Download as PDF, PPTX























![MaxOutputClasses 1
[System Global Accuracy]0.5095676824946846
[System Globel Recall]0.2686846038863976
TP{star-wars}59
FP{star-wars}75
FN{star-wars}7
[Precision (of predicted)]{star-wars}0.44029850746268656
[Recall for class)]{star-wars}0.8939393939393939
TP{harry-potter}147
FP{harry-potter}137
FN{harry-potter}3
[Precision (of predicted)]{harry-potter}0.5176056338028169
[Recall for class]{harry-potter}0.98
Solr Classification - Demo - Full Dataset](https://image.slidesharecdn.com/apacheconeuluceneandsolrclassification-161118190808-210827162650/75/Apache-Lucene-Solr-Document-Classification-28-2048.jpg)
![MaxOutputClasses 5
[System Global Accuracy]0.20481927710843373
[System Globel Recall]0.5399850523168909
TP{star-wars}66
FP{star-wars}400
FN{star-wars}0
[Precision (of predicted)]{star-wars}0.14163090128755365
[Recall for class)]{star-wars}1.0
TP{harry-potter}150
FP{harry-potter}584
FN{harry-potter}0
[Precision (of predicted)]{harry-potter}0.20435967302452315
[Recall for class]{harry-potter}1.0
Solr Classification - Demo - Full Dataset](https://image.slidesharecdn.com/apacheconeuluceneandsolrclassification-161118190808-210827162650/75/Apache-Lucene-Solr-Document-Classification-29-2048.jpg)
![MaxOutputClasses 1
[System Global Accuracy]0.9907407407407407
[System Globel Recall]0.6750788643533123
TP{star-wars}64
FP{star-wars}0
FN{star-wars}2
[Precision (of predicted)]{star-wars}1.0
[Recall for class)]{star-wars}0.9696969696969697
TP{harry-potter}150
FP{harry-potter}2
FN{harry-potter}0
[Precision (of predicted)]{harry-potter}0.9868421052631579
[Recall for class]{harry-potter}1.0
Solr Classification - Demo - Partial Dataset](https://image.slidesharecdn.com/apacheconeuluceneandsolrclassification-161118190808-210827162650/75/Apache-Lucene-Solr-Document-Classification-30-2048.jpg)
![MaxOutputClasses 5
[System Global Accuracy]0.24259259259259258
[System Globel Recall]0.8264984227129337
TP{star-wars}66
FP{star-wars}52
FN{star-wars}0
[Precision (of predicted)]{star-wars}0.559322033898305
[Recall for class)]{star-wars}1.0
TP{harry-potter}150
FP{harry-potter}48
FN{harry-potter}0
[Precision (of predicted)]{harry-potter}0.7575757575757576
[Recall for class]{harry-potter}1.0
Solr Classification - Demo - Partial Dataset](https://image.slidesharecdn.com/apacheconeuluceneandsolrclassification-161118190808-210827162650/75/Apache-Lucene-Solr-Document-Classification-31-2048.jpg)







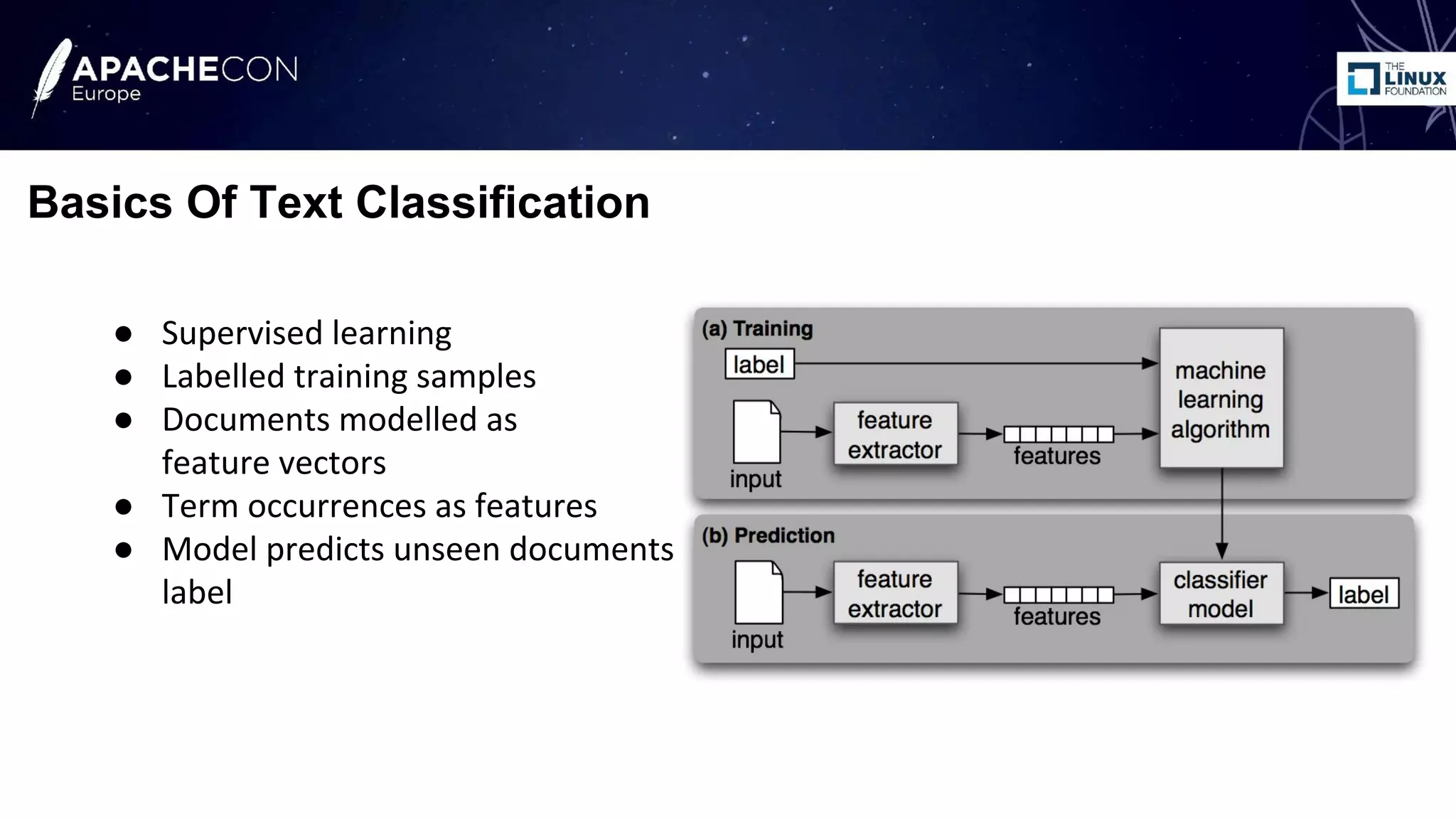
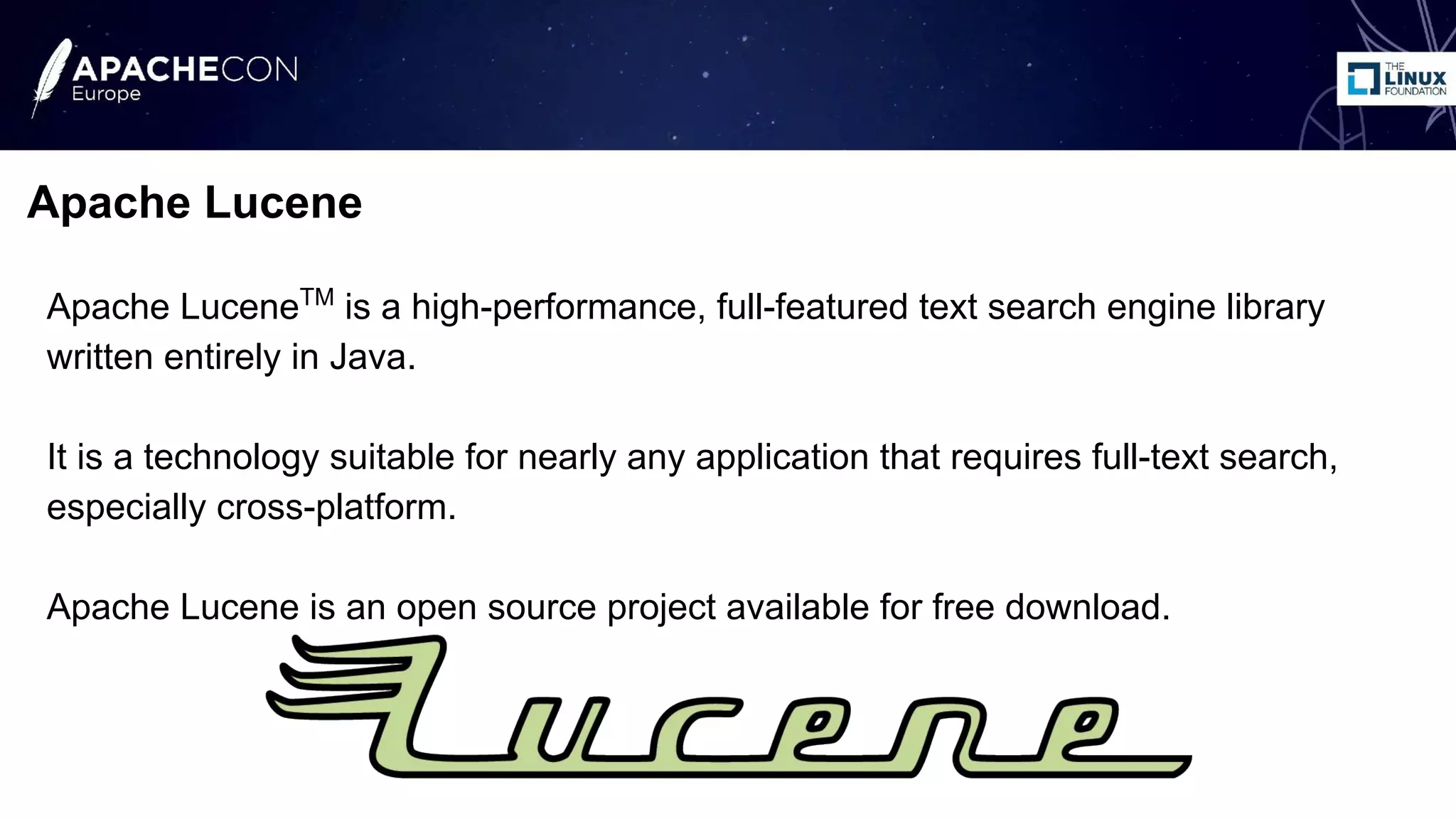
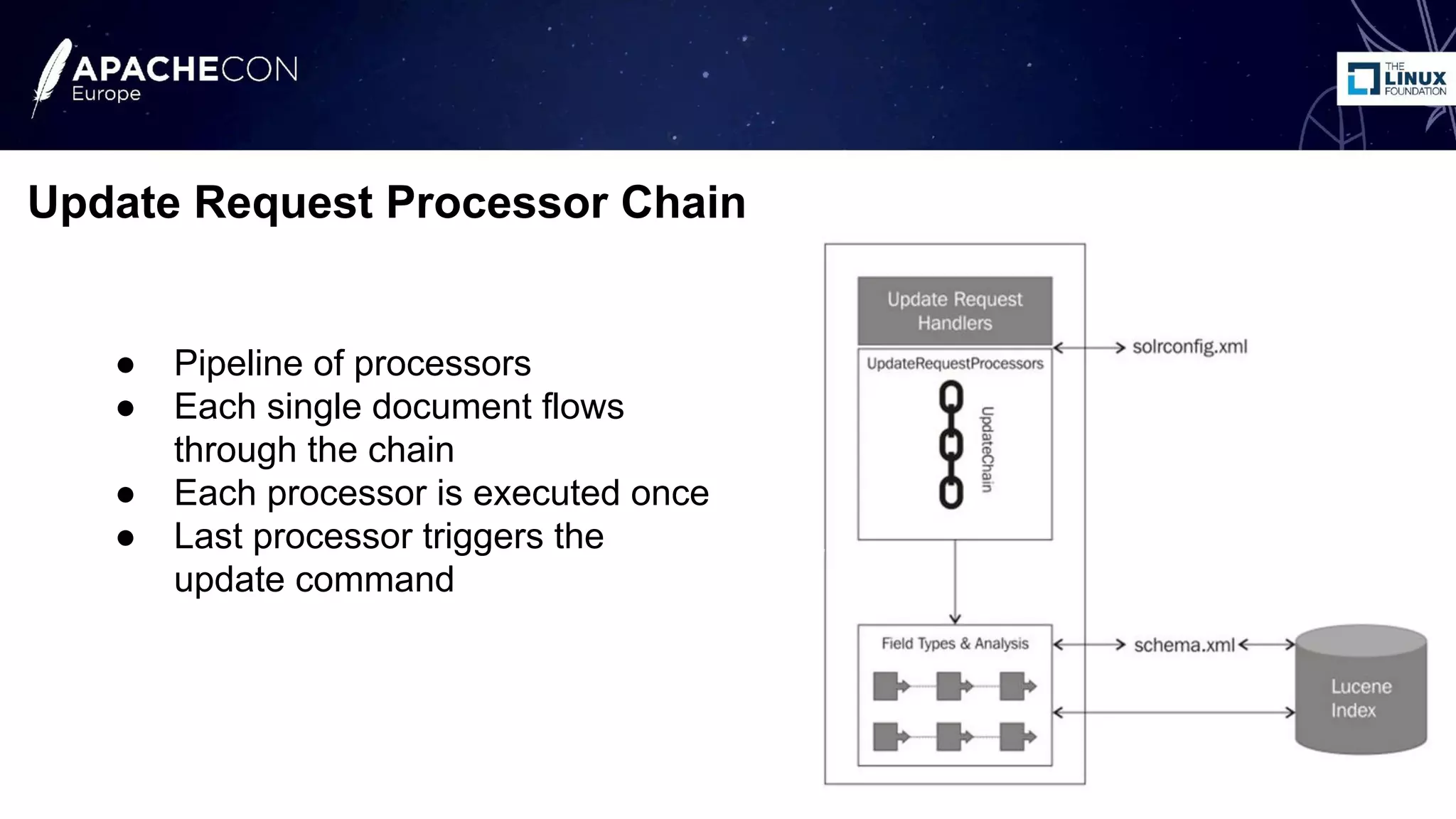
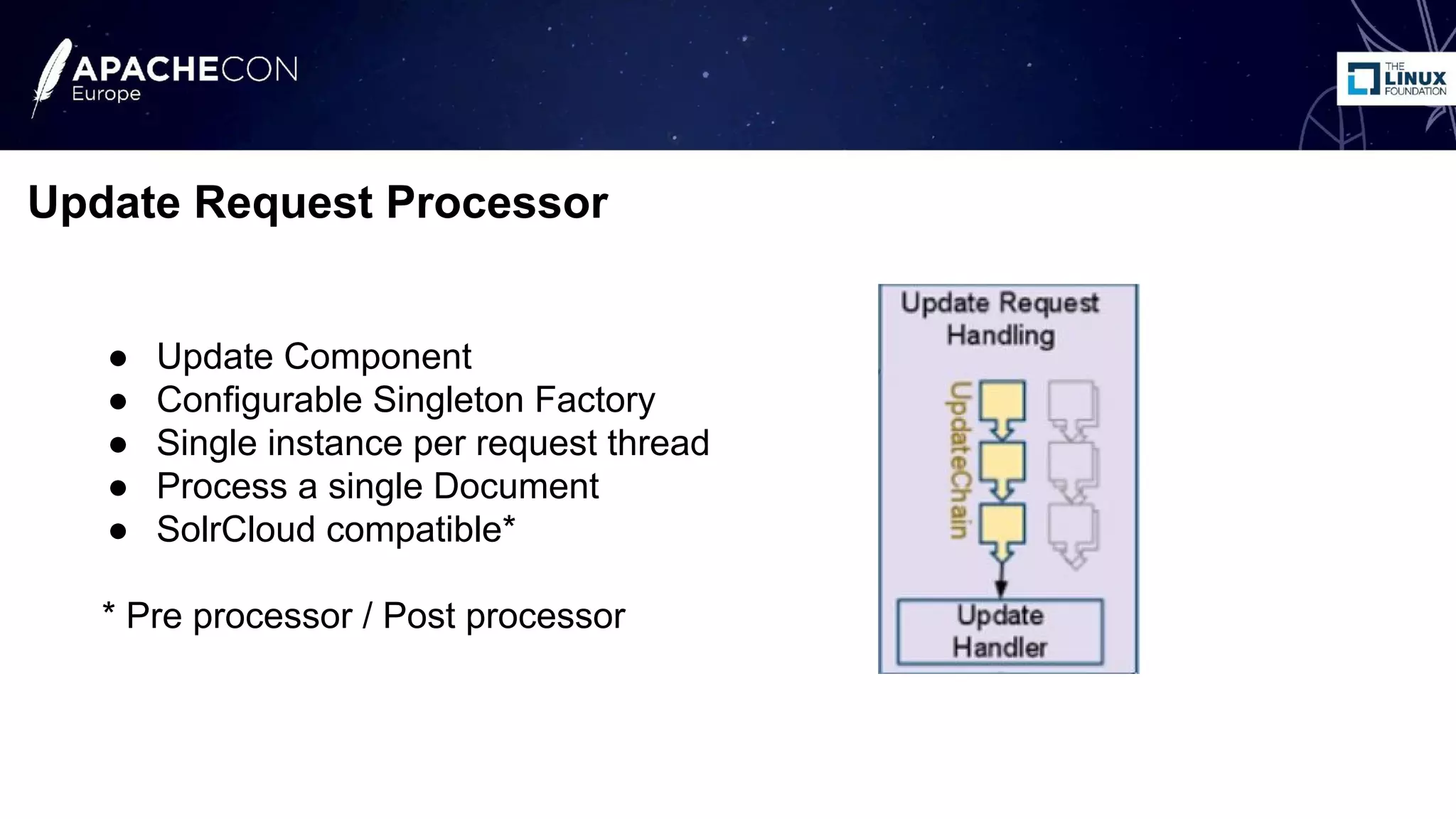
The document discusses the use of Apache Lucene and Solr for text classification, highlighting the basics of classification, real-world use cases, and the implementation of document classification through Solr's indexing features. It covers techniques such as k-nearest neighbors (KNN) and Naive Bayes classifiers, detailing the configuration needed for classification and system evaluation metrics using a sample dataset. Future work and possible extensions for improving classification effectiveness are also mentioned.























































































