Download as PPS, PPTX
![Big Data MapReduce vs. RDBMS Arjen P. de Vries [email_address] Centrum Wiskunde & Informatica Delft University of Technology Spinque B.V.](https://image.slidesharecdn.com/bigdata-mr-rdbms-111201055133-phpapp01/75/Big-data-hadoop-rdbms-1-2048.jpg)







































![Information Science “ Search for the fundamental knowledge which will allow us to postulate and utilize the most efficient combination of [human and machine] resources” M.E. Senko. Information systems: records, relations, sets, entities, and things. Information systems , 1(1):3–13, 1975.](https://image.slidesharecdn.com/bigdata-mr-rdbms-111201055133-phpapp01/75/Big-data-hadoop-rdbms-44-2048.jpg)


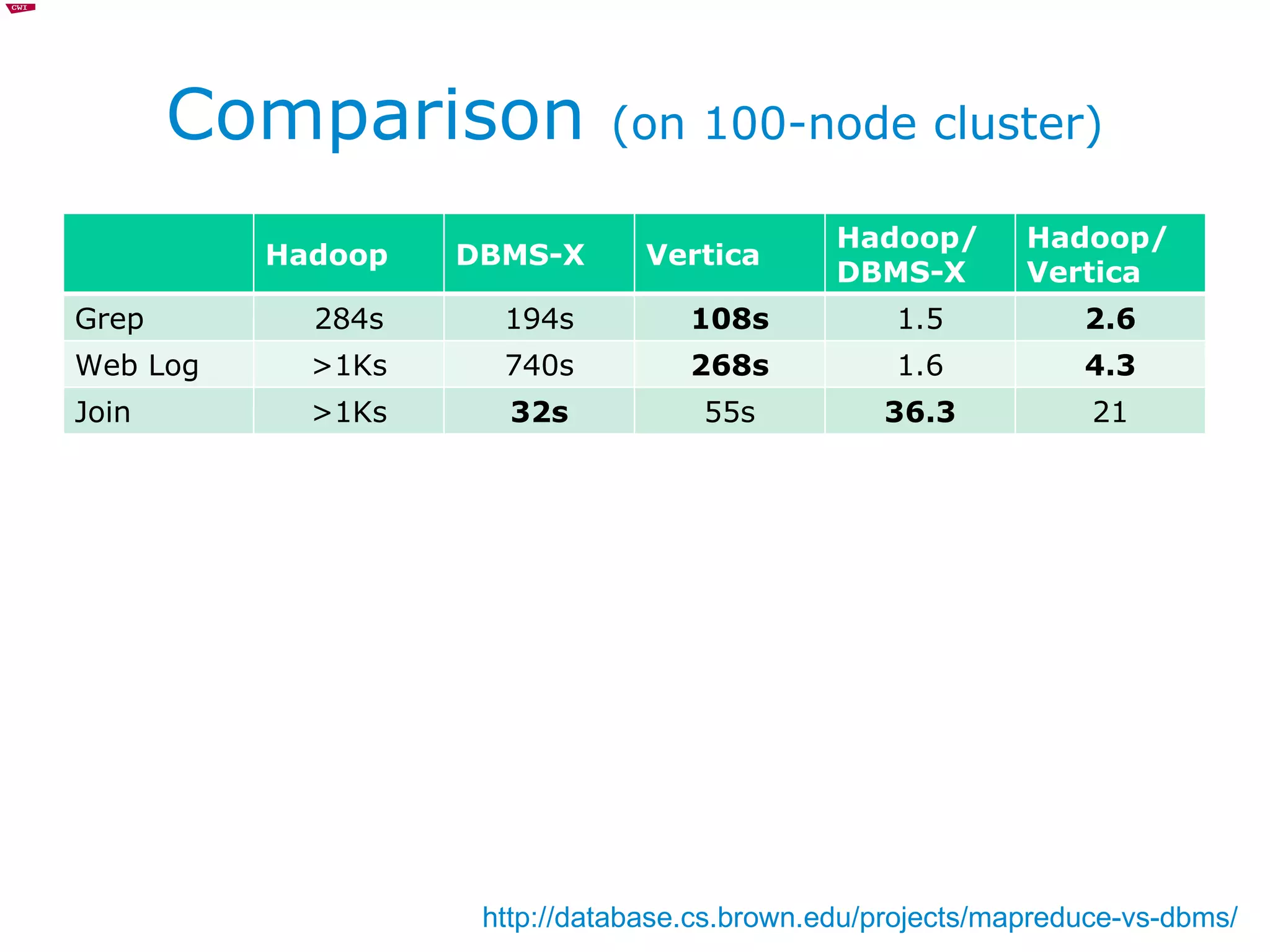
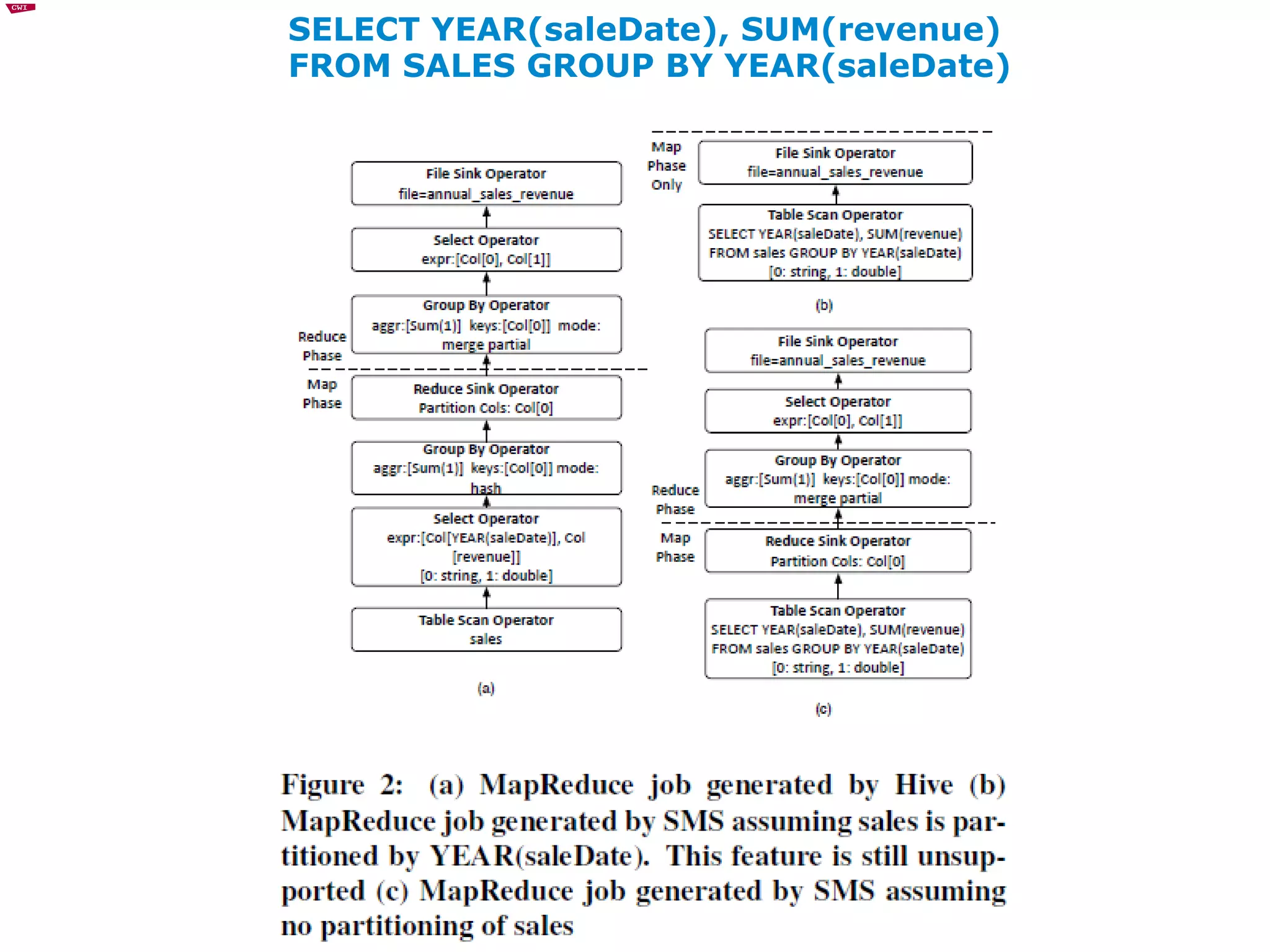
The document discusses and compares MapReduce and relational database management systems (RDBMS) for large-scale data processing. It describes several hybrid approaches that attempt to combine the scalability of MapReduce with the query optimization and efficiency of parallel RDBMS. HadoopDB is highlighted as a system that uses Hadoop for communication and data distribution across nodes running PostgreSQL for query execution. Performance evaluations show hybrid systems can outperform pure MapReduce but may still lag specialized parallel databases.


























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















