Downloaded 30 times



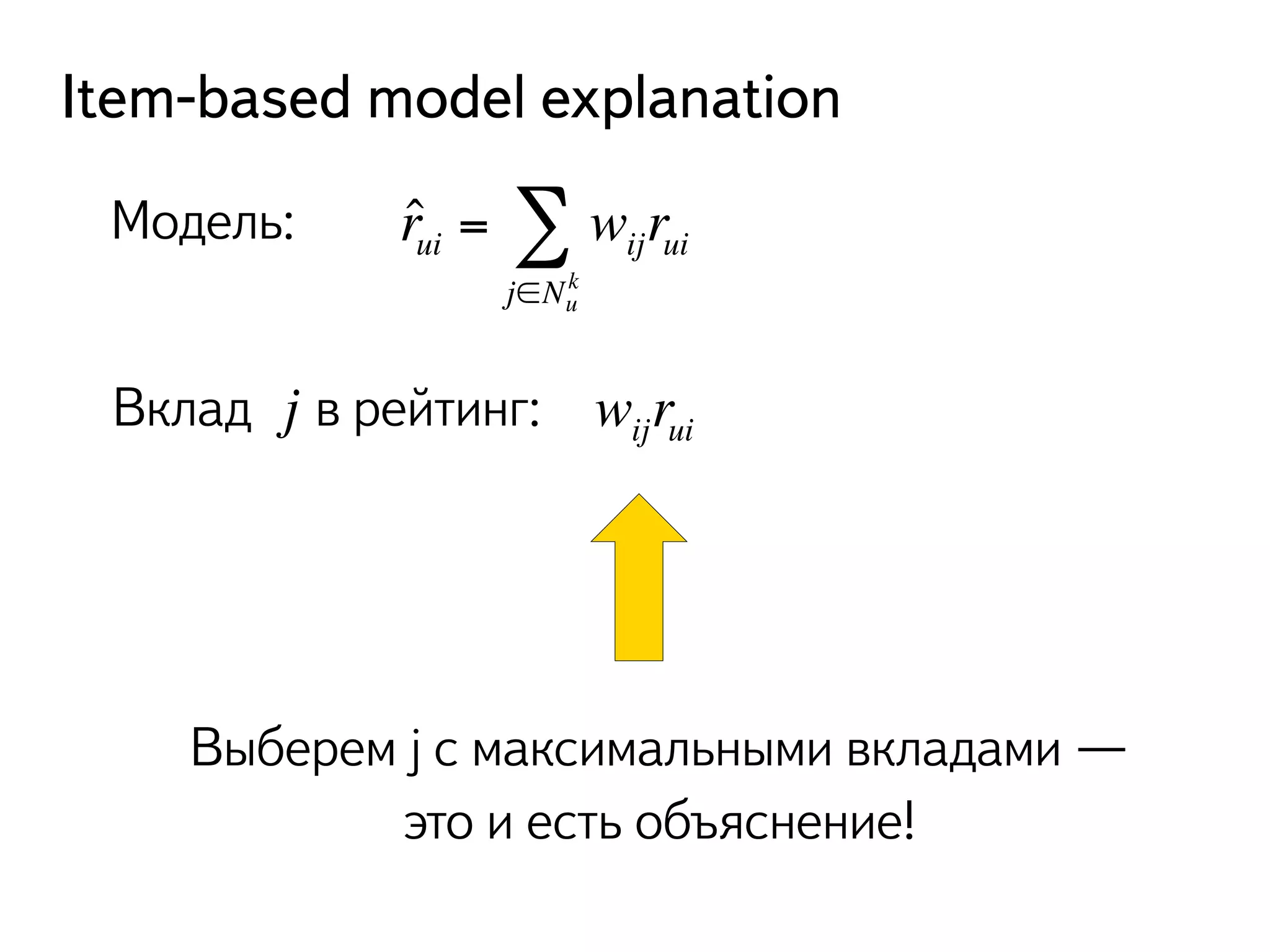




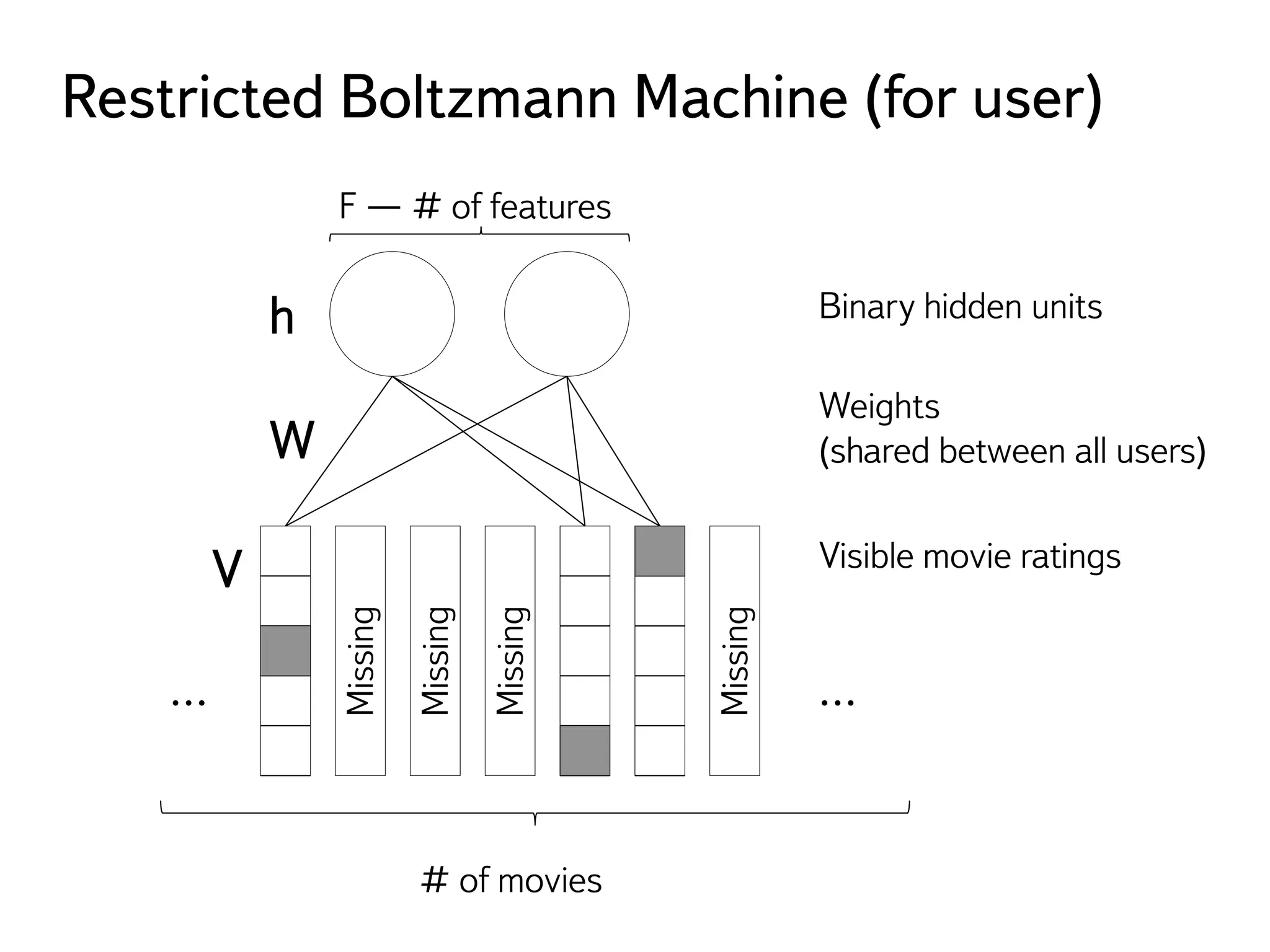

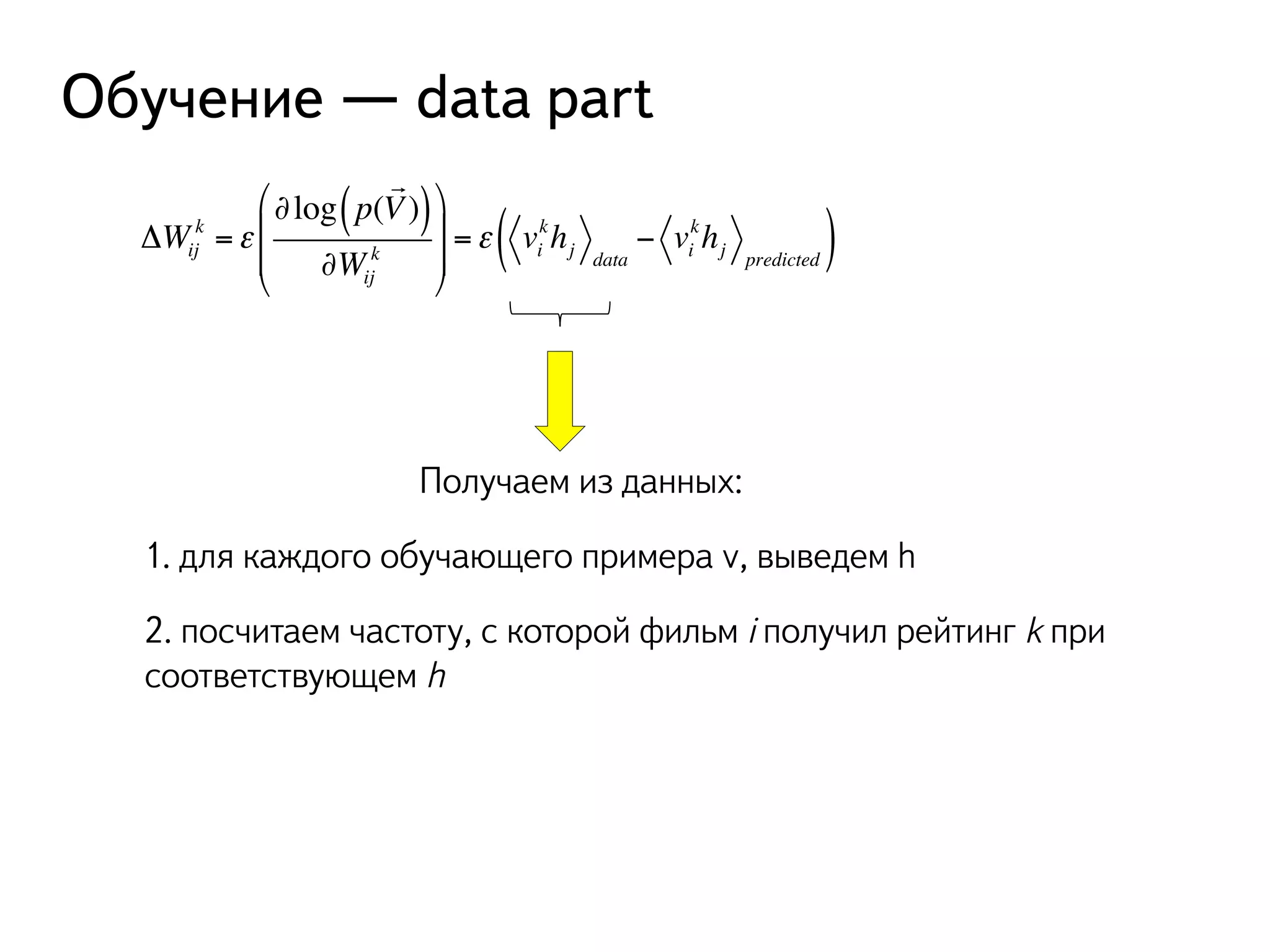
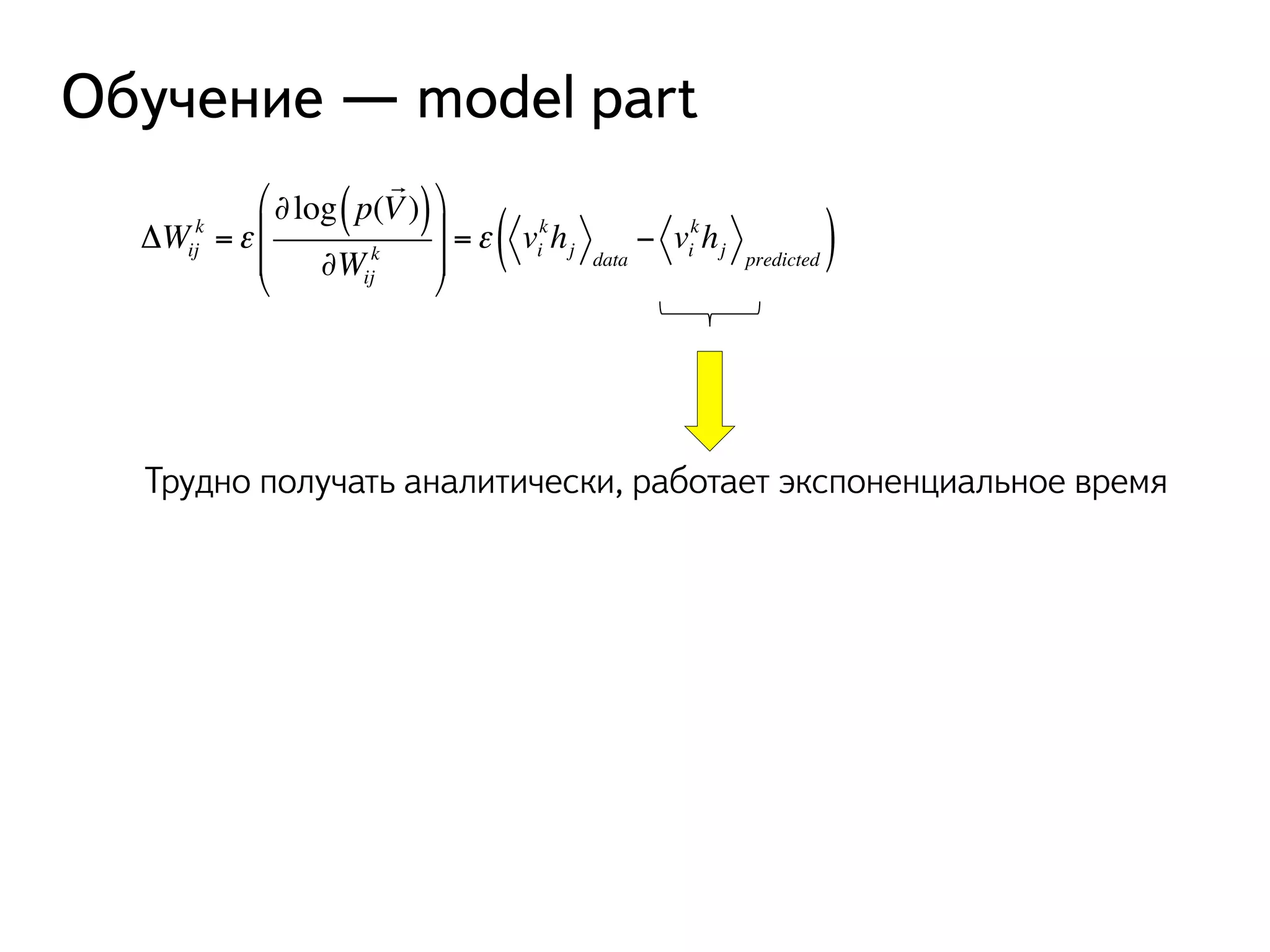






![Что делать с вероятностями?
Два варианта:
1. просто взять оценку, у которой вероятность максимальна
2. нормализовать вероятности так, чтобы
p(vi = k)
KΣ
k=1
=1
и посчитать предсказание как E vi [ ]](https://image.slidesharecdn.com/itmo-autumn-2014-part2-141117151726-conversion-gate02/75/Machine-Learning-2-20-2048.jpg)





















Лекция Андрея Данильченко о рекомендательных системах охватывает объяснение моделей рекомендаций, включая подходы item-based и ALS, а также использование глубинных моделей, таких как Restricted Boltzmann Machines и Gaussian Hidden Units. Документ подробно излагает методы предсказания рейтингов и метрики оценки качества рекомендаций, включая RMSE и MAP. Лекция также включает практические рекомендации по оптимизации алгоритмов ранжирования.



































































