Download as PDF, PPTX





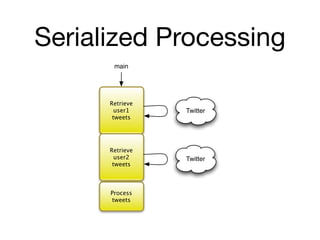













![Actor Example
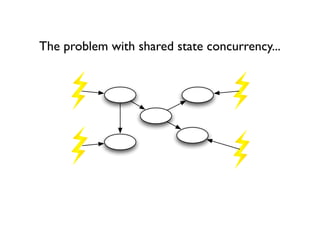
class Player extends AbstractPooledActor {
String name
def random = new Random()
void act() {
loop {
react {
// player replies with a random move
reply
Move.values()[random.nextInt(Move.values().length)]
}
}
}
}](https://image.slidesharecdn.com/groovyconcurrency-100721131414-phpapp01/85/Groovy-concurrency-33-320.jpg)

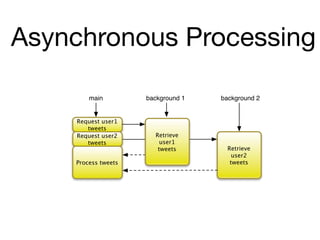
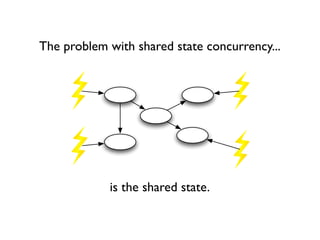
![Simple example...
• Use generics to specify data type of wrapped data
• Pass initial value on construction
• Send function to modify state
• Read value by accessing val
def stuff = new Agent<List>([])
// thread 1
stuff.send( {it.add(“pizza”)} )
// thread 2
stuff.send( {it.add(“nachos”)} )
println stuff.val](https://image.slidesharecdn.com/groovyconcurrency-100721131414-phpapp01/85/Groovy-concurrency-35-320.jpg)
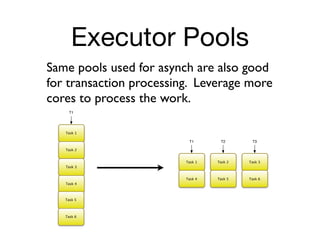
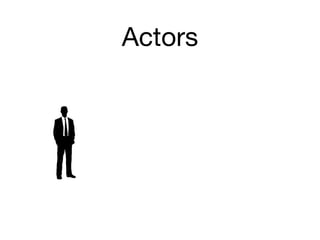
![class BankAccount extends Agent<Long> {
def BankAccount() { super(0) }
private def deposit(long deposit)
{ data += deposit }
private def withdraw(long deposit)
{ data -= deposit }
}
final BankAccount acct = new BankAccount()
final Thread atm2 = Thread.start {
acct << { withdraw 200 }
}
final Thread atm1 = Thread.start {
acct << { deposit 500 }
}
[atm1,atm2]*.join()
println "Final balance: ${ acct.val }"](https://image.slidesharecdn.com/groovyconcurrency-100721131414-phpapp01/85/Groovy-concurrency-36-320.jpg)







The document discusses the GPars library for Groovy, which facilitates concurrency through various patterns such as asynchronous processing, actor messaging, and dataflow variables. It emphasizes the importance of managing mutable state, utilizing executor pools for CPU-bound tasks, and the design principles for ensuring thread safety. Additionally, it explores advanced concurrency models like actors and agents while providing practical examples and usage scenarios.

























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





