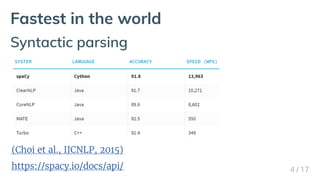
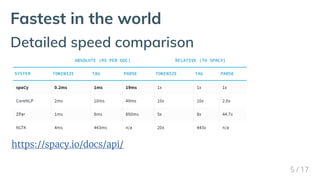
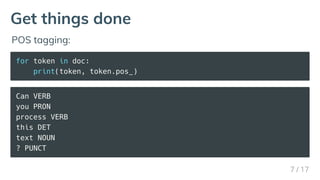
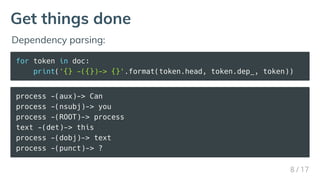
Download as PDF, PPTX










![うちの研究室的に便利そうな機能
textacy.extract.pos_regex_matches
from textacy.extract import pos_regex_matches
from textacy.constants import POS_REGEX_PATTERNS
list(pos_regex_matches(nlp('Can you process this text?'),
POS_REGEX_PATTERNS['en']['NP']))
[this text]
16 / 17](https://image.slidesharecdn.com/newpresentation2017-10-181842561-171019010753/85/Introduction-to-spaCy-16-320.jpg)


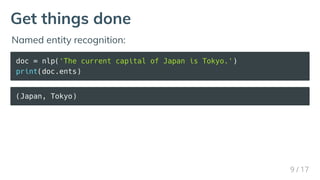
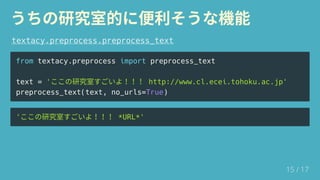
This document introduces spaCy, an open-source library for advanced natural language processing. It describes spaCy as the fastest NLP library in the world, with a simple API and ability to integrate with deep learning frameworks. It provides examples of how to quickly install spaCy and use it to perform part-of-speech tagging, dependency parsing, and named entity recognition on sample text. It also introduces textacy, a library built on spaCy that enables higher-level NLP tasks and text analysis.


































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












