Downloaded 168 times


















































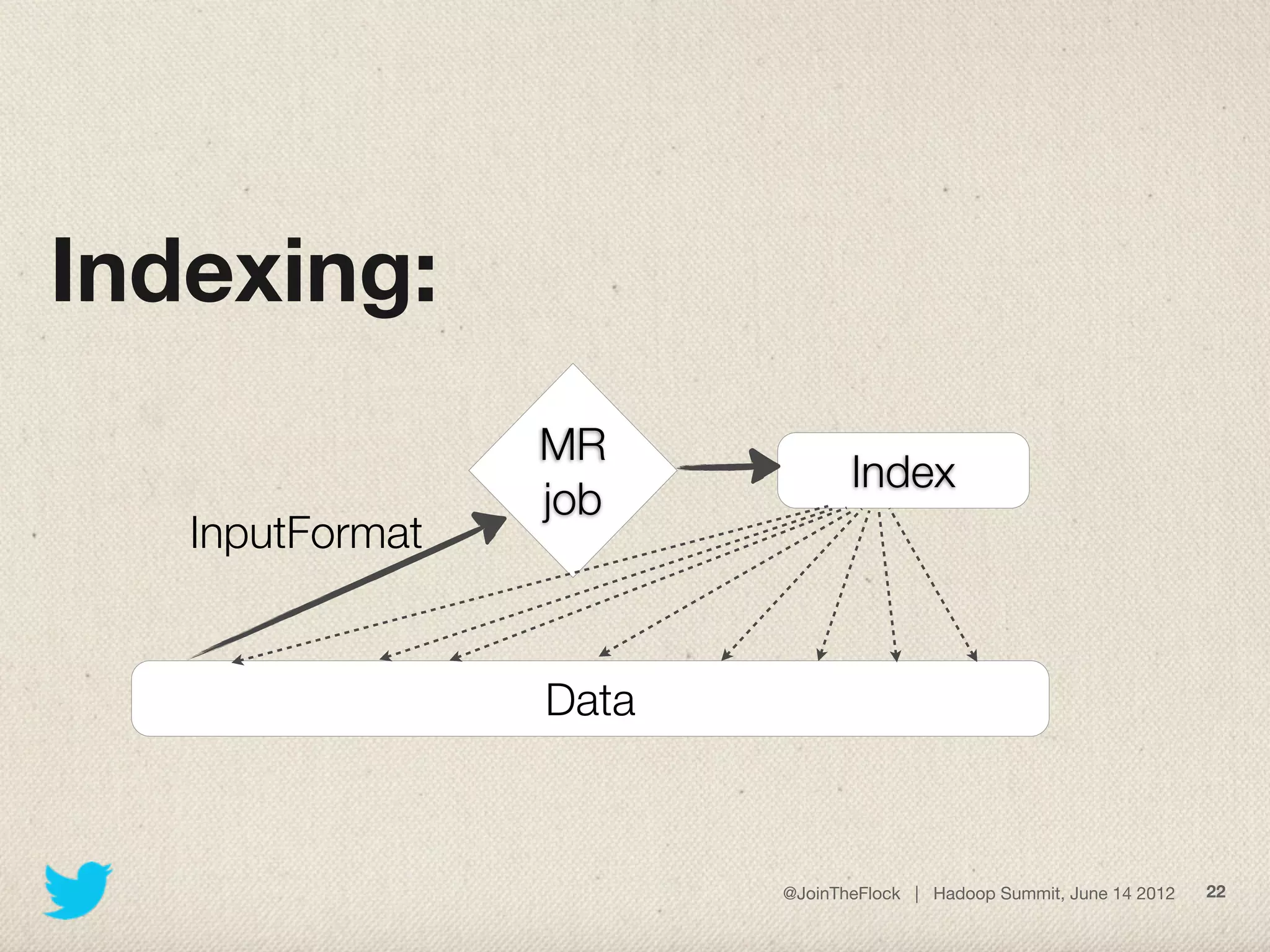




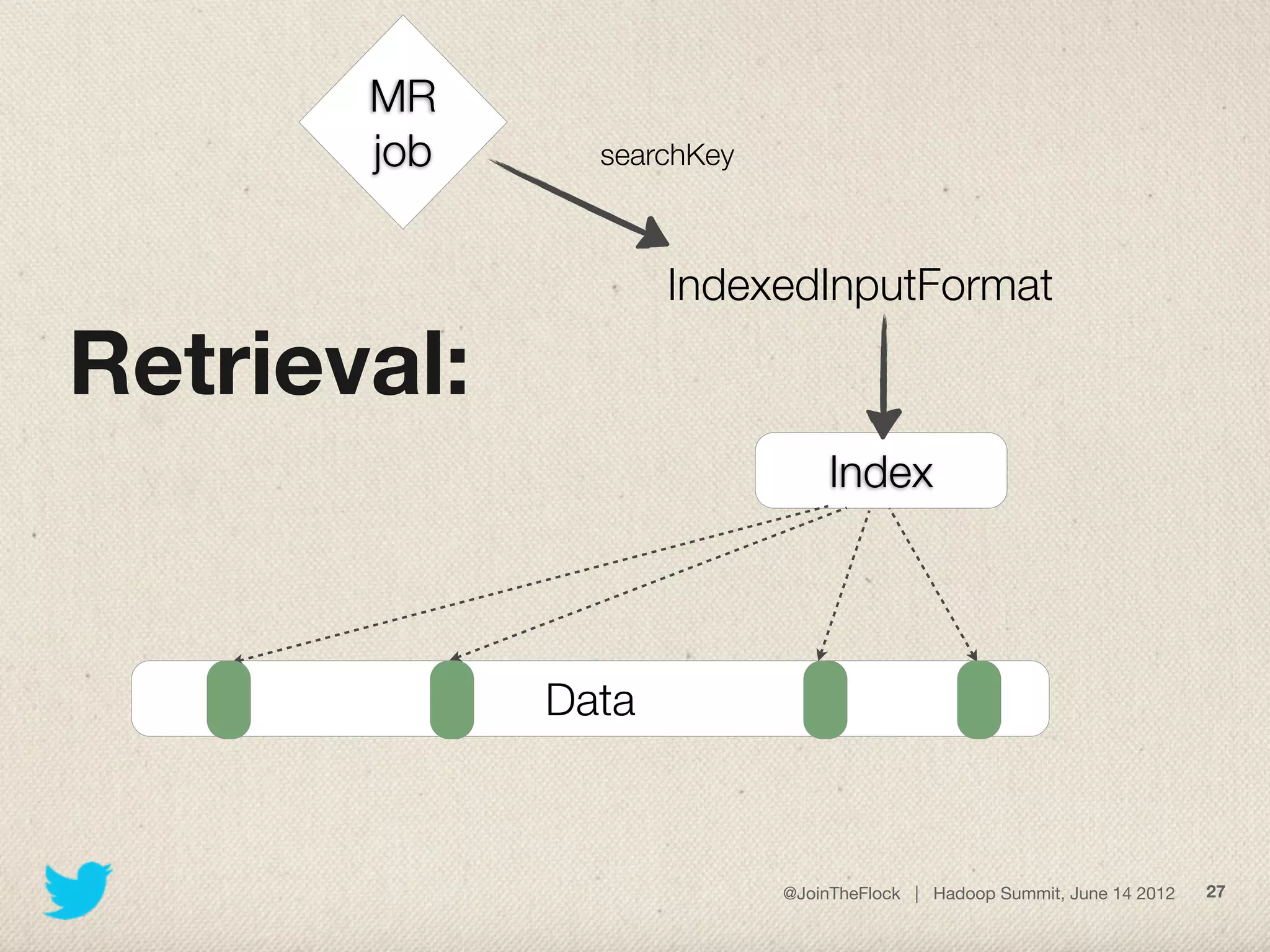




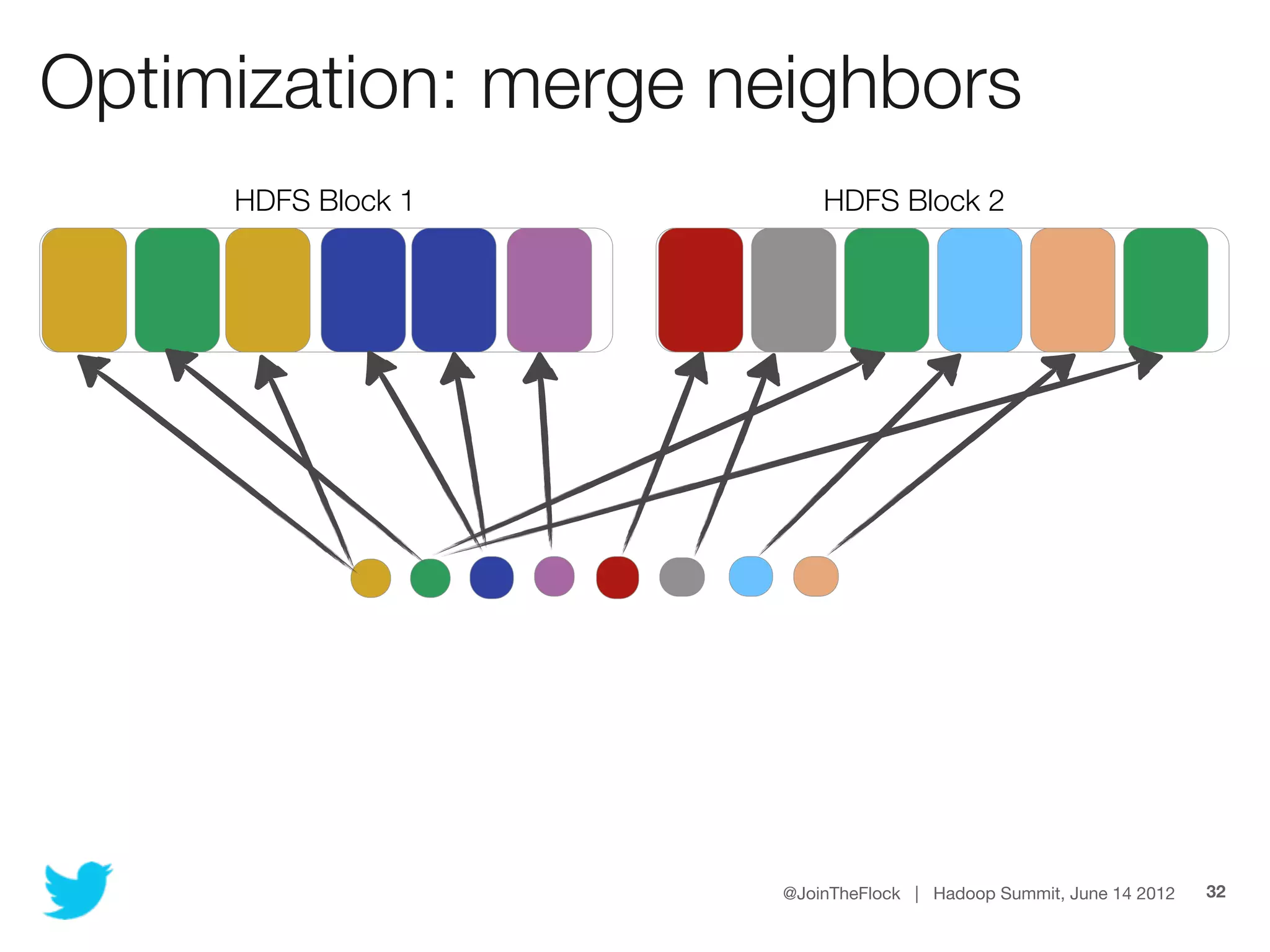
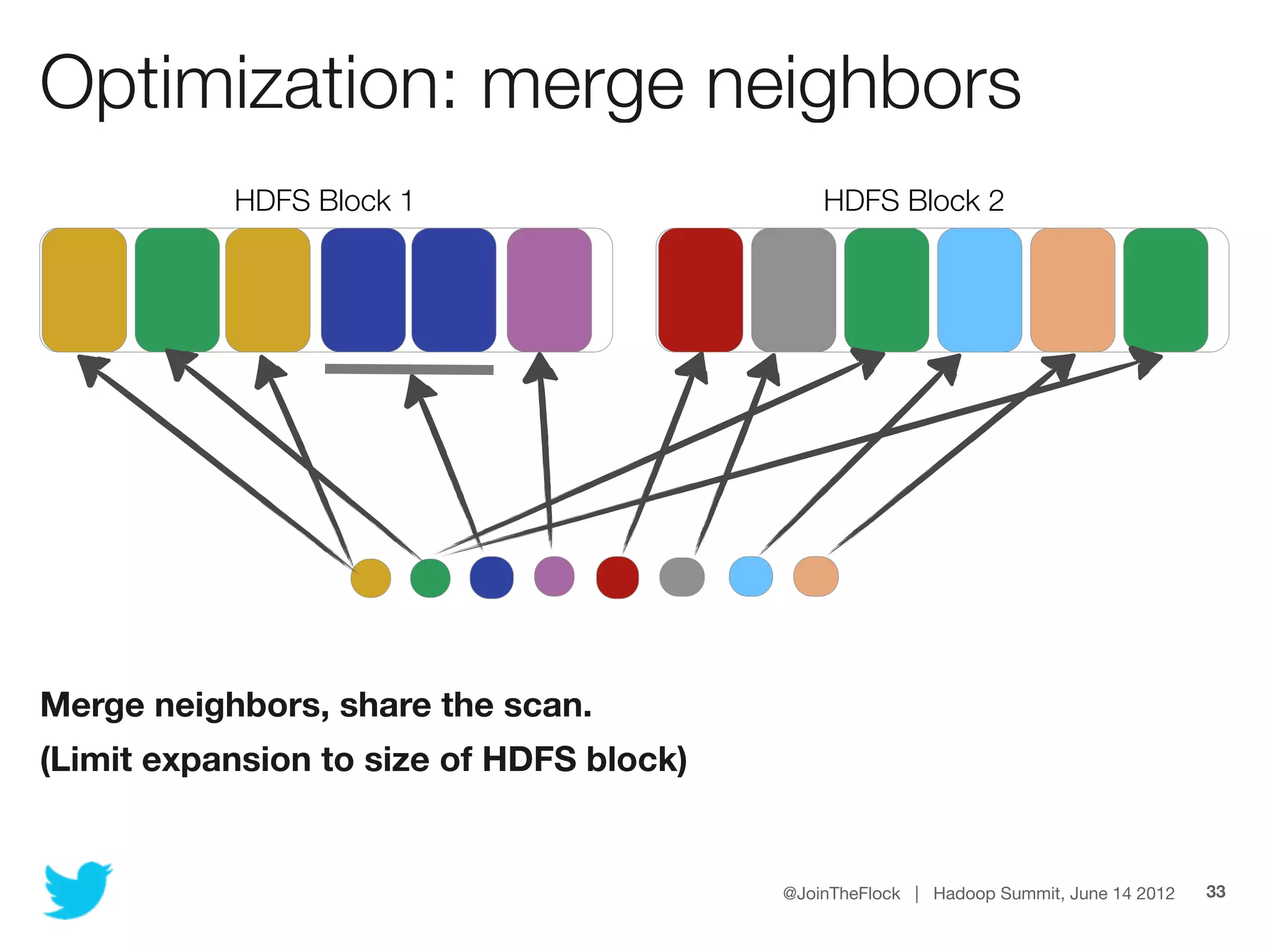
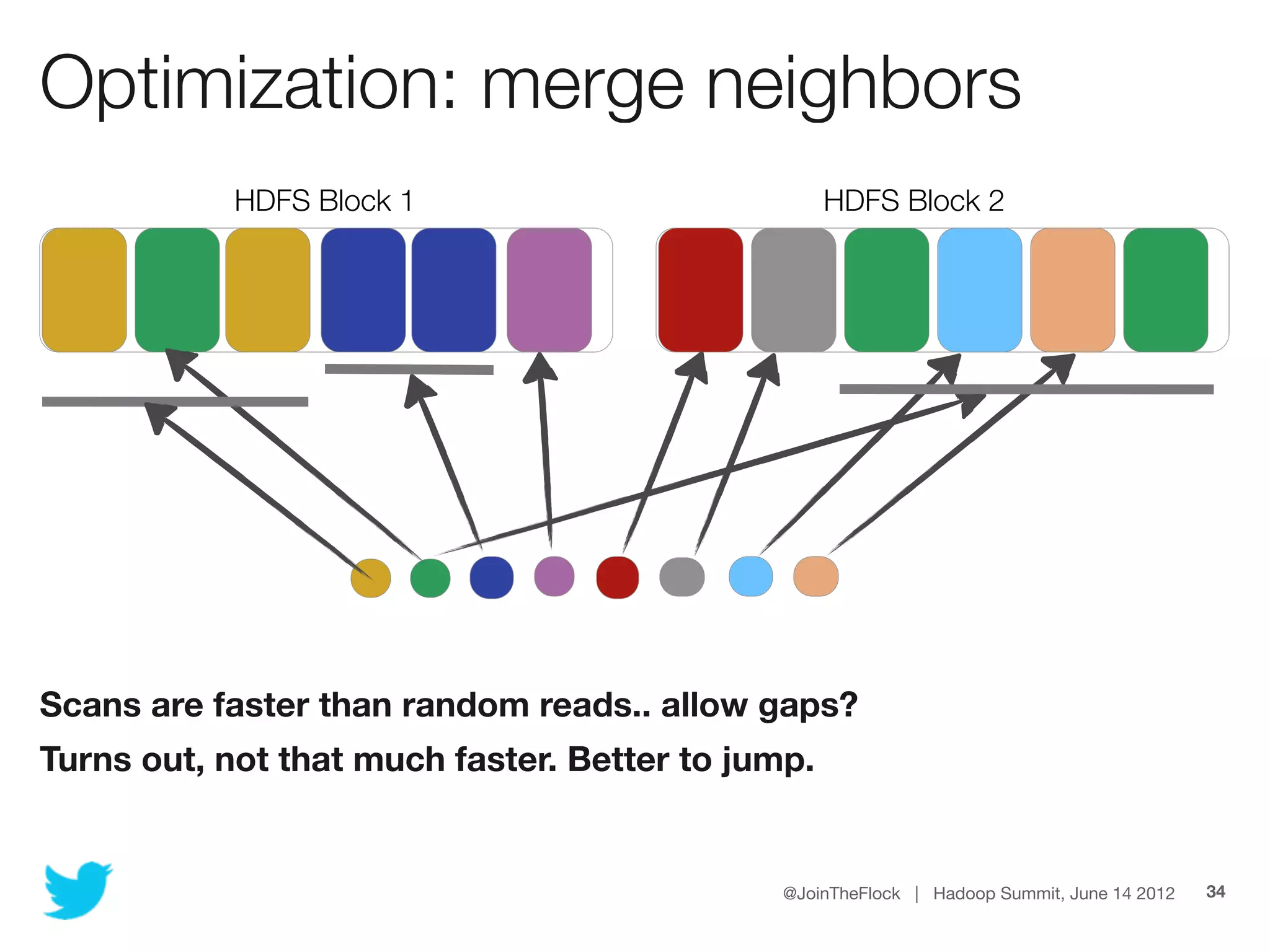
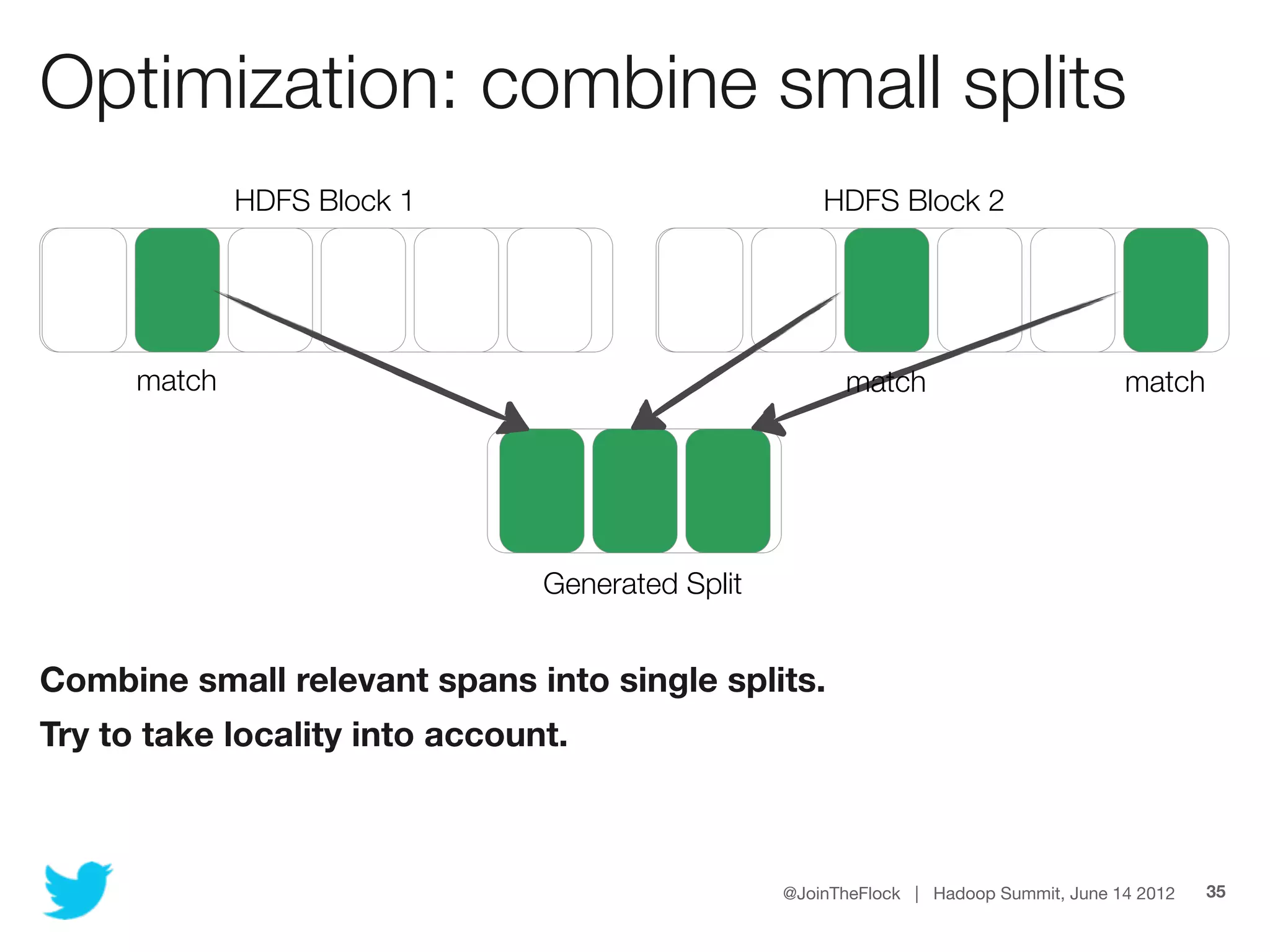
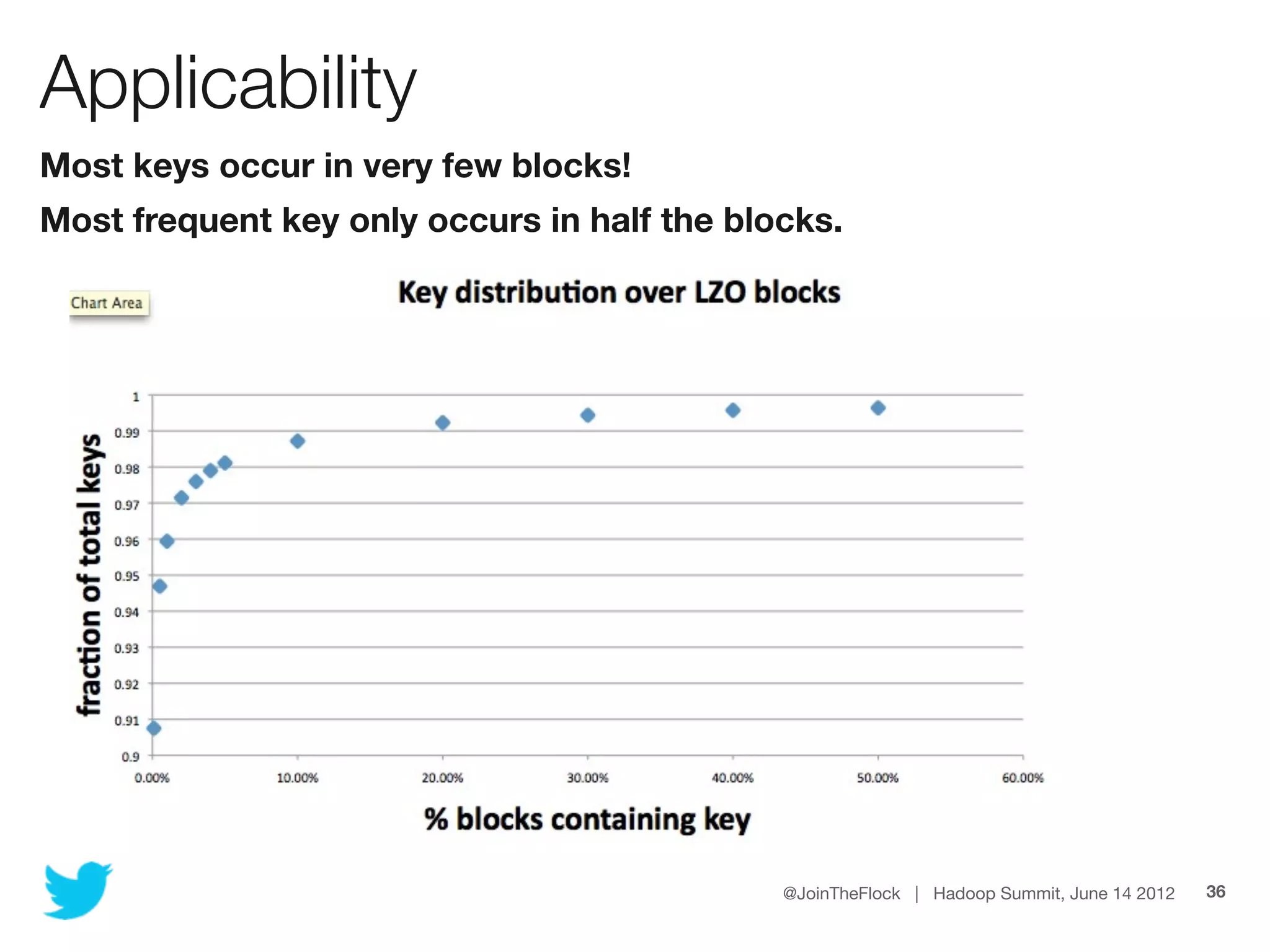









This document discusses flexible indexing in Hadoop. It describes how Twitter uses Elephant-Twin, an open source library they developed, to create indexes at the block level or record level in Hadoop. Elephant-Twin allows minimal changes to jobs/scripts, indexes data without copying it, supports post-factum indexing, and indexes can be used to efficiently retrieve relevant data through an IndexedInputFormat.









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







