Download as PDF, PPTX




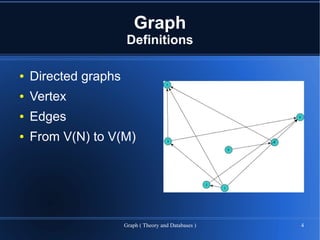










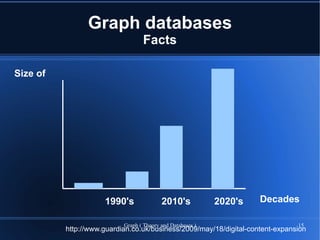
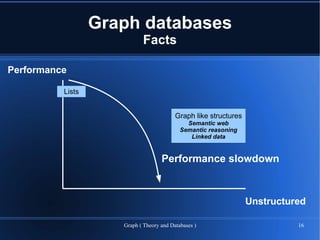
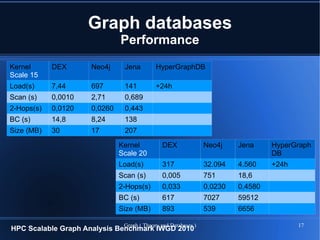



The document provides an overview of graph theory and graph databases, detailing definitions, applications, and performance metrics. It discusses various types of graphs, their uses in fields such as logistics and network analysis, and highlights several graph database vendors. Additionally, it addresses performance comparisons and key features of different graph database systems.
















![[2D3]TurboGraph- Ultrafast graph analystics engine for billion-scale graphs i...](https://cdn.slidesharecdn.com/ss_thumbnails/2d3turbograph-ultrafastgraphanalysticsengineforbillion-scalegraphsinasinglemachine-140929210257-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































































