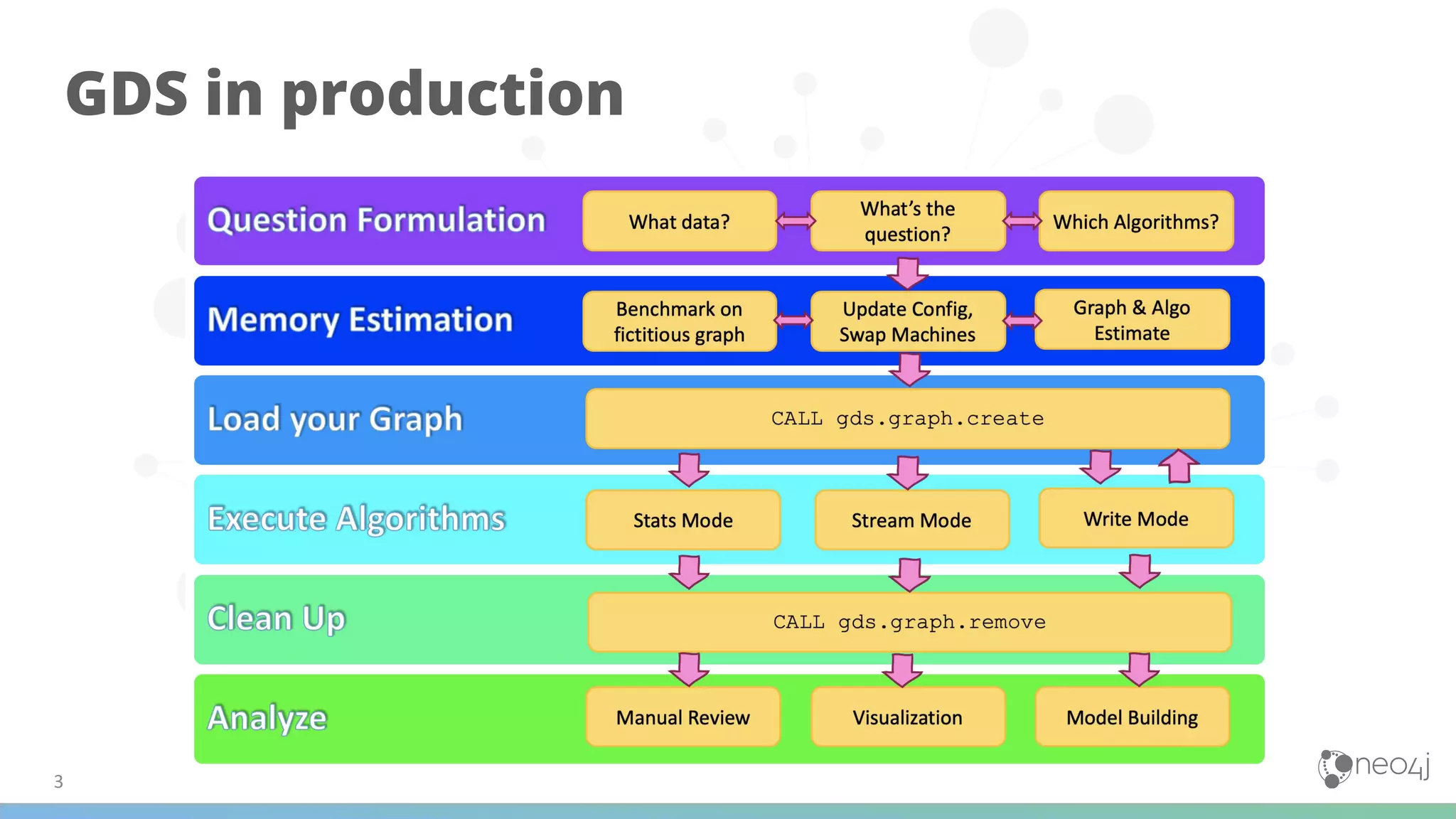
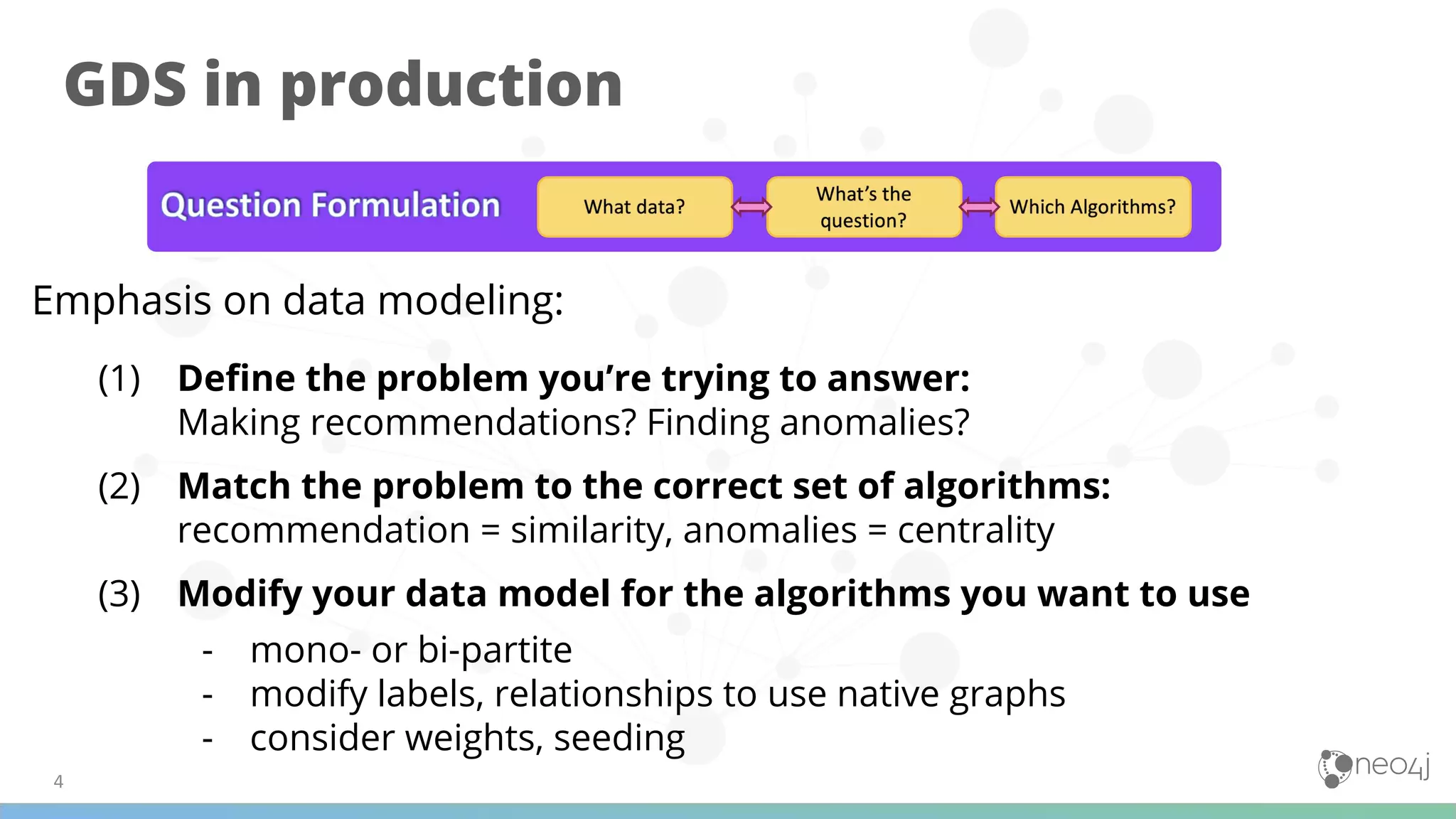




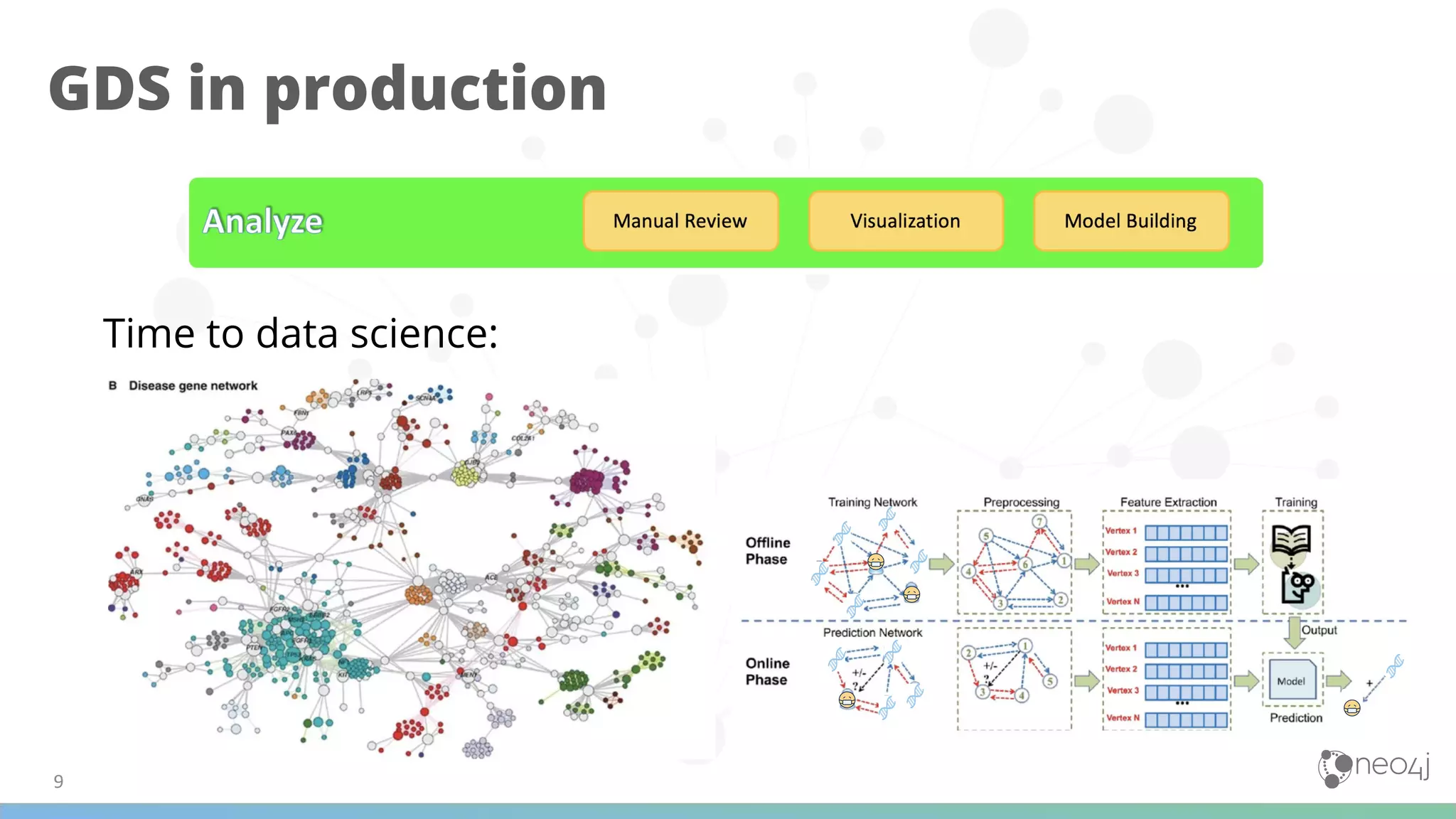





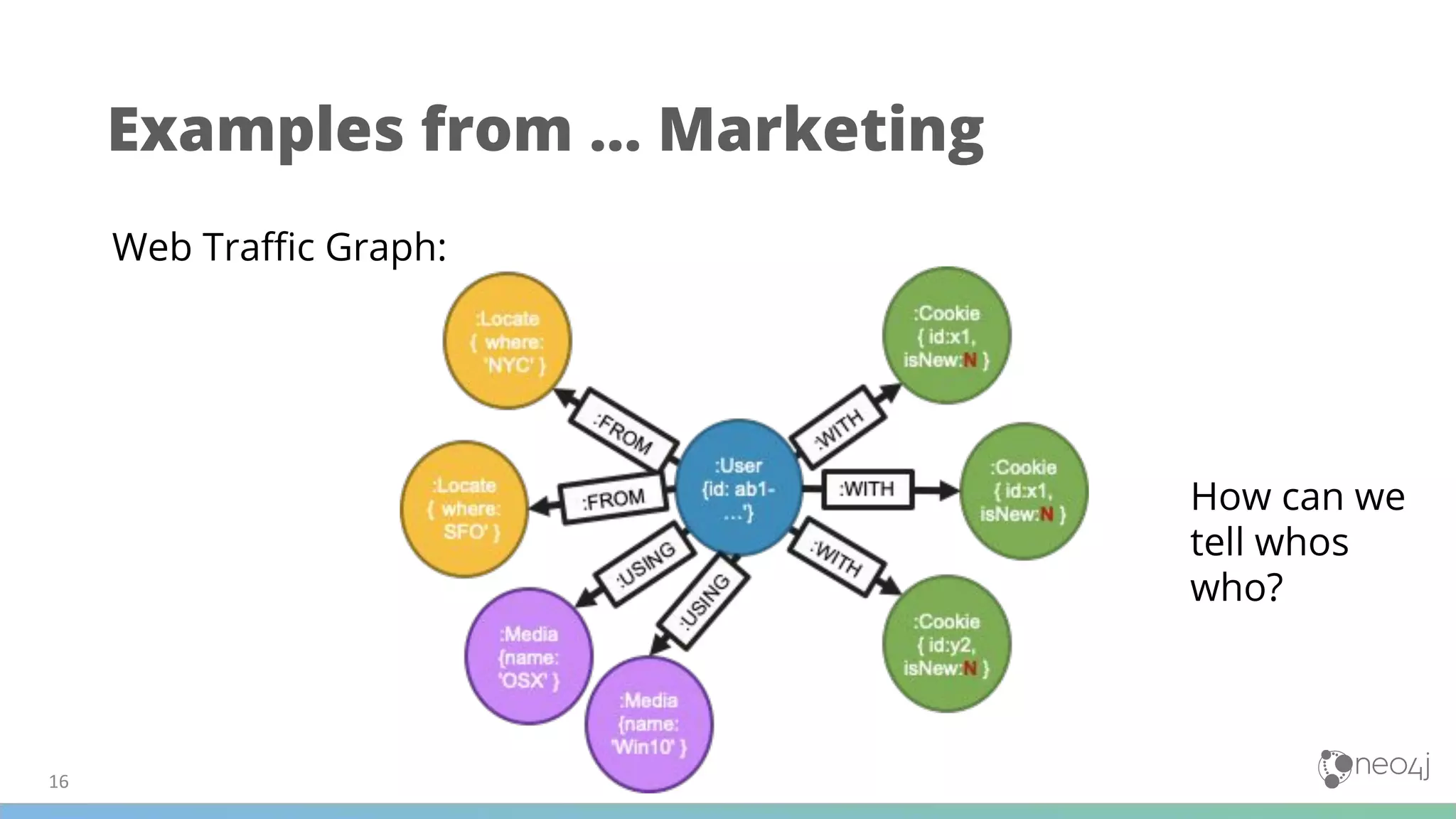

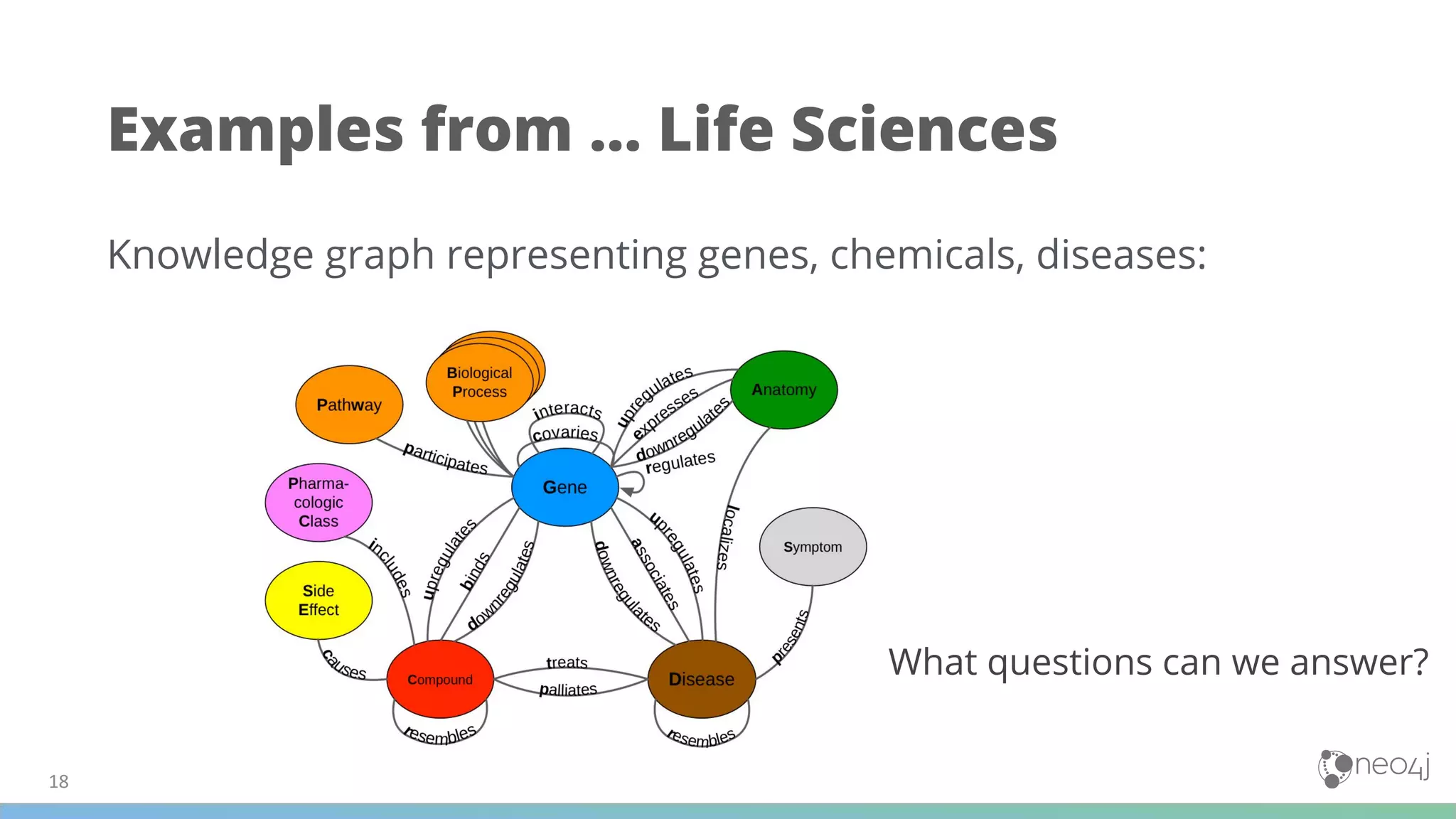




(1) The document discusses best practices for using Graph Data Science (GDS) in production, including data modeling, configuration, loading analytics graphs, running algorithms, and combining algorithms. (2) It emphasizes defining the problem, matching algorithms to problems, and modifying the data model for algorithms. Examples of algorithm combinations given are community detection with node similarity or centrality. (3) The document also provides examples of using GDS for applications like recommendations, fraud detection, disambiguation, and analyzing transactional and marketing graphs, as well as examples for life sciences applications.

















































































