

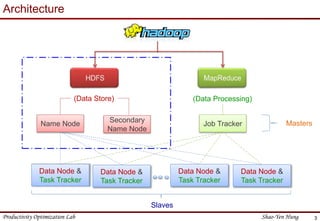
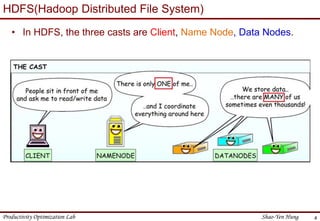
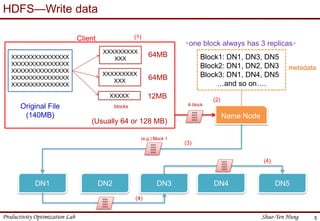
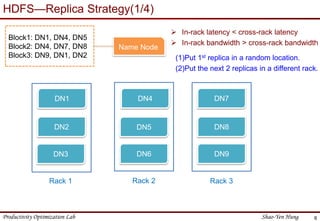




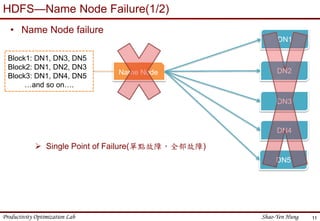
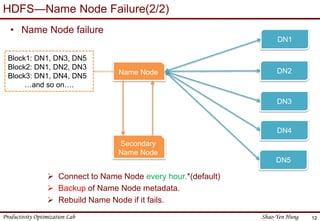
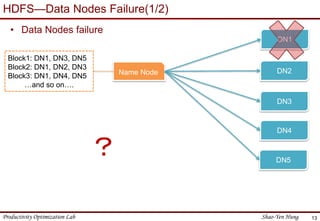

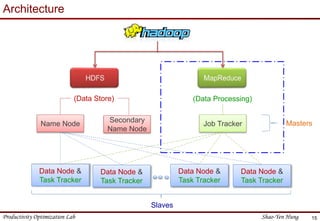
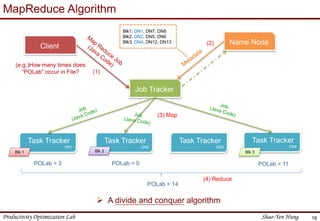
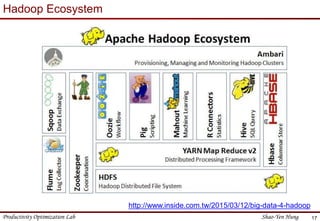


This document provides an introduction to Hadoop. It describes that Hadoop was created by Doug Cutting in 2006 at Yahoo to address large datasets. It discusses the key components of Hadoop including HDFS for storage and MapReduce for processing. HDFS uses a master/slave architecture with a NameNode and DataNodes to store and replicate blocks of data across nodes. MapReduce allows distributed processing of data across clusters using a map and reduce function. The document outlines the architecture and functions of core Hadoop components like HDFS and MapReduce.















![Lecture 9 [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture9compatibilitymode-151031084755-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
























































