




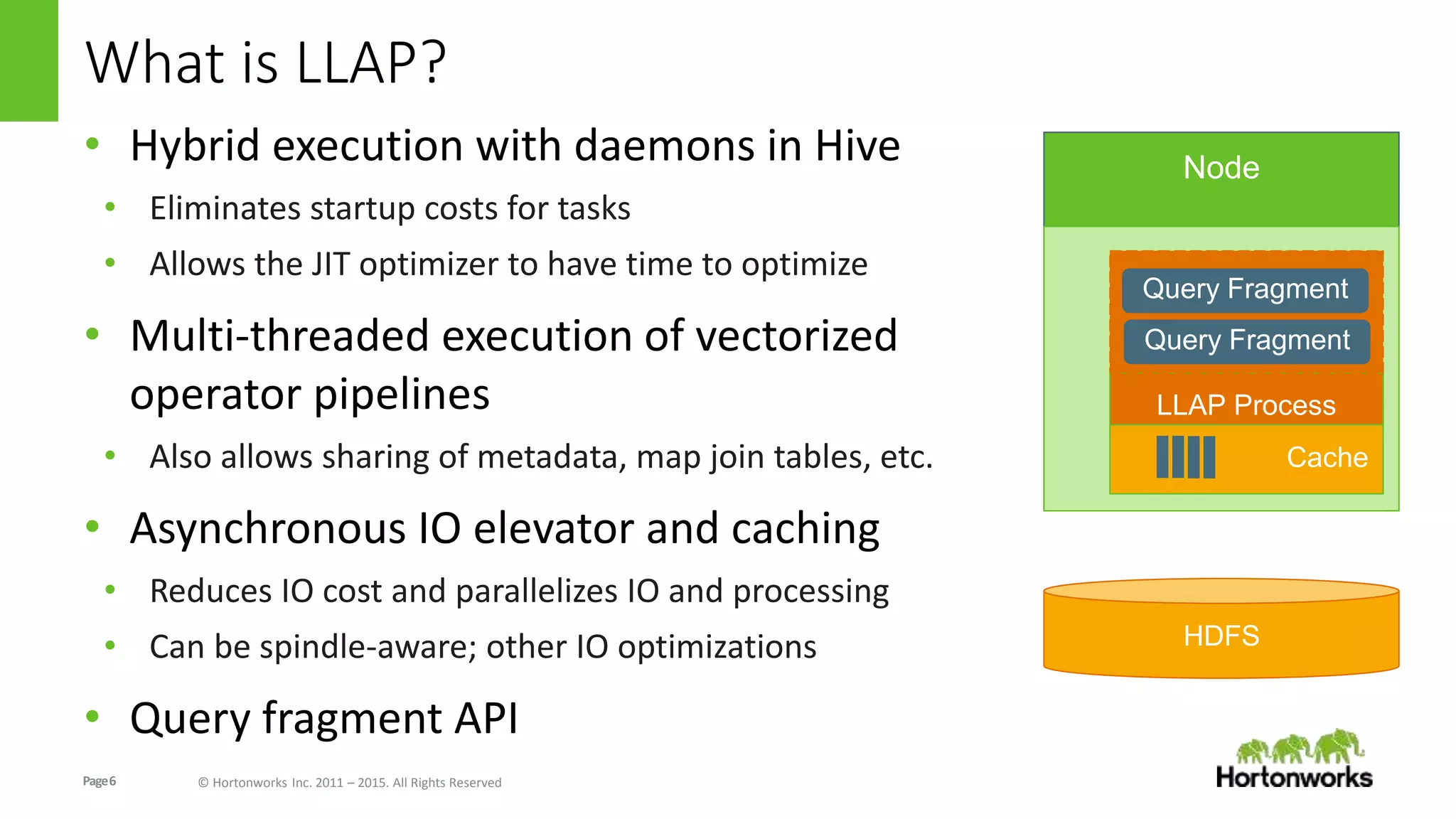

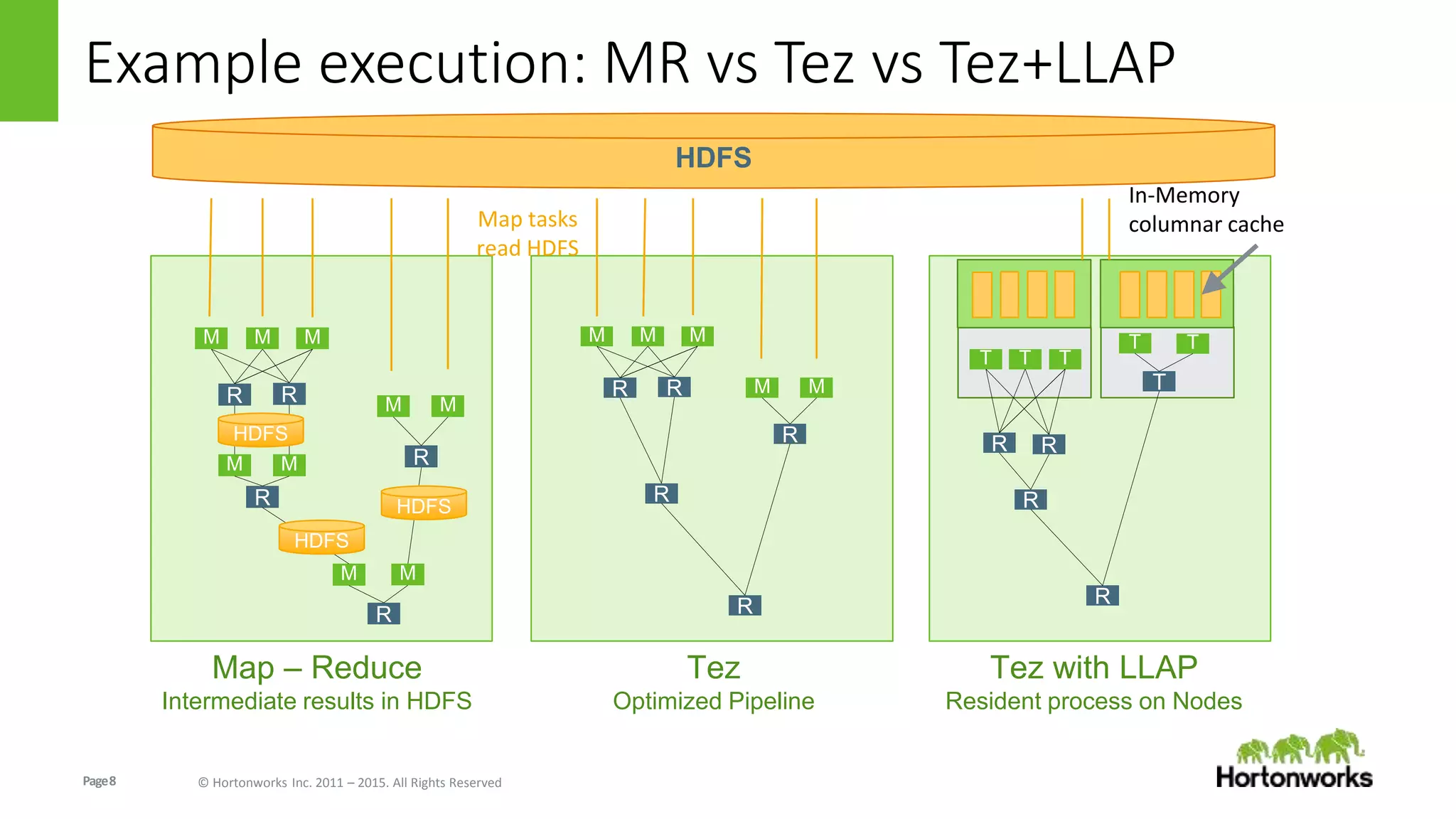











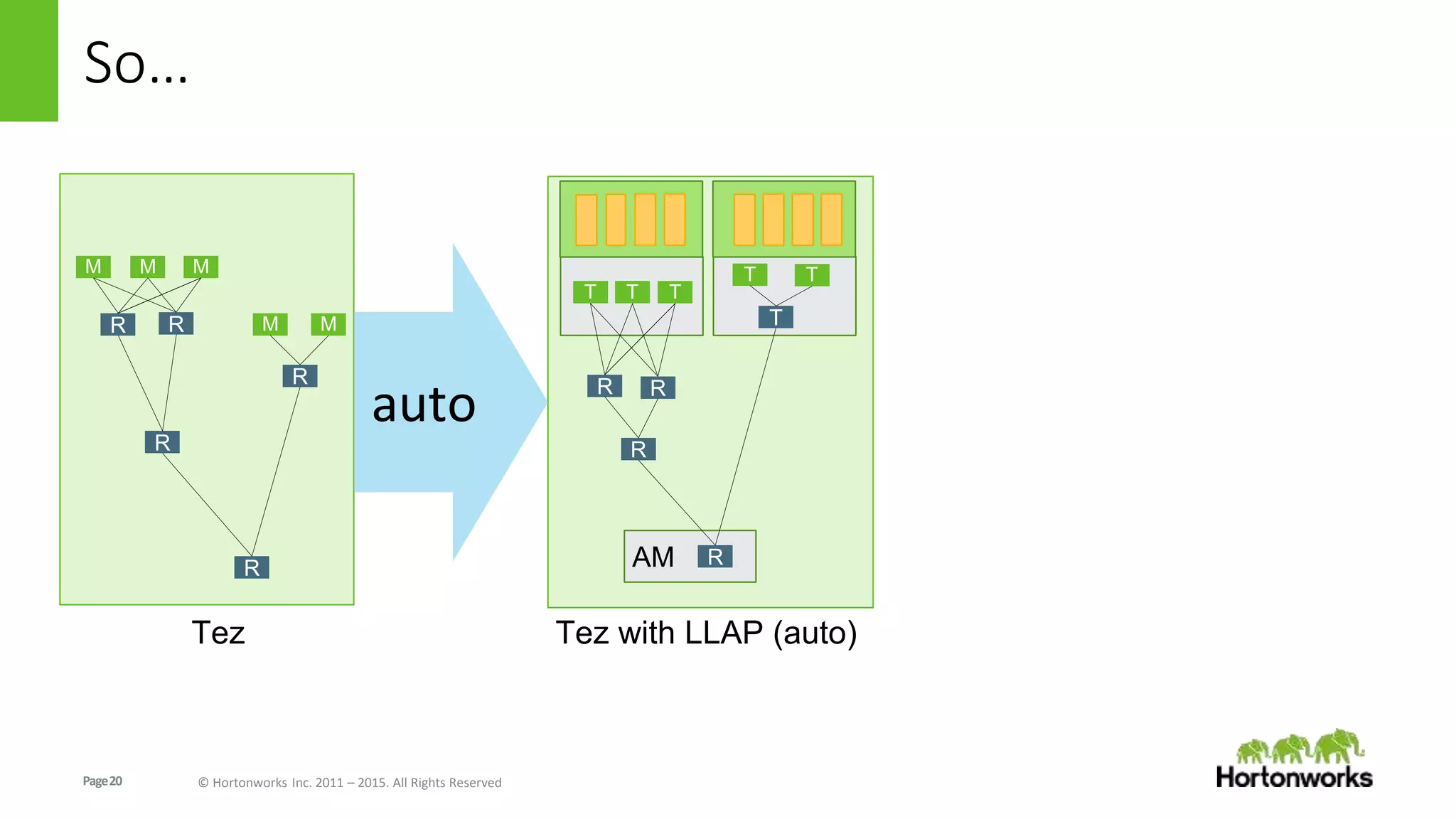
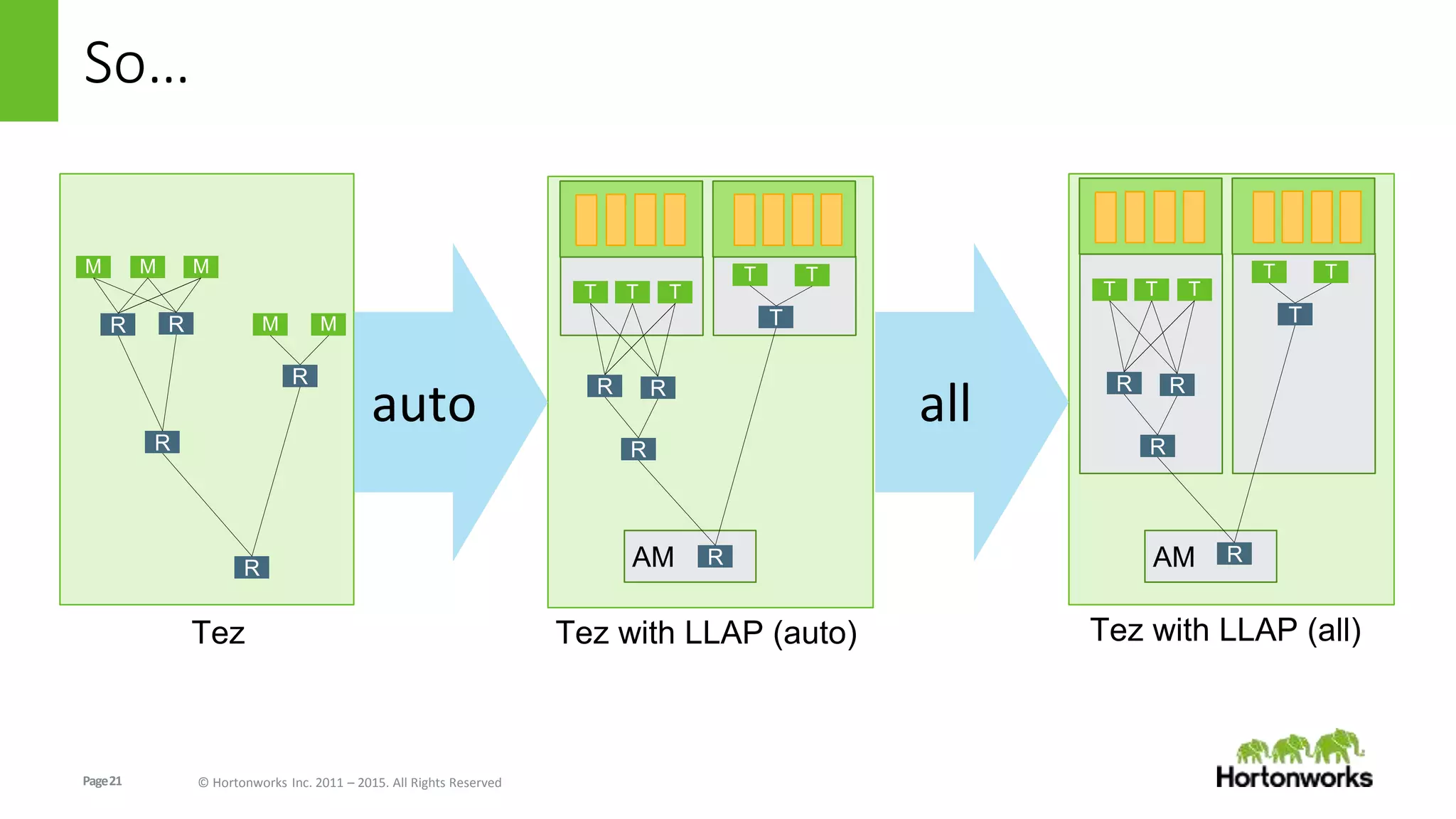


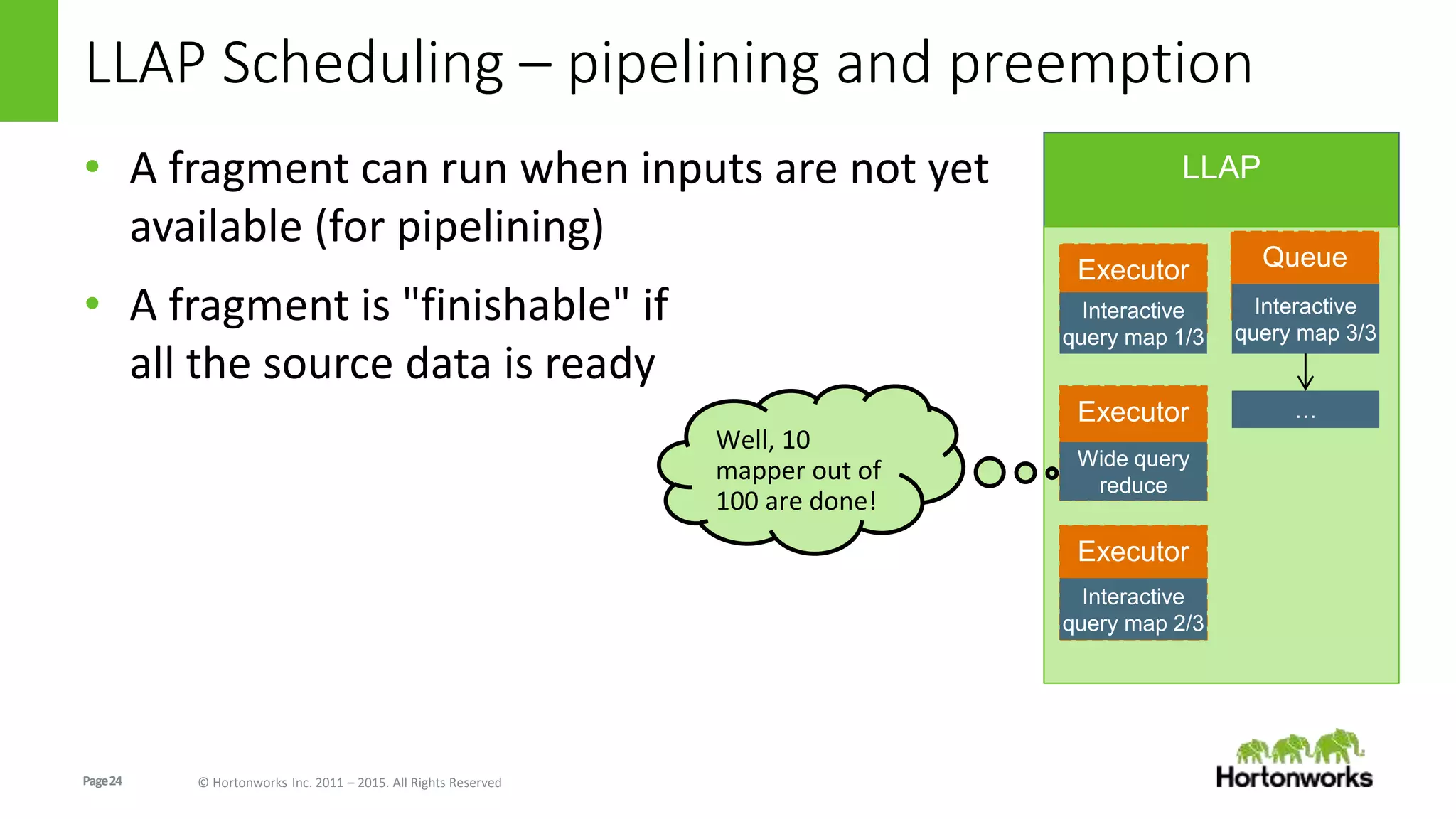




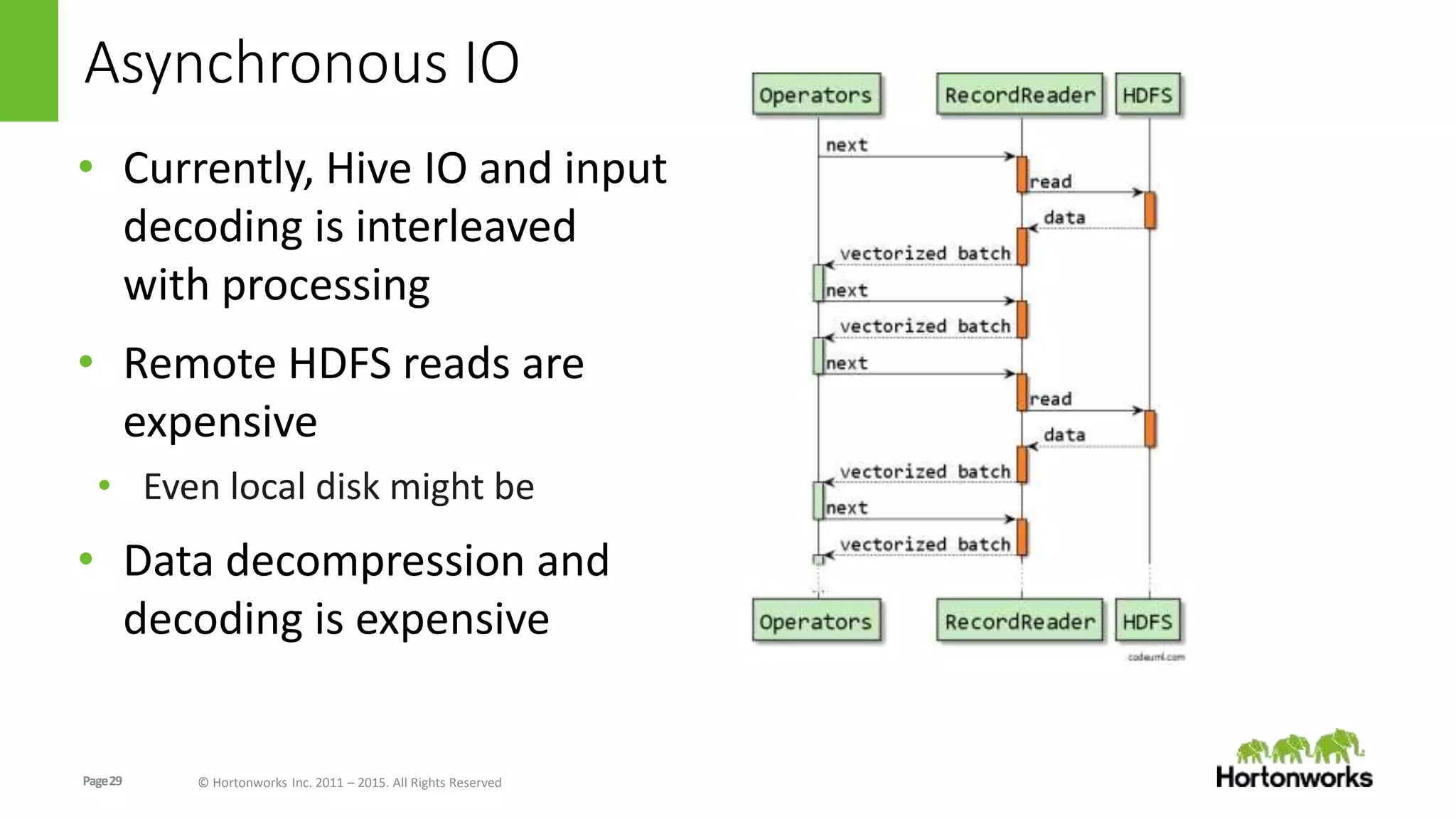
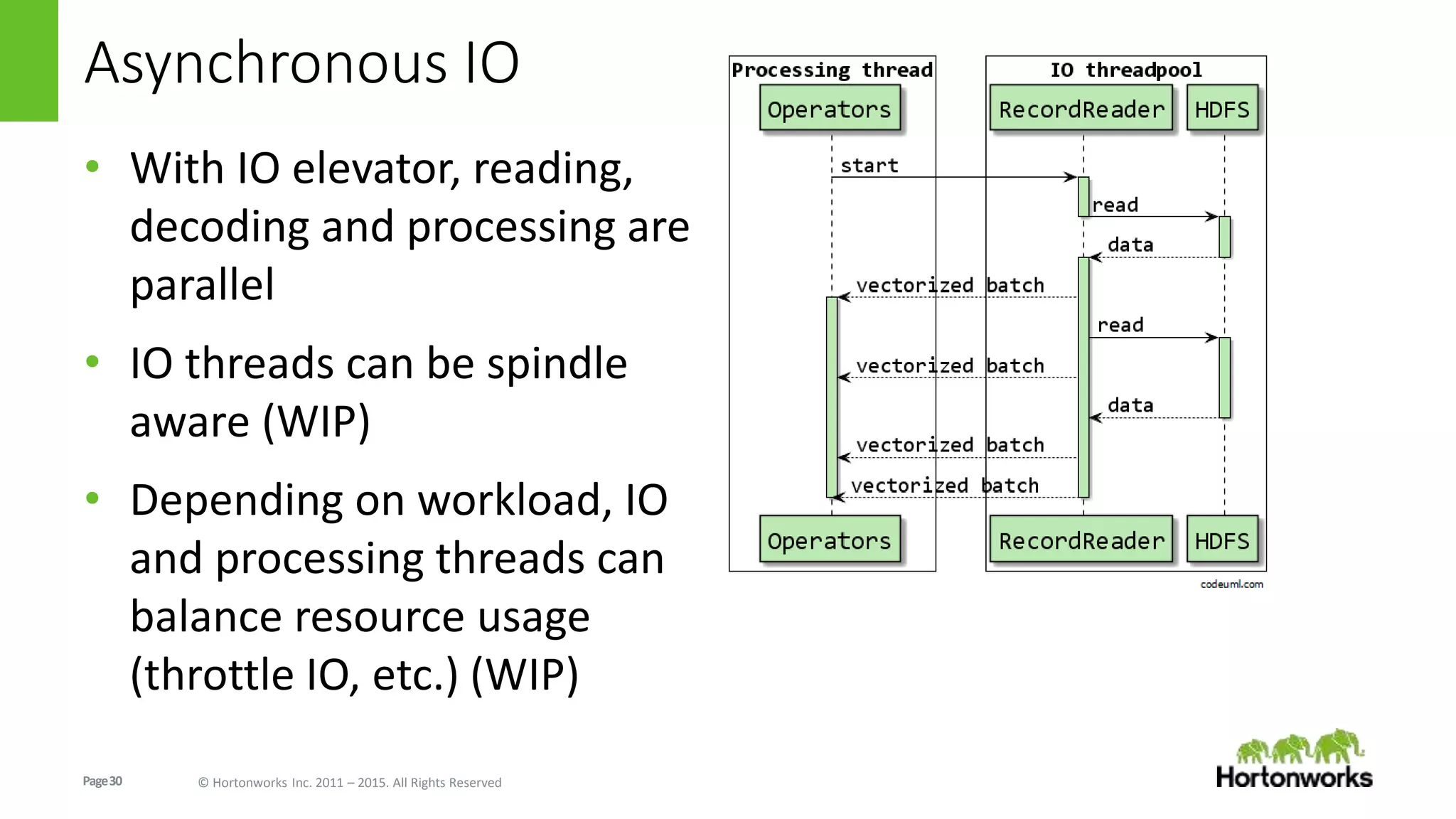






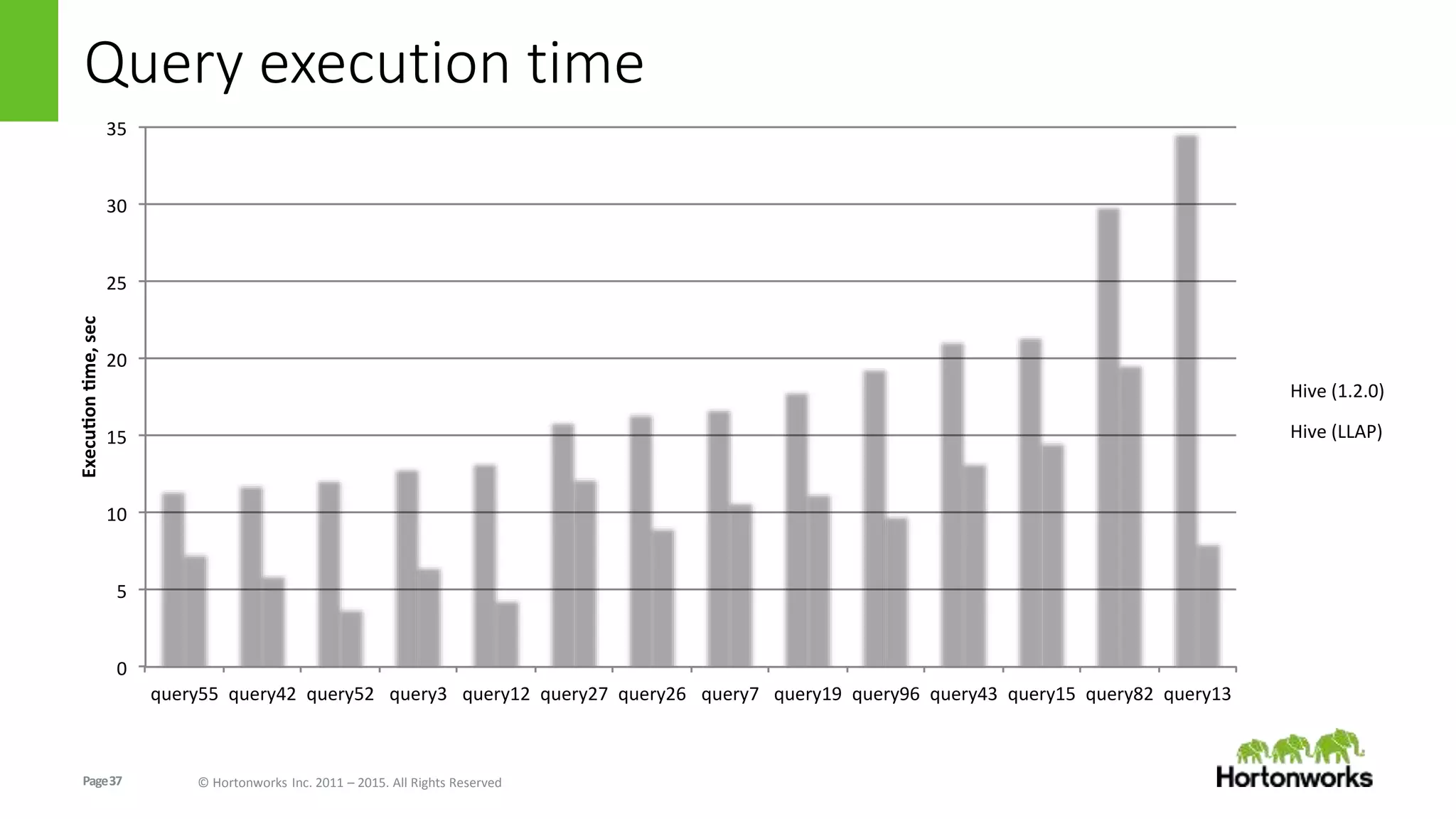
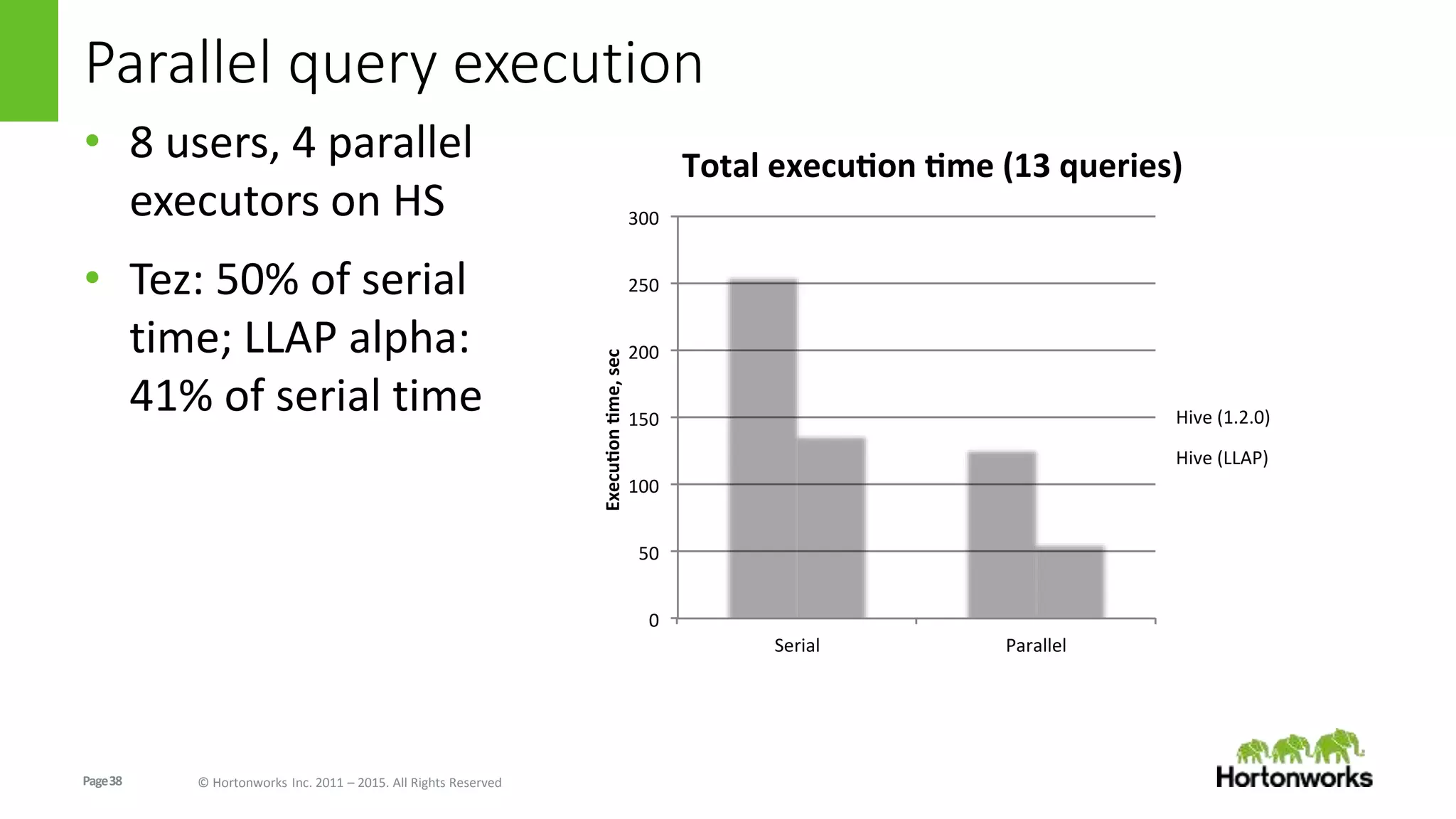






The document discusses Long-Lived Application Process (LLAP), a new capability in Apache Hive that enables long-lived daemon processes to improve query performance. LLAP eliminates Hive query startup costs by keeping query execution engines alive between queries. It allows queries to leverage just-in-time optimization and data caching to enable interactive query performance directly on HDFS data. LLAP utilizes asynchronous I/O, in-memory caching, and a query fragment API to optimize query processing. It integrates with Apache Tez to coordinate query execution across long-lived daemon processes and traditional YARN containers.







































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














