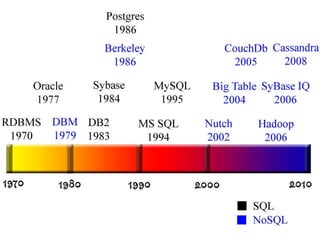
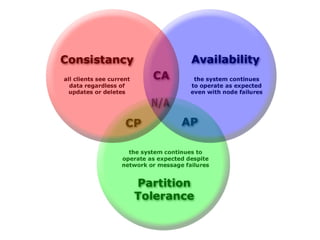
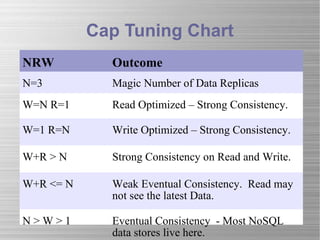
- The document discusses NoSQL databases and compares them to traditional SQL databases. It provides an overview of different types of NoSQL databases like column-oriented stores, document stores, memory stores, and graph databases. Examples of popular NoSQL databases are also given for each category.






























![Case Study - Riak Data Model – Bucket/Key/Value Value has MIME type, byte[] Value supports one-way Links, basic graph Erlang, Protocol Buffers, REST interfaces Pre/Post Commit Hooks CAP Tunable per bucket Map/Reduce – Erlang and Javascript](https://image.slidesharecdn.com/nosqllandscapenosqltips-110728001432-phpapp02/85/No-sql-landscape_nosqltips-33-320.jpg)










































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
