This document is an outline for a presentation on advanced topics in computer science focusing on big data and Hadoop. It introduces big data and Hadoop, describing Hadoop's features like HDFS and MapReduce. It discusses how companies use big data and Hadoop, components of the Hadoop framework, and compares distributed and parallel file systems. The document also covers YARN, shortcomings of Hadoop, and its future directions.




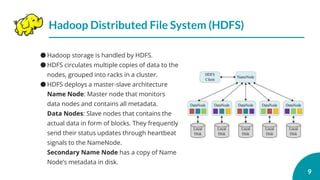
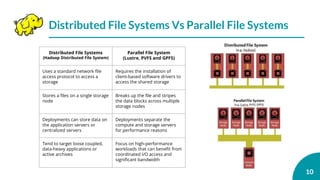
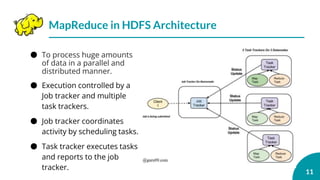
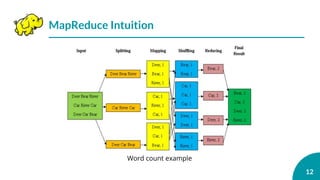






















![[C33] 24時間365日「本当に」止まらないデータベースシステムの導入 ~AlwaysOn+Qシステムで完全無停止運用~ by Nobuyuki Sa...](https://cdn.slidesharecdn.com/ss_thumbnails/c33sqlserversasaki-131128193643-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)

