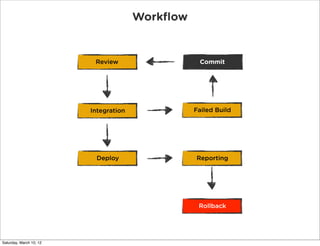
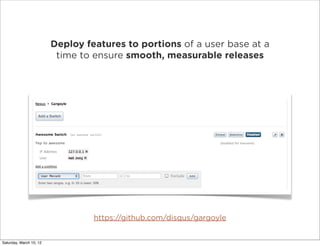
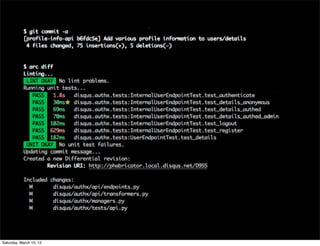
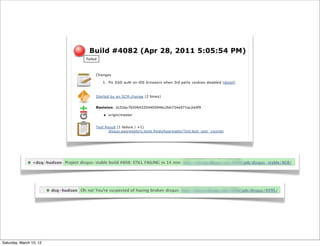
The document discusses continuous deployment and practices at Disqus for releasing code frequently. It emphasizes shipping code as soon as it is ready after it has been reviewed, passes automated tests, and some level of QA. It also discusses keeping development simple, integrating code changes through automated testing, using metrics for reporting, and doing progressive rollouts of new features to subsets of users.















![SWITCHES = {
# enable my_feature for 50%
'my_feature': range(0, 50),
}
def is_active(switch):
try:
pct_range = SWITCHES[switch]
except KeyError:
return False
ip_hash = sum([int(x) for x
in ip_address.split('.')])
return (ip_hash % 100 in pct_range)
Saturday, March 10, 12](https://image.slidesharecdn.com/practicingcontinuousdeployment-120323183643-phpapp02/85/Practicing-Continuous-Deployment-17-320.jpg)
































![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



































































