Downloaded 29 times


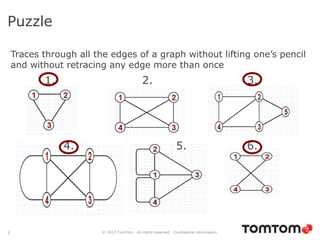
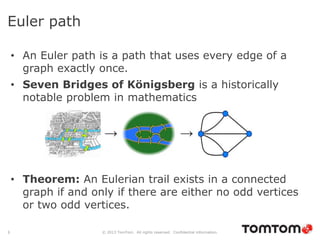
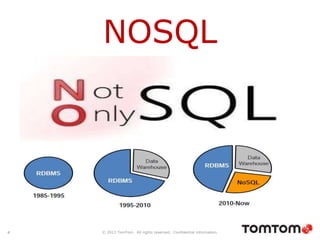
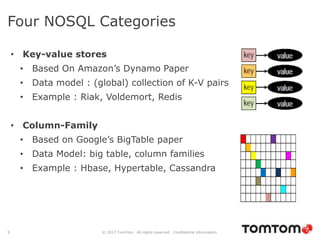
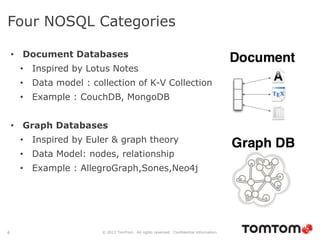

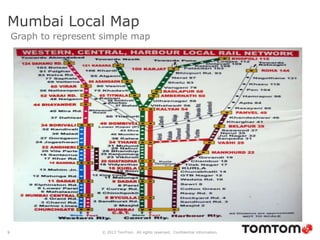
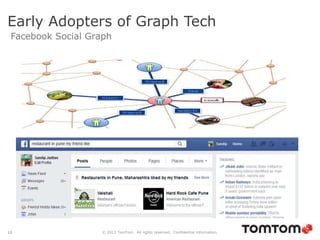


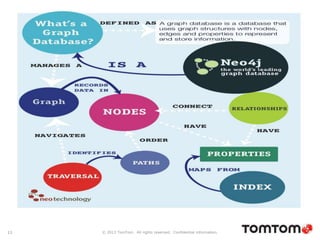


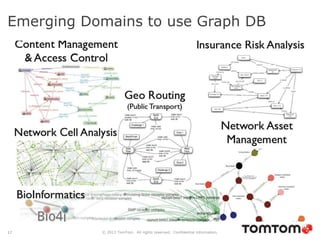
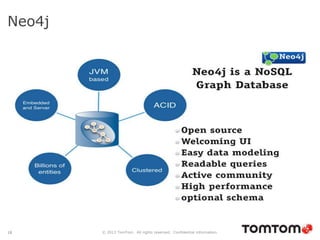

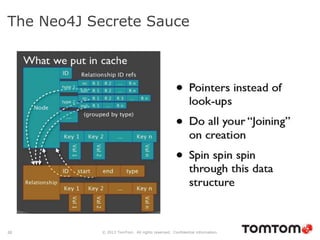
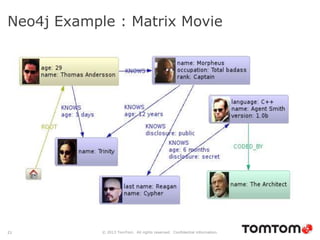




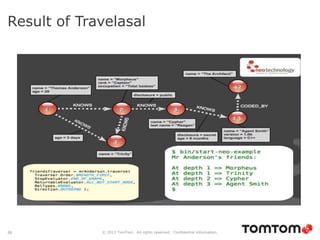
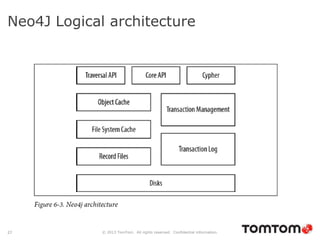


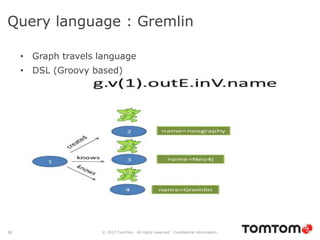




The document discusses graph databases, focusing on Neo4j, and provides an overview of Euler paths and NoSQL database categories, including key-value stores, column-family, document databases, and graph databases. It highlights early adopters of graph technology like Facebook and Google and lists advantages for choosing graph databases, such as improved performance with connected data. Additionally, examples and use cases are mentioned, along with references to query languages like Cypher and Gremlin.



































































