Hadoop intro
•
1 like•517 views

This document provides an introduction to Hadoop and big data concepts. It explains that Hadoop is a framework for processing large amounts of data across commodity hardware in a massively parallel fashion. Key terms related to Hadoop like MapReduce, HDFS, Hive, and Pig are defined. The document also notes what Hadoop is not good for, such as low latency queries or small datasets. Finally, it provides a high-level overview of HDFS, Cloudera, and Hive to demonstrate some of Hadoop's technologies.
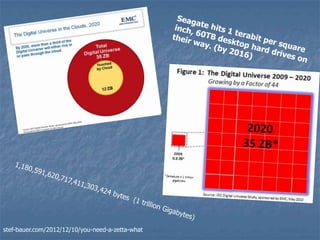

Recommended
More Related Content
What's hot
What's hot (18)
Viewers also liked
Viewers also liked (20)
Similar to Hadoop intro
Similar to Hadoop intro (20)
Recently uploaded
Recently uploaded (20)
Hadoop intro
- 2. “Big Data” Hadoop Introduction Stefan Bauer
- 3. A little about me… Data Warehouse Administrator Architect (logical/physical) DBA (monitoring, space management, etc) SSIS Developer (build it… run it… support it) SSAS/SSRS (performance tuning, supporting) Performance monitoring (is it all working?) I am a geek (Some people have pointed that out about me… judge for yourself)
- 4. What we will cover Why do you care (or at least why you should)? General overview Basic terms (get us on the same page) A Look at some of the technology (aka demo) All of the technical parts are in a multi-part series on my Blog
- 5. What kind of data do sort through? Interesting technology… might not be for you You have big data… Getting there… might and you know it! be something interesting to start working out the details…
- 6. What is that Hadoop thing I keep hearing about? A Framework (collection of technologies) Complex processing Massively parallel Large amounts of data Commodity hardware
- 7. Hadoop … what is it not Ad hoc analytics Low latency between data arrival, analysis, and query usage “fast” (speed is a relative thing) Facebook has interactive queries on Hadoop framework Good for small data
- 8. Terms Cloud Cluster Hadoop Hadoop Distributed File System (HDFS) Hue (Web Interface for Mapreduce/Oozie) Mapreduce Job Tracker Task Trackers (on Data Nodes) Oozie (Workflow Management)
- 9. Terms Pig (Distributed Transformation Scripting) Beeswax (Wrapper for Hive) Hive EDW on (10’s, 100’s, 1000’s servers) HiveQL (Based on Ansi SQL) Reporting Tools/Business Analytics Name Node Data Nodes Zookeeper (Distributed Configuration Management) Cloudera/MapR/Amazon/Hortonworks …
- 10. HDFS
- 13. Cloudera
- 16. Hive
- 18. Questions?